Clear Sky Science · es
Faster R-CNN adaptativo al dominio para la identificación de falta de EPI en obras a partir de imágenes con cámaras corporales y generales
Por qué siguen pasando desapercibidos los equipos de seguridad
Cascos, chalecos, mascarillas, guantes y calzado resistente deberían ser innegociables en las obras, pero aún así se producen omisiones—y pueden ser mortales. Muchos proyectos recurren ahora a cámaras e inteligencia artificial para detectar trabajadores sin el equipo requerido, pero estos sistemas tienen dificultades porque las infracciones reales son raras y difíciles de capturar en vídeo. Este estudio explora una forma de entrenar detectores más inteligentes tomando ejemplos de fotos cotidianas, lo que hace que las comprobaciones automáticas de seguridad sean más fiables sin tener que esperar a que se acumulen accidentes o infracciones.
Convertir fotos corrientes en lecciones de seguridad
La idea central es simple: las personas en espacios públicos u oficinas rara vez llevan equipo de obra, por lo que las fotos de esos entornos están llenas de ejemplos de "qué no llevar" en un sitio de trabajo. El desafío es que esas escenas se parecen poco a las reales de obra: fondos, iluminación y ángulos de cámara cambian la apariencia de las personas. El autor trata estos dos mundos como diferentes "dominios": un dominio fuente con abundantes ejemplos de ausencia de EPI procedentes de imágenes generales, y un dominio objetivo con menos pero más realistas imágenes de obra, muchas filmadas desde cámaras montadas en cascos de los trabajadores. El artículo muestra que, alineando cuidadosamente lo que aprende el sistema en ambos dominios, el detector puede identificar la falta de equipo en obras reales con mucha más precisión que si se entrenara solo con datos de construcción.
Cómo el nuevo detector interpreta una escena
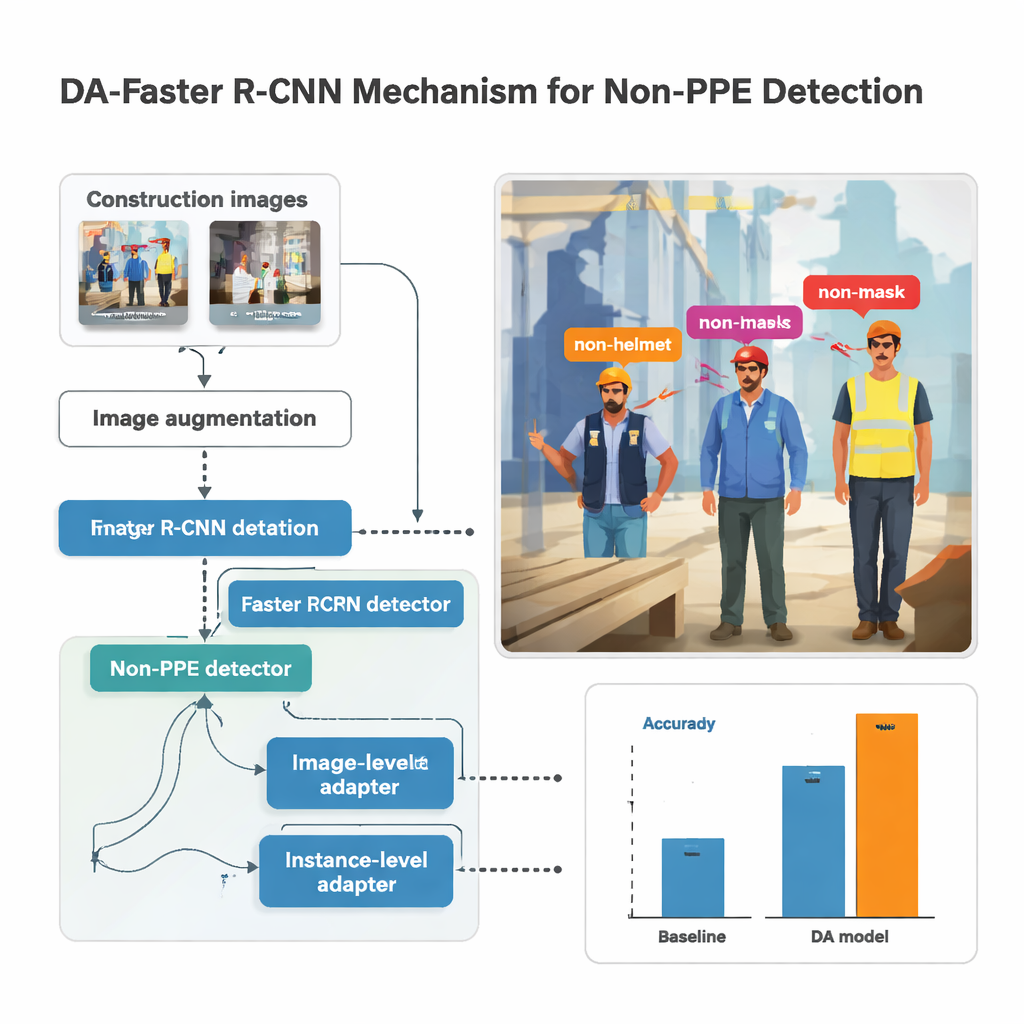
La investigación se basa en un sistema de detección de objetos popular llamado Faster R‑CNN, que analiza una imagen, propone regiones con probabilidad de contener personas o partes del cuerpo y luego clasifica lo que hay dentro de cada caja. Aquí, el detector se entrena para reconocer cinco tipos de ausencia de equipo: sin casco, sin mascarilla, sin guantes, sin chaleco y sin calzado de seguridad. Antes de alimentar las imágenes al modelo, se aplican fuertes aumentos—se aclaran u oscurecen, se rotan, se desenfocan y se distorsionan—para imitar cámaras inestables, luz intensa y ángulos incómodos que son comunes en obras concurridas. Esta variedad sintética ayuda a que el modelo se mantenga estable cuando las grabaciones reales son menos que perfectas, como suele ocurrir con cámaras corporales.
Enseñar al sistema a ignorar el fondo
