Clear Sky Science · es
Modelos compactos de aprendizaje profundo para histopatología de colon centrados en el rendimiento y los retos de generalización
Por qué esta investigación importa para pacientes y médicos
El cáncer de colon es uno de los más mortales del mundo, y sin embargo su diagnóstico sigue dependiendo de especialistas que inspeccionan cuidadosamente imágenes microscópicas de tejido, una tarea lenta y sujeta a desacuerdos. Este estudio explora si modelos de inteligencia artificial (IA) muy pequeños y eficientes pueden ayudar a detectar tejido colónico canceroso con la precisión suficiente para ser útiles en clínicas cotidianas, incluidas aquellas con recursos informáticos limitados. También revela una debilidad oculta: modelos que parecen casi perfectos durante su desarrollo pueden fallar estrepitosamente con datos nuevos del mundo real.
Enseñar a los ordenadores a leer imágenes de microscopio
Cuando se toma una biopsia de colon, los patólogos examinan cortes finos y teñidos de tejido bajo el microscopio. El tejido canceroso muestra glándulas deformadas, formas celulares irregulares e invasión de estructuras circundantes, mientras que el tejido sano presenta patrones ordenados y regulares. Los autores usaron una colección pública de 24 000 imágenes digitales de esos cortes, dividida de forma equilibrada entre tejido canceroso (adenocarcinoma de colon) y benigno. Redimensionaron todas las imágenes a un formato pequeño y estándar y aplicaron ajustes realistas —pequeñas rotaciones, volteos, zooms y suaves cambios de color— para imitar la variación natural en cómo se cortan, tiñen y escanean los portadores. Esta preparación cuidadosa ayuda a que los modelos de IA se centren en patrones tisulares significativos en lugar de detalles superficiales como la orientación exacta o el brillo.
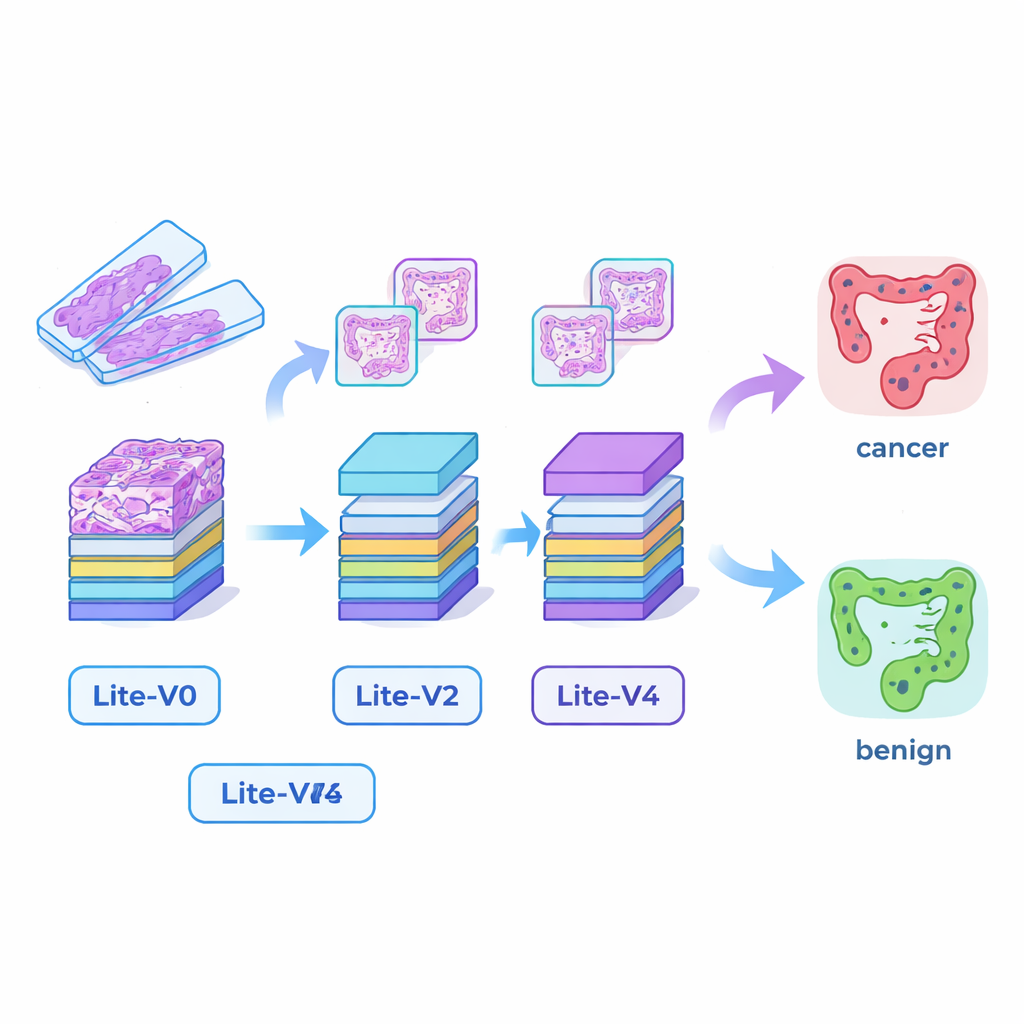
Construir “ojos” de IA pequeños pero capaces
