Clear Sky Science · es
Primacía de la ingeniería de características sobre la complejidad arquitectónica para la previsión de demanda intermitente
Por qué importa predecir ventas raras
Tras cada taller de reparación de coches o almacén de repuestos hay un acertijo silencioso: ¿cuántas piezas de baja rotación debe mantenerse en el estante? Estos artículos se venden de forma ocasional e impredecible, pero deben estar disponibles cuando un vehículo se avería. Pedir de más inmoviliza dinero en stock polvoriento; pedir de menos y los clientes esperan mientras las piezas se traen de urgencia. Este artículo aborda ese problema cotidiano pero costoso planteando una pregunta sencilla: ¿es mejor usar modelos predictivos cada vez más complicados, o alimentar los modelos existentes con señales más inteligentes y cuidadosamente diseñadas a partir de los datos?
De largos periodos de nada a picos repentinos
En muchas cadenas de suministro, especialmente en repuestos automotrices, la demanda no es constante como la de la leche o el pan. En su lugar, hay largos periodos de meses sin ventas, interrumpidos por pedidos ocasionales de unas pocas unidades. Los autores analizan más de 56.000 combinaciones concesionario–pieza, que abarcan alrededor de 1,4 millones de registros mensuales, y encuentran que la mayoría de las series son extremadamente escasas: en promedio hay muchos meses con cero ventas por cada mes con venta, y el tamaño de los pedidos varía drásticamente. Métodos estadísticos tradicionales como el enfoque de Croston y sus refinamientos fueron diseñados para esta demanda “activada/desactivada” y ofrecen previsiones estables e interpretables, pero tratan cada pieza de forma aislada y no pueden usar fácilmente información adicional como precios o atributos del producto. En principio, los sistemas modernos de aprendizaje automático pueden usar toda esta información, pero tienden a tener dificultades cuando los datos son en su mayoría ceros y solo ocasionalmente informativos.
Una idea simple: enseñar al modelo lo que realmente importa
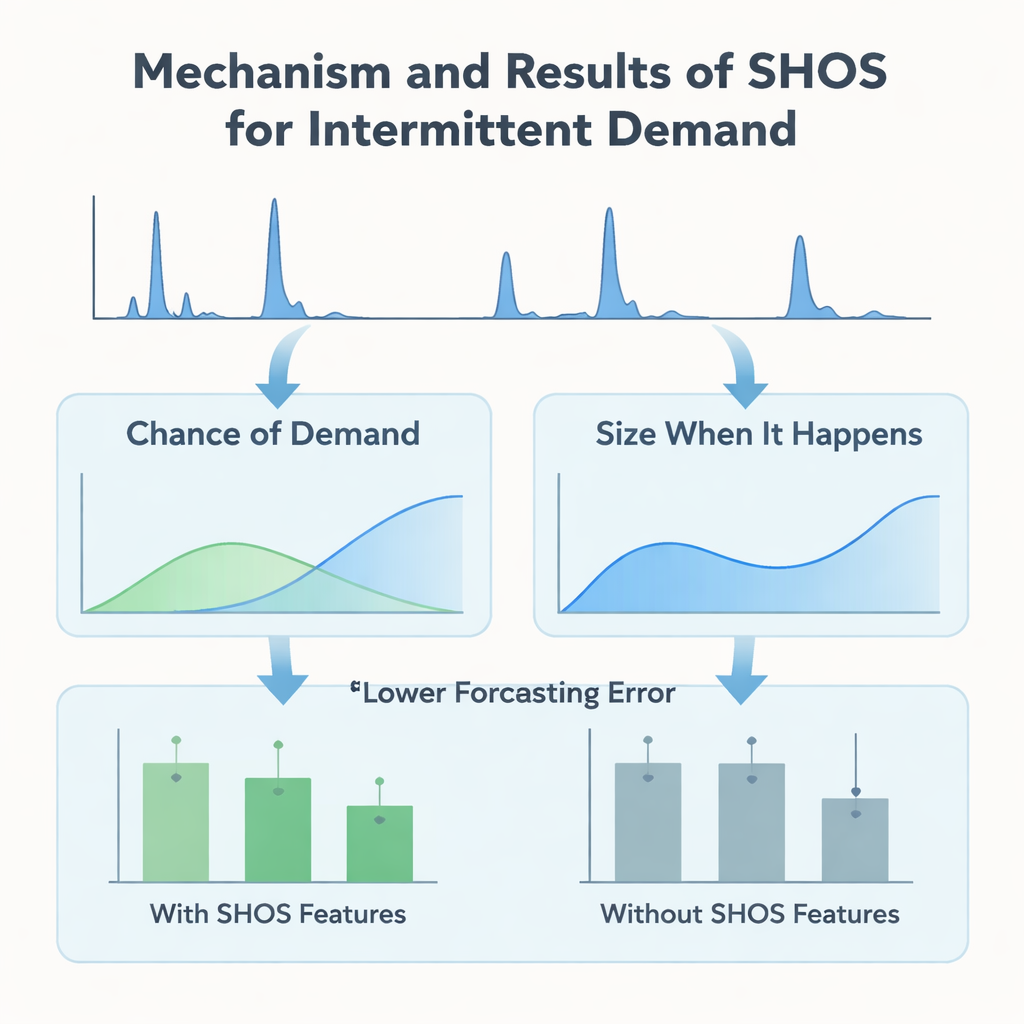
En lugar de diseñar arquitecturas de aprendizaje automático cada vez más intrincadas, los autores se centran en lo que se introduce en el modelo. Presentan el marco Smoothed Hybrid Occurrence–Size (SHOS), una rutina estadística ligera que se ejecuta sobre cada historial de demanda. En cada mes, SHOS produce dos números: la probabilidad estimada de que ocurra cualquier demanda el próximo mes y el tamaño típico de esa demanda si ocurre. Lo hace suavizando cuidadosamente los ceros y no ceros pasados, adaptando su comportamiento para series muy escasas y reaccionando con más rapidez cuando la demanda vuelve de forma repentina tras un largo período de inactividad. Crucialmente, SHOS no es el modelo final de previsión. Sus salidas se convierten en características adicionales de entrada para algoritmos estándar de aprendizaje automático, junto con elementos sencillos como ventas recientes, medias móviles y detalles estáticos del producto.
Poner la calidad de las características por delante de la complejidad del modelo