Mezclar fotos de la calle con tomas de obra no es suficiente; el modelo podría asociar la falta de equipo con aceras en la ciudad en lugar de con las personas. Para evitarlo, el estudio introduce módulos de "adaptación de dominio" que empujan suavemente al sistema a centrarse en las personas y la ropa en lugar de en la escena que las rodea. Un módulo observa la imagen en su conjunto, incentivando a la red a que las fotos de construcción y las no relacionadas produzcan patrones globales similares, pese a las diferencias en iluminación o equipamiento. Otro actúa a nivel de cada persona detectada, garantizando que la firma visual de, por ejemplo, una cabeza sin protección sea similar tanto si aparece en un andamio como en una calle comercial. Estos módulos se entrenan de forma adversarial: un clasificador pequeño intenta adivinar de qué dominio procede una imagen, mientras la red principal aprende a ocultar esa información, manteniendo su atención en el equipo de protección.
Probar el método
El autor reunió un conjunto de datos considerable combinando grabaciones de cámaras corporales de cinco obras en Corea del Sur con varias colecciones de imágenes públicas. Tras etiquetar manualmente cada instancia de falta de casco, mascarilla, guantes, chaleco y calzado de seguridad, el estudio entrenó cientos de modelos con distintas arquitecturas de red y ajustes de parámetros. El mejor rendimiento lo alcanzó una red profunda llamada ResNet‑152 junto con fuertes aumentos de imagen y los módulos de adaptación de dominio. En imágenes de obra no vistas antes, esta configuración logró una precisión media promedio (mAP)—una puntuación global de calidad de detección—de alrededor del 86,8 por ciento, funcionando además a aproximadamente 33 fotogramas por segundo, lo bastante rápida para supervisión casi en tiempo real. En comparación con sistemas supervisados más convencionales, el modelo adaptado mejoró la exactitud hasta en 14 puntos porcentuales, y hasta 39 puntos respecto a una línea base más simple.
Qué significa esto para obras más seguras
Para quienes no son especialistas, la conclusión es que un entrenamiento más inteligente, no solo conjuntos de datos más grandes, puede hacer que la monitorización automática de seguridad sea mucho más fiable. Aprendiendo tanto de fotos cotidianas como de obras reales, y enseñando al sistema a ignorar detalles de fondo poco relevantes, el enfoque propuesto detecta con alta fiabilidad cascos, chalecos, guantes, mascarillas y calzado de seguridad ausentes, incluso cuando las infracciones reales son escasas. Aunque el trabajo actual se centra en cinco tipos de equipo y en un conjunto principal de datos de obra, ofrece un plan práctico para sistemas futuros que podrían rastrear arneses, cuerdas y otros equipos de seguridad en múltiples obras, ayudando a los supervisores a detectar problemas pronto y a mantener a los trabajadores más seguros sin vigilar pantallas todo el día.
Cita: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Palabras clave: seguridad en la construcción, equipos de protección personal, visión por computador, adaptación de dominio, detección de objetos