Clear Sky Science · es
Selección de características híbrida con un novedoso modelo de aprendizaje profundo para la predicción de riesgo de COVID-19
Por qué sigue siendo importante predecir el riesgo de COVID-19
Aunque el mundo ha aprendido a convivir con COVID-19, el virus no ha desaparecido. Siguen surgiendo nuevas variantes, los hospitales pueden seguir saturándose y las personas vulnerables continúan con mayor riesgo de enfermedad grave o muerte. Por ello, los médicos necesitan métodos rápidos y fiables para estimar la probabilidad de que un paciente infectado se agrave. Este artículo presenta un nuevo modelo informático que usa datos hospitalarios y técnicas avanzadas de inteligencia artificial para predecir el riesgo de COVID-19 con mayor precisión, lo que podría ayudar a los clínicos a decidir quién necesita vigilancia más estrecha, tratamiento temprano o cuidados intensivos.
De los registros clínicos en bruto a señales utilizables
El estudio parte de un conjunto de datos clínicos muy grande: más de un millón de pacientes anónimos, cada uno descrito por 21 características sencillas, mayoritariamente de tipo sí/no, como el grupo de edad, enfermedades subyacentes y otros factores de riesgo. Los datos hospitalarios del mundo real son desordenados, por lo que el primer paso es «limpiarlos». Los autores aplican un truco matemático llamado escalado logarítmico, que comprime valores extremos y expande conglomerados de valores muy pequeños. Esta transformación hace que los datos sean más estables y más fáciles de procesar por los algoritmos, reduciendo la probabilidad de que números inusuales o indicadores escasos confundan al modelo.
Seleccionando las señales más reveladoras