Para comprobar si este “preprocesado” estadístico realmente ayuda, los investigadores construyen un experimento controlado. Comparan una gama de modelos populares—árboles con impulso por gradiente, bosques aleatorios y métodos lineales—con y sin características SHOS, todos entrenados sobre el mismo panel mensual rellenado con ceros y evaluados mediante un riguroso esquema de ventana rodante que imita el despliegue real. También prueban modelos de “hurdle” más elaborados en dos etapas que predicen por separado si habrá demanda y cuál será su magnitud. En 11 ventanas de validación, añadir características SHOS reduce casi a la mitad el error medio de previsión para los artículos altamente intermitentes y disminuye una métrica empresarial clave, el error porcentual absoluto medio ponderado, en más del 40%. Sorprendentemente, las arquitecturas en dos etapas, a pesar de ser más complejas y estar adaptadas a este tipo de datos, no superan a un regresor único y sencillo que simplemente incorpora las señales SHOS.
Ver cómo el modelo toma sus decisiones
El equipo va más allá de la precisión general e investiga cómo los modelos usan realmente la información que se les da. Usando SHAP, una herramienta estándar para interpretar predicciones de aprendizaje automático, muestran que las características basadas en SHOS—“probabilidad de demanda” y “tamaño cuando ocurre”—se encuentran consistentemente entre las entradas más influyentes. Durante largos periodos de demanda nula, una baja probabilidad SHOS empuja las previsiones hacia cero, evitando acumulaciones de stock espurias. Cuando aparece un estallido de demanda tras una sequía, un ajuste de recencia en SHOS aumenta rápidamente las estimaciones de probabilidad y tamaño, permitiendo al modelo responder sin sobrerreaccionar ante un solo pico. Estos comportamientos se observan tanto en el modelo simple de una sola etapa como en las versiones más complejas de tipo hurdle, subrayando que la ganancia principal proviene de la calidad de las señales, no de trucos arquitectónicos.
Qué significa esto para las decisiones de inventario cotidianas
Para los profesionales que intentan mantener las piezas adecuadas en el estante, el mensaje es práctico y tranquilizador. El estudio muestra que características diseñadas con cuidado y fundamentadas estadísticamente pueden ofrecer grandes mejoras en la previsión de ventas raras e irregulares sin recurrir a configuraciones de modelos frágiles y difíciles de mantener. Un árbol con impulso por gradiente modesto y bien ajustado equipado con características SHOS supera o iguala a canalizaciones más elaboradas, al tiempo que sigue siendo más fácil de desplegar y supervisar a escala de decenas de miles de artículos. En términos sencillos, alimentar tu sistema de previsión con mejores resúmenes sobre la frecuencia y la magnitud de los pedidos de los clientes puede importar más que actualizar al último algoritmo más complejo. Este énfasis en bloques de construcción simples e interpretables hace que el enfoque sea atractivo para cadenas de suministro a gran escala del mundo real y sugiere que estrategias similares centradas en las características podrían ser rentables en otras industrias que afrontan demanda intermitente.
Cita: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Palabras clave: demanda intermitente, predicción de repuestos, ingeniería de características, analítica de la cadena de suministro, aprendizaje automático