Muchos sistemas de IA médica exitosos dependen de modelos de aprendizaje profundo muy grandes que requieren tarjetas gráficas potentes y mucha memoria, lo que dificulta su despliegue en hospitales pequeños o junto a la cama del paciente. Para salvar esa brecha, los investigadores diseñaron cuatro redes neuronales convolucionales compactas: Lite‑V0, Lite‑V1, Lite‑V2 y Lite‑V4. Cada una analiza los mismos fragmentos de imagen de entrada, pero difieren en el número de capas y filtros que usan para detectar características visuales como bordes, texturas y formas glandulares. Las cuatro comparten un diseño simple y transparente: bloques repetidos de convolución estándar, normalización y pooling, seguidos de una pequeña “cabeza de decisión” que ofrece la probabilidad de tejido canceroso o benigno. El objetivo era ver cuánta precisión se podía obtener con modelos lo bastante pequeños como para funcionar cómodamente en hardware clínico básico.
Puntuaciones impresionantes en el laboratorio
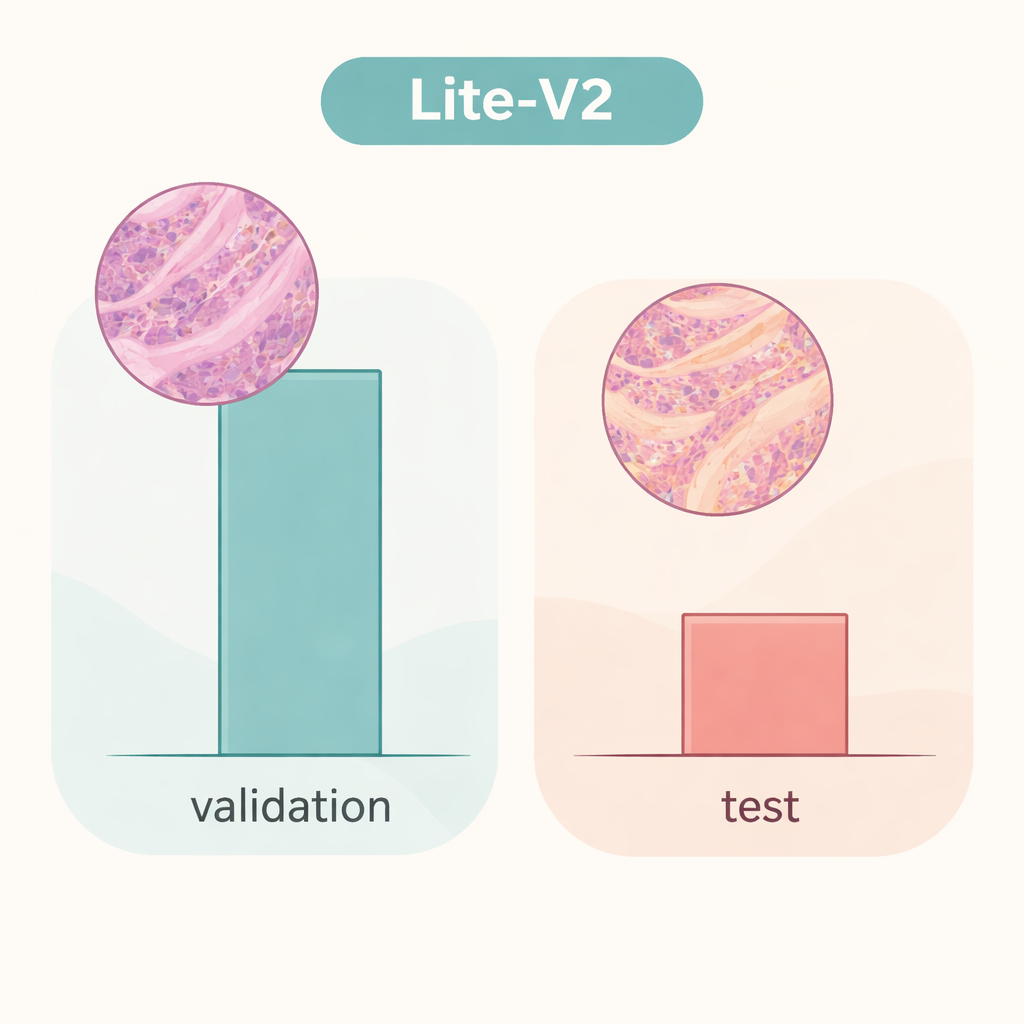
El equipo entrenó y comparó los cuatro modelos usando una partición fija del conjunto de datos, aplicando medidas ampliamente aceptadas: precisión, una puntuación F1 macro que equilibra los errores en ambas clases, matrices de confusión y gráficos diagnósticos como curvas ROC y de precisión‑recuperación. Un modelo de tamaño medio, Lite‑V2, destacó como el mejor rendimiento. A pesar de tener solo alrededor de 1,5 megabytes y aproximadamente 128 000 parámetros entrenables, alcanzó un rendimiento casi impecable en el conjunto de validación interno, con una F1 macro cercana a 0,999 y sensibilidad y especificidad casi perfectas. En otras palabras, dentro de este entorno cuidadosamente preparado, Lite‑V2 podía casi siempre distinguir tejido canceroso de benigno en colon, manteniéndose lo bastante rápido y ligero para usarse en equipos modestos.
Cuando la variación del mundo real rompe el hechizo
