Clear Sky Science · es
Cálculo de la puntuación de similitud entre oraciones mediante aprendizaje profundo híbrido con especial atención a las oraciones con negación
Por qué el significado de las palabras importa para una calificación justa
Cuando los estudiantes responden con sus propias palabras, los sistemas informáticos que ayudan a los docentes a calificar deben comprender más que las palabras clave compartidas. Una palabra pequeña como “no” puede invertir el significado de una oración, y si los sistemas automáticos pasan por alto esa inversión, los estudiantes pueden recibir una calificación injusta. Este artículo aborda ese problema diseñando una nueva forma para que los ordenadores comparen los significados de oraciones prestando especial atención a cómo las palabras de negación cambian lo que se expresa.
