Clear Sky Science · es
Predicción de proteínas asociadas a la raíz usando un modelo de lenguaje proteico y redes convolucionales de hipergráficas
Por qué importan las raíces y sus ayudantes ocultos
Cuando pensamos en mantener los cultivos sanos, solemos imaginar hojas y frutos. Pero gran parte del éxito de una planta ocurre fuera de la vista, en el suelo. Allí, proteínas especiales asociadas a la raíz ayudan a las plantas a absorber agua y nutrientes y a enfrentarse a estrés como la sequía o suelos pobres. Identificar estas proteínas cruciales solo con experimentos de laboratorio es lento y caro. Este estudio presenta un modelo informático potente, llamado Hypergraph-Root, que puede escanear rápidamente secuencias de proteínas y predecir cuáles son probablemente asociadas a la raíz, ofreciendo una vía más rápida hacia cultivos más resistentes y mejores cosechas.
Obreros ocultos en el suelo
Las raíces de las plantas hacen más que anclar la planta al suelo. Están continuamente detectando su entorno, absorbiendo minerales y comunicándose con microbios del suelo. Las proteínas asociadas a la raíz son centrales en todo esto, y determinan cómo crecen las raíces, cómo responden al calor, la sequía o la falta de nutrientes, y cómo interactúan con microbios beneficiosos. Dado que estas proteínas influyen fuertemente en el rendimiento y la resiliencia, importan a agricultores y mejoradores aunque nunca las vean directamente. Sin embargo, muchas de estas proteínas siguen sin descubrirse, en gran parte porque los métodos tradicionales—como la proteómica y los estudios de expresión génica—requieren instrumentos costosos, análisis complejos y experimentos laboriosos.
Convertir secuencias de proteínas en pistas
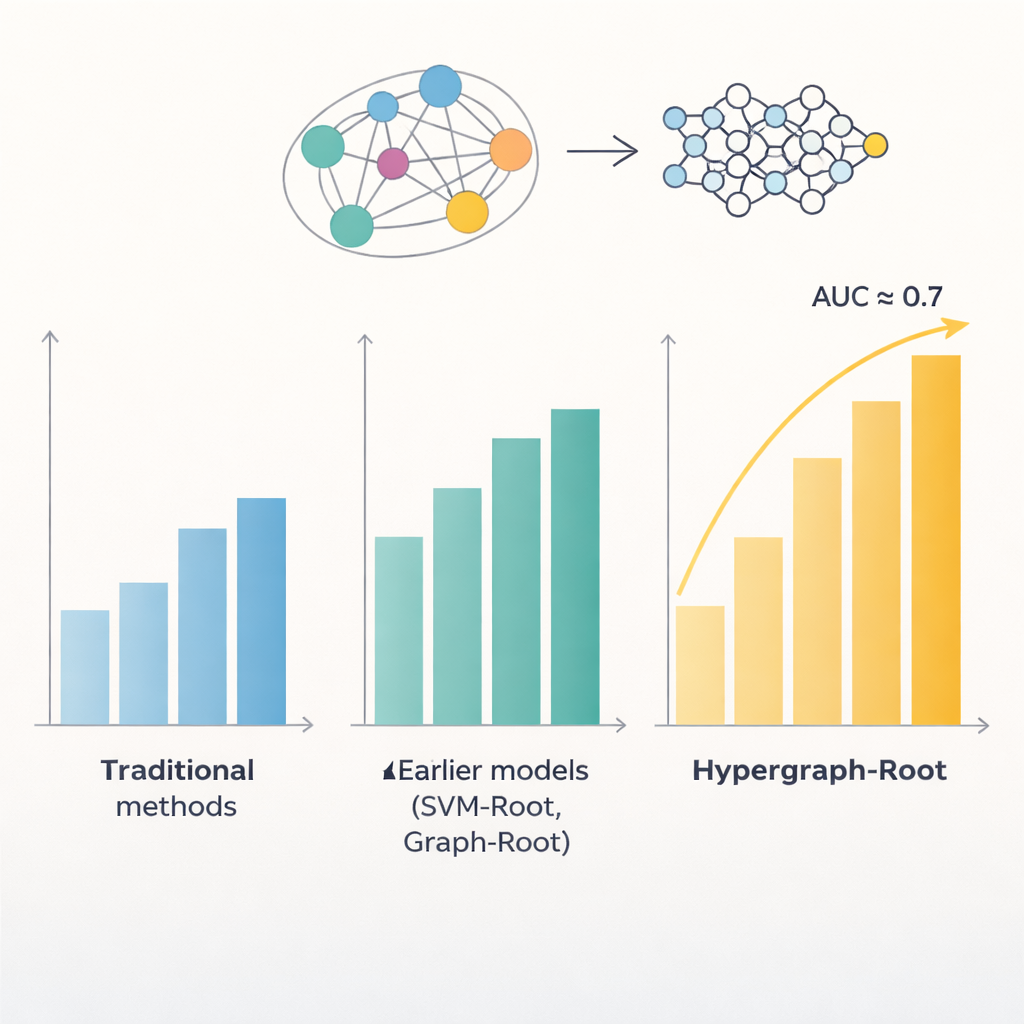
Las proteínas se construyen a partir de cadenas de aminoácidos, y los patrones en esas cadenas a menudo revelan dónde actúa una proteína en la planta y qué hace. Modelos informáticos previos intentaron explotar estos patrones para detectar proteínas asociadas a la raíz, pero se quedaron por debajo del 80 % de precisión. Un problema es que trataban las relaciones