No todas las variables registradas son igual de útiles para la predicción, y un exceso de señales débiles puede en realidad confundir a un sistema de inteligencia artificial. Por ello, los investigadores realizan una selección de características, un proceso que filtra la información menos útil y conserva los factores más informativos. Su enfoque híbrido combina dos ideas: una medida evalúa qué tan bien una característica separa a los pacientes de alto riesgo de los de bajo riesgo, y otra comprueba cuánto se solapan entre sí las características. Al equilibrar estas dos perspectivas en una escala común, el método favorece atributos que son a la vez potentes y no redundantes. Esta poda acelera el entrenamiento, reduce el sobreajuste y centra el modelo en los patrones clínicamente más relevantes.
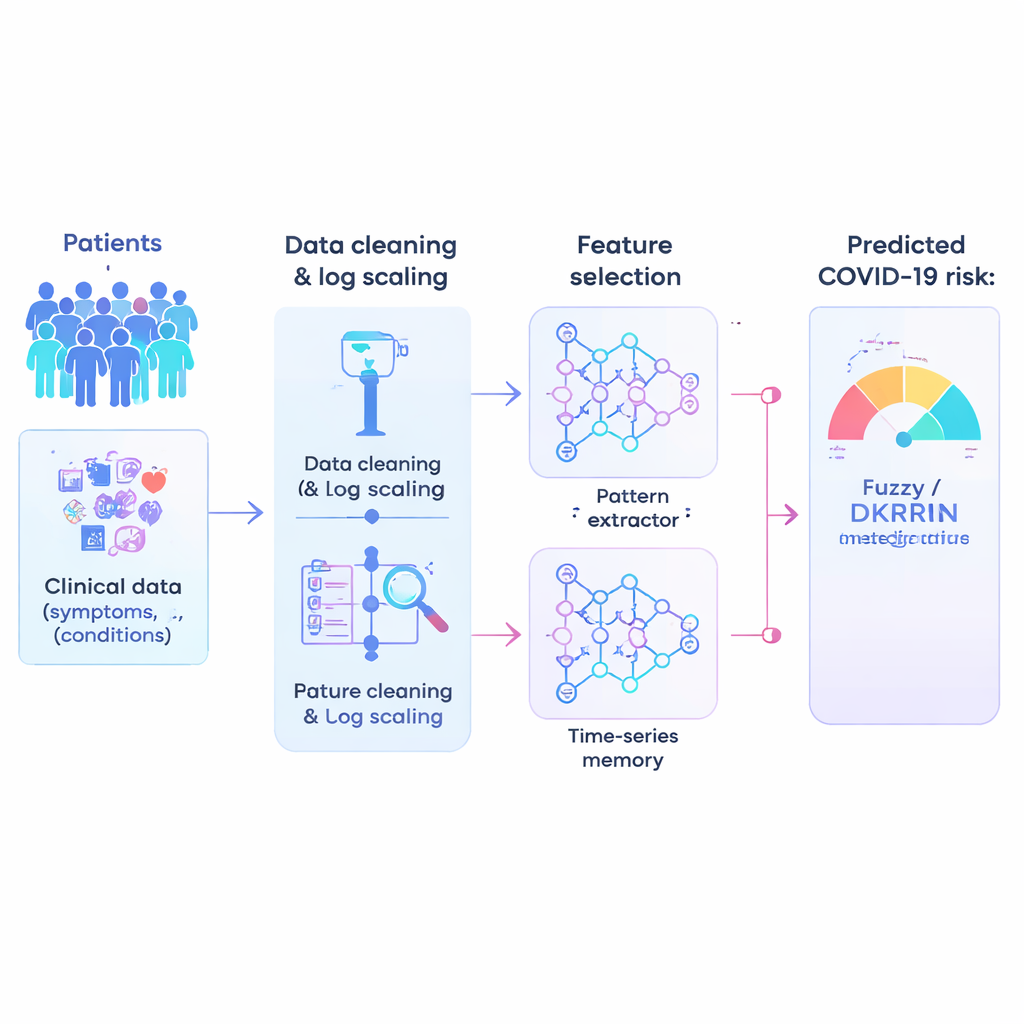
Combinando reconocimiento de patrones con razonamiento difuso
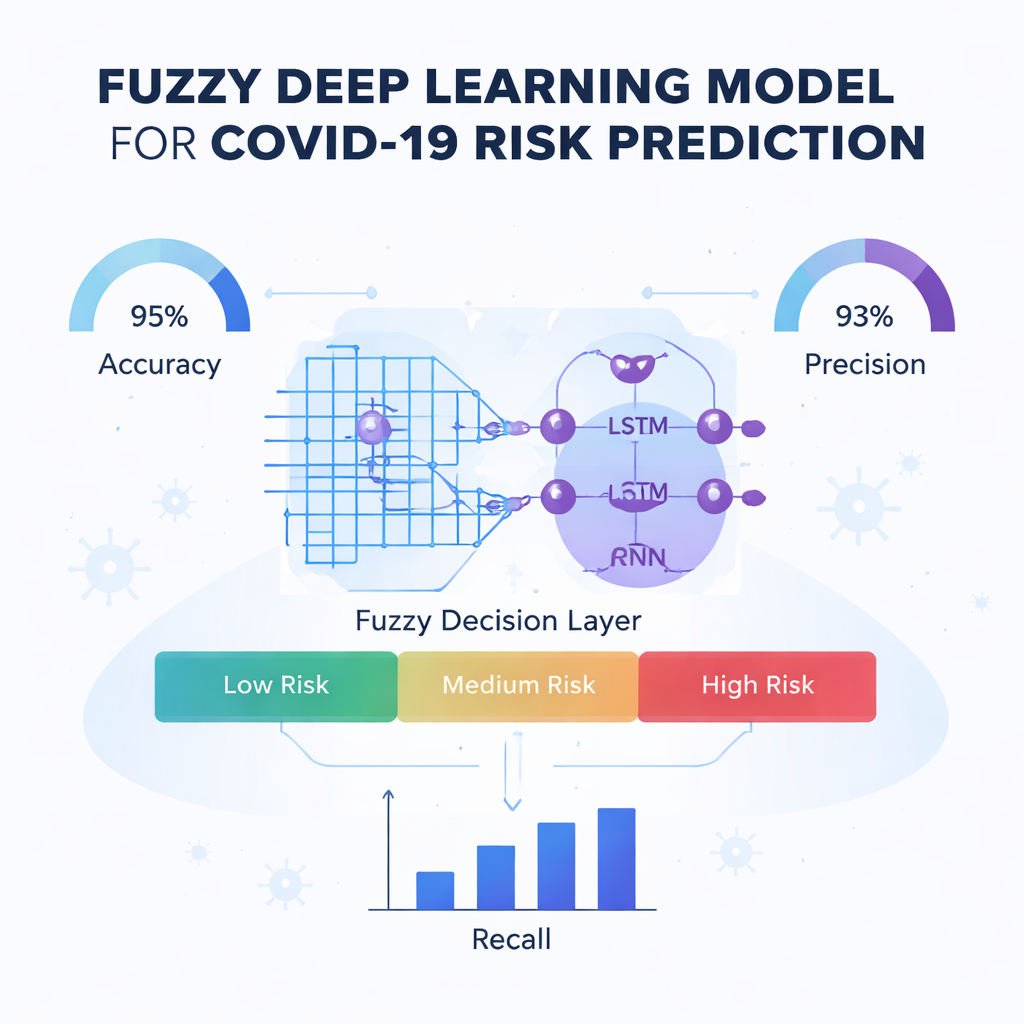
El núcleo del artículo es un nuevo motor de predicción llamado Red Neuronal Recurrente de Kronecker Profunda Difusa, o Fuzzy-DKRNN. Integra varias técnicas complementarias. Un componente, una Red de Kronecker Profunda, está diseñada para descubrir patrones compactos y estructurados ocultos en los datos clínicos. Otro componente, una red recurrente profunda, es adecuada para capturar dependencias y tendencias, por ejemplo cuando una combinación de factores a lo largo del tiempo influye en el riesgo. Sobre estos, los autores añaden un sistema de lógica difusa. En lugar de tomar solo decisiones duras de sí/no, las reglas difusas expresan afirmaciones como “si varios indicadores de riesgo son moderadamente altos, el paciente probablemente sea de alto riesgo”. Cada regla lleva un grado de certeza, lo que permite al modelo manejar la incertidumbre y las zonas grises comunes en medicina.
¿Qué tan bien funciona el modelo?