Sin embargo, la historia cambia drásticamente cuando el mismo modelo Lite‑V2 se evalúa con un conjunto independiente de imágenes que difieren sutilmente en maneras que imitan portaobjetos de otro laboratorio —lo que los investigadores llaman un “desplazamiento de dominio”. En este conjunto de prueba no visto, la precisión global cayó hasta aproximadamente 50% y la F1 balanceada descendió a cerca de 0,33. El modelo siguió reconociendo muchas muestras cancerosas, pero tuvo graves problemas con el tejido benigno, etiquetando erróneamente una gran fracción como maligno. Esto muestra que la red había aprendido detalles estrechamente ligados a la fuente de datos original —como el estilo de tinción o las características del escáner— en lugar de señales de enfermedad robustas y trasladables. El trabajo subraya que resultados brillantes en validación interna pueden dar una falsa sensación de seguridad si los modelos no se ponen a prueba con datos realmente distintos.
Qué significa esto para futuras herramientas de diagnóstico por IA
Para el lector general, la conclusión es doble. Primero, los sistemas de IA compactos realmente pueden alcanzar un rendimiento a nivel de experto en imágenes de tejido de colon manteniéndose pequeños y eficientes, lo que abre la puerta a cribados más rápidos y apoyo para patólogos sobrecargados. Segundo, y no menos importante, un modelo que parece “perfecto” en su conjunto de origen puede fallar estrepitosamente cuando se enfrenta a imágenes de un hospital nuevo. Los autores sostienen que el trabajo futuro debe concentrarse en hacer que estos modelos ligeros sean robustos frente a cambios en tinciones, escáneres y poblaciones de pacientes —utilizando estrategias como entrenamiento robusto a tinciones, adaptación de dominio y conjuntos de datos multicéntricos más amplios. Hasta entonces, la IA debe verse como un asistente prometedor más que como un decisor autónomo en el diagnóstico del cáncer.
Cita: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Palabras clave: cáncer de colon, histopatología, aprendizaje profundo, CNN ligera, desplazamiento de dominio