Clear Sky Science · es
Un modelo híbrido inteligente de evaluación para la enseñanza de la traducción al inglés con BERT y SVM mejorados
Por qué importa una corrección de traducciones más inteligente
Cada año, los profesores de idiomas dedican innumerables horas a corregir las traducciones de los estudiantes. Decidir si una frase es “suficiente” es un proceso lento, subjetivo y que puede variar mucho de un docente a otro. Este artículo explora si la inteligencia artificial puede compartir esa carga—ofreciendo puntuaciones rápidas y coherentes y pistas sobre qué falló—sin reemplazar al profesor. Presenta un nuevo modelo informático, llamado BERT-SVM EduScore, diseñado específicamente para juzgar la calidad de traducciones al inglés en un entorno educativo.
Del simple emparejamiento de palabras a una comprensión más profunda
Durante décadas, los ordenadores han evaluado las traducciones principalmente contando cuántas palabras o frases cortas coinciden con una respuesta de referencia. Herramientas bien conocidas como BLEU o METEOR hacen esto muy rápido, pero tienen dificultades con la flexibilidad del lenguaje natural: dos oraciones pueden expresar el mismo significado con palabras muy distintas. En el aula, donde los estudiantes experimentan con sinónimos y estructuras diversas, estas métricas antiguas pueden penalizar injustamente paráfrasis válidas y ofrecen poca orientación sobre errores concretos. Por ello, los investigadores han recurrido a métodos más recientes que comparan significados en lugar de palabras superficiales, usando potentes modelos de lenguaje entrenados con grandes colecciones de texto.
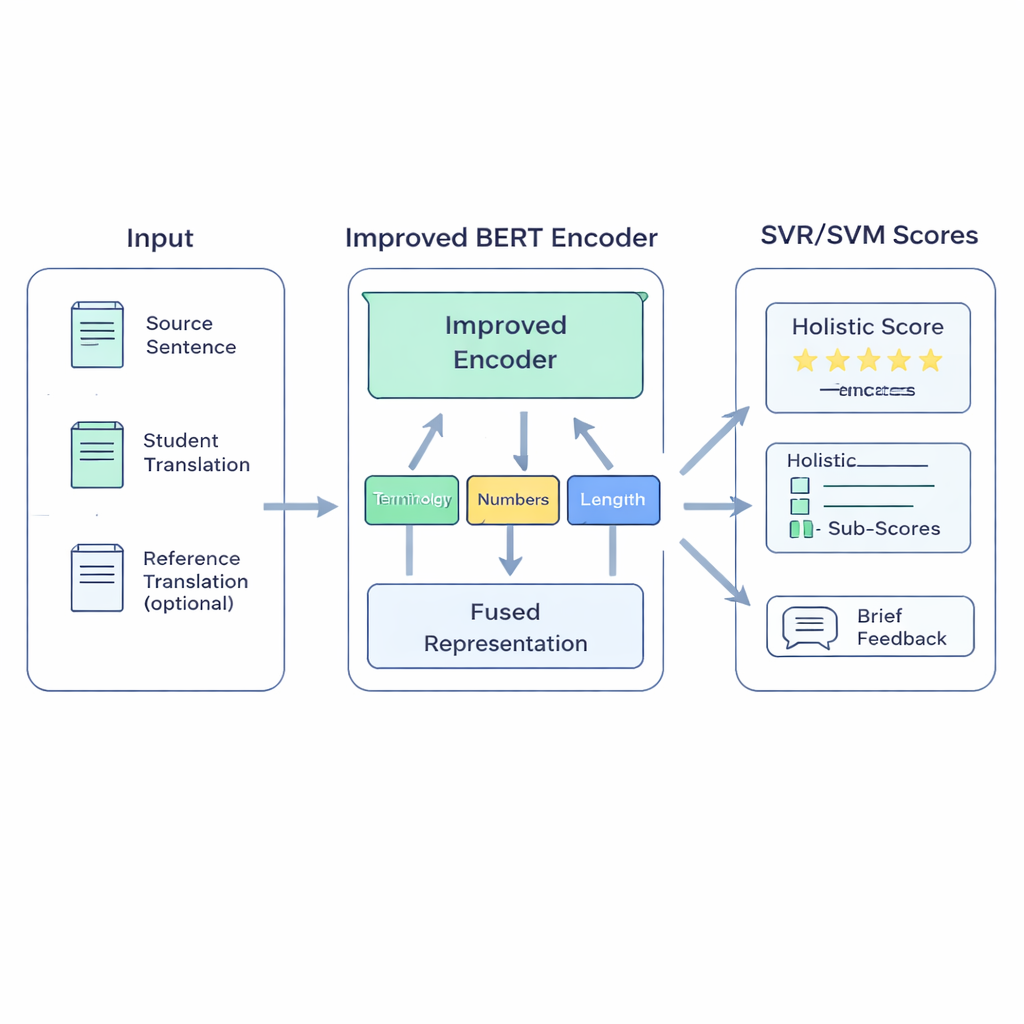
Un modelo híbrido pensado para las aulas