entre aminoácidos de forma bastante simple, normalmente como pares. Otro es que dependían de tipos limitados de características extraídas de las secuencias. Los autores razonaron que representaciones más ricas de cada proteína, junto con formas más inteligentes de modelar las relaciones entre aminoácidos, podrían descubrir patrones más sutiles vinculados a funciones radiculares.
Tomando prestadas técnicas del lenguaje y de las redes
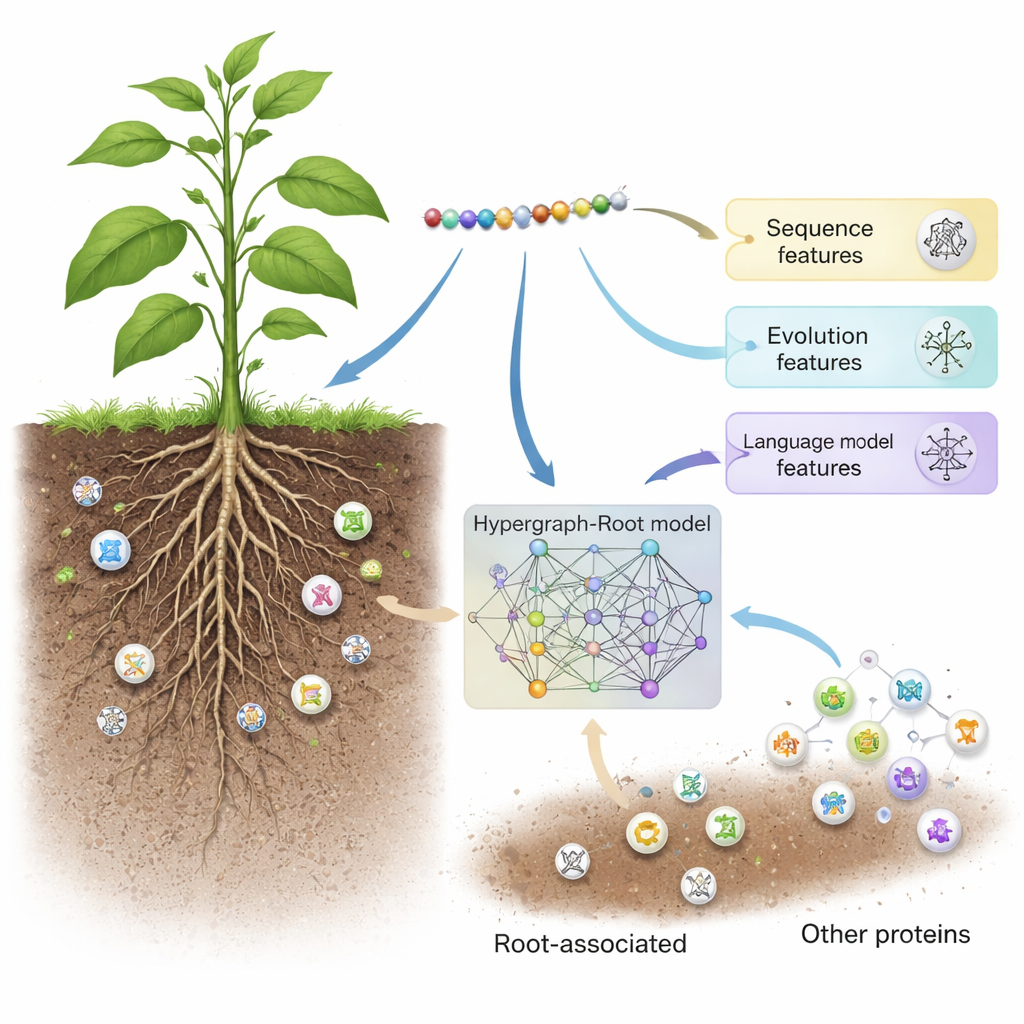
Hypergraph-Root comienza describiendo cada proteína de tres maneras complementarias. Usa esquemas tradicionales de puntuación de secuencias (BLOSUM62 y matrices de puntuación específicas de posición) que captan cómo tienden a sustituirse los aminoácidos a lo largo de la evolución. Luego añade una tercera descripción, más moderna, procedente de un modelo de lenguaje para proteínas llamado ProtT5—software entrenado con millones de secuencias de proteínas, de forma similar a cómo se entrena un motor de predicción de texto con lenguaje humano. ProtT5 produce una “incrustación” numérica rica para cada aminoácido que codifica pistas estructurales y funcionales. Juntas, estas tres visiones ofrecen la huella detallada de cada proteína en el estudio.
Mapear conexiones complejas dentro de las proteínas
Para ir más allá de las comparaciones pareadas simples, los investigadores predijeron qué tan cerca están los aminoácidos en la estructura 3D de una proteína y usaron esa información para construir un hipergráfico—una red en la que una sola conexión puede enlazar más de dos aminoácidos a la vez. Una red neuronal especializada, la red convolucional de hipergráficas, procesa esta red consciente de la estructura y refina las huellas de las proteínas en características de nivel superior. Un módulo de atención multi-cabeza aprende luego qué partes de la proteína contienen las señales más útiles para decidir si está asociada a la raíz. Finalmente, un clasificador estándar convierte estas características destiladas en una puntuación de probabilidad: asociada a la raíz o no. A lo largo de múltiples entrenamientos y en conjuntos de prueba balanceados y no balanceados, Hypergraph-Root alcanzó precisiones por encima del 83 % y un área bajo la curva ROC (AUC) alrededor de 0,9, superando claramente a modelos anteriores.