Los autores prueban rigurosamente su modelo Fuzzy-DKRNN frente a varias alternativas de última generación, incluidos sistemas basados en radiografías de tórax, aprendizaje automático tradicional y otros enfoques de aprendizaje profundo. Usando medidas estándar como exactitud, precisión, recall y F1-score, su método se sitúa consistentemente por delante. En su mejor configuración, el modelo clasifica correctamente alrededor del 91% de los casos en general, con alta capacidad tanto para detectar a los pacientes que se volverán gravemente enfermos como para evitar falsas alarmas en quienes no lo estarán. Estas mejoras se mantienen al variar la cantidad de datos de entrenamiento y los ajustes de validación interna, lo que sugiere que el enfoque es robusto y no simplemente ajustado a un escenario específico.
Qué significa esto para pacientes y hospitales
En términos sencillos, este trabajo demuestra que combinar una limpieza cuidadosa de datos, una selección inteligente de factores clave de riesgo y un híbrido de aprendizaje profundo con lógica difusa puede producir predicciones de riesgo de COVID-19 más fiables a partir de información clínica de rutina. Una herramienta así no reemplazará a los médicos, pero podría servir como un asistente de alerta temprana: señalando pacientes que merecen vigilancia más cercana, guiando la distribución de recursos escasos como camas de cuidados intensivos y, en última instancia, ayudando a reducir muertes evitables. La misma estrategia podría adaptarse también a otras enfermedades en las que la detección temprana del riesgo a partir de datos clínicos complejos es crucial.
Cita: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Palabras clave: predicción de riesgo de COVID-19, aprendizaje profundo, lógica difusa, soporte a la decisión clínica, modelos de IA médica