El sistema propuesto BERT-SVM EduScore combina dos ideas: comprensión profunda del lenguaje y estadística clásica y robusta. Primero, utiliza una versión mejorada del modelo de lenguaje BERT para leer tres textos: la frase original, la traducción del estudiante y, cuando está disponible, una traducción de referencia. BERT los convierte en un resumen numérico rico que refleja no solo qué palabras están presentes, sino cómo se alinean los significados. Sobre esto, el sistema añade un pequeño conjunto de verificaciones construidas a mano que importan a los docentes—como si los términos técnicos se traducen de forma coherente, si se conservan números y unidades, si la puntuación es adecuada y si la extensión de la traducción coincide con la del original.
Cómo aprende el sistema a puntuar como un profesor
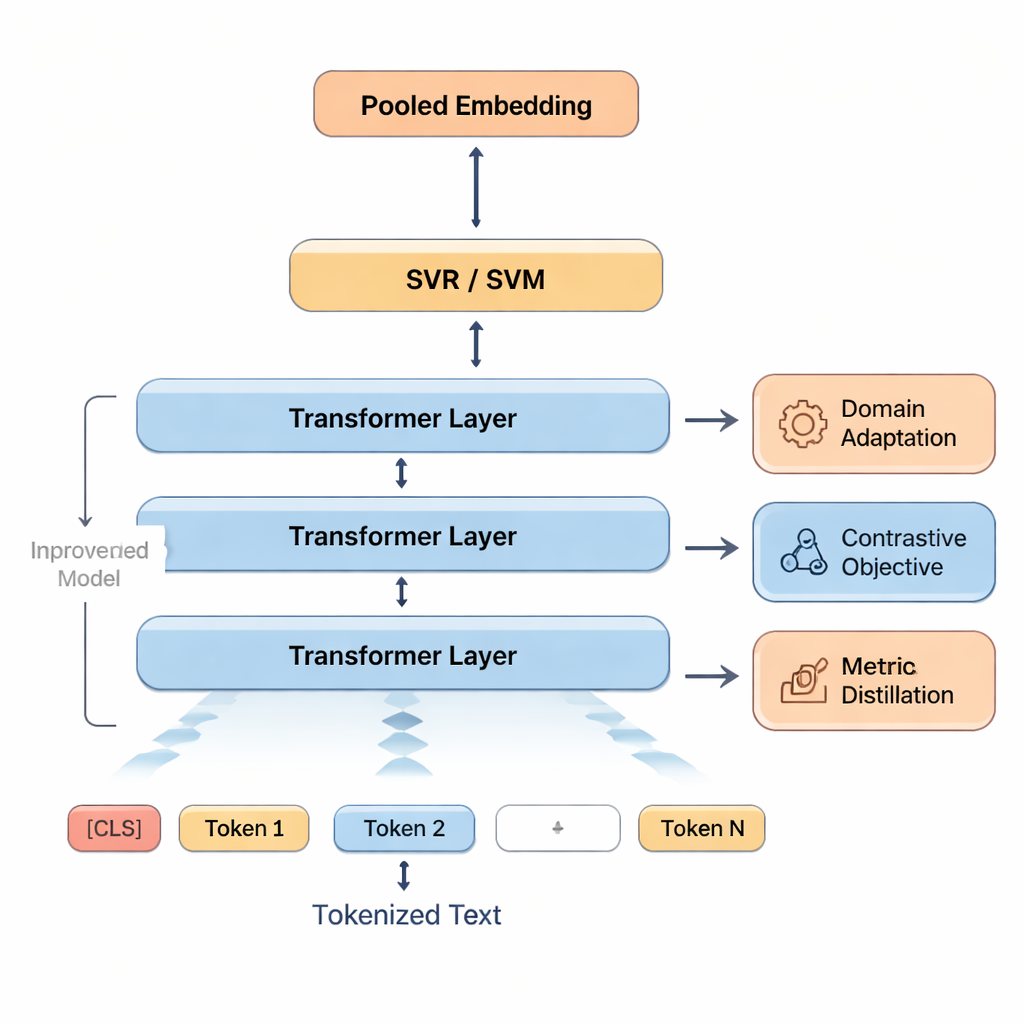
Esas señales se introducen luego en Máquinas de Vectores de Soporte (Support Vector Machines), una familia de algoritmos conocida por funcionar bien con datos limitados. Una parte predice una puntuación global; otras partes pueden producir puntuaciones separadas para áreas como precisión o fluidez, o clasificar las traducciones en bandas de calidad. Para ayudar al modelo a adaptarse al lenguaje propio del aula, los autores primero reentrenan BERT con textos similares al trabajo estudiantil—un enfoque llamado adaptación de dominio. Afinan además la capacidad de BERT para distinguir similitudes y diferencias haciéndole practicar en distinguir entre versiones buenas y versiones ligeramente editadas y malas de oraciones. Finalmente, cuando están disponibles métricas automáticas de alta calidad como COMET o BLEURT, el sistema aprende a imitar algunos de sus juicios, aprovechando sus fortalezas sin perder de vista las valoraciones humanas.
Poniendo el modelo a prueba