Lo que revela el modelo y por qué importa
Más allá de la precisión bruta, el modelo ofreció información sobre qué datos importan más. Las características procedentes del modelo de lenguaje ProtT5 contribuyeron más que las características tradicionales de secuencia y evolutivas, lo que sugiere que los grandes modelos preentrenados pueden captar señales biológicas sutiles que los métodos antiguos pasan por alto. El componente de hipergráfico también resultó importante: eliminarlo o reemplazarlo por un modelo de grafo más simple redujo el rendimiento. Cuando los investigadores aplicaron Hypergraph-Root a proteínas no etiquetadas previamente como asociadas a la raíz, destacó un puñado cuyas funciones conocidas—como transporte de membrana y etiquetado proteico en raíces—sugieren con fuerza que desempeñan papeles en la biología radicular. Estos candidatos ofrecen ahora a los biólogos experimentales listas cortas claras para probar en el laboratorio.
De predicciones inteligentes a cultivos más resistentes
En términos cotidianos, Hypergraph-Root es como un bibliotecario experto en biología vegetal: dada solo la “letra” de una proteína, estima si esa proteína probablemente actúa en las raíces. Al combinar conocimientos de modelos de lenguaje, historia evolutiva y relaciones estructurales complejas, mejora mucho las herramientas de predicción anteriores. Aunque no sustituye a los experimentos, puede reducir miles de posibilidades a unas pocas manejables, ahorrando tiempo y dinero. A largo plazo, modelos como este podrían acelerar el descubrimiento de proteínas asociadas a la raíz que ayudan a los cultivos a sobrevivir al calor, la sequía o suelos pobres—un paso importante hacia una agricultura más resiliente en un clima cambiante.
Cita: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Palabras clave: proteínas asociadas a la raíz, bioinformática vegetal, aprendizaje profundo, modelos de lenguaje para proteínas, resiliencia de cultivos