Los investigadores evalúan BERT-SVM EduScore en un gran conjunto de datos público que contiene traducciones automáticas inglés–chino valoradas por humanos. Aunque no son trabajos de estudiantes, sus valoraciones a nivel de oración se parecen a la corrección en el aula y proporcionan una prueba de estrés realista. El nuevo sistema se compara con puntuaciones tradicionales basadas en palabras, con métricas más recientes basadas en significado y con varios modelos neuronales potentes. No solo se alinea más estrechamente con los juicios humanos—mostrando mayor acuerdo y errores medios más pequeños—sino que además funciona lo suficientemente rápido como para procesar aproximadamente 44 oraciones por segundo en hardware gráfico estándar. Experimentos cuidadosos muestran que adaptar BERT al tipo correcto de texto aporta el mayor impulso, mientras que los trucos adicionales de aprendizaje proporcionan ganancias constantes y menores sin ralentizar apreciablemente el sistema.
Qué podría significar esto para docentes y estudiantes
En términos sencillos, el estudio muestra que un híbrido bien diseñado de aprendizaje profundo y métodos clásicos puede puntuar traducciones de forma más fiable que las herramientas automáticas existentes, manteniéndose además lo bastante rápido para su uso en tiempo real en el aula. BERT-SVM EduScore aún no es un reemplazo directo para los docentes: solo se ha probado con traducciones automáticas, no con trabajos reales de estudiantes, y no ha pasado ensayos en clase ni comprobaciones de equidad. Pero los resultados sugieren que un sistema así podría pronto ayudar a los profesores ofreciendo puntuaciones estables y destacando problemas probables—como terminología mal traducida o números omitidos—para que la retroalimentación humana pueda centrarse en aspectos más profundos y creativos de la traducción.
Cita: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
Palabras clave: evaluación de traducción, educación lingüística, BERT, máquinas de vectores de soporte, estimación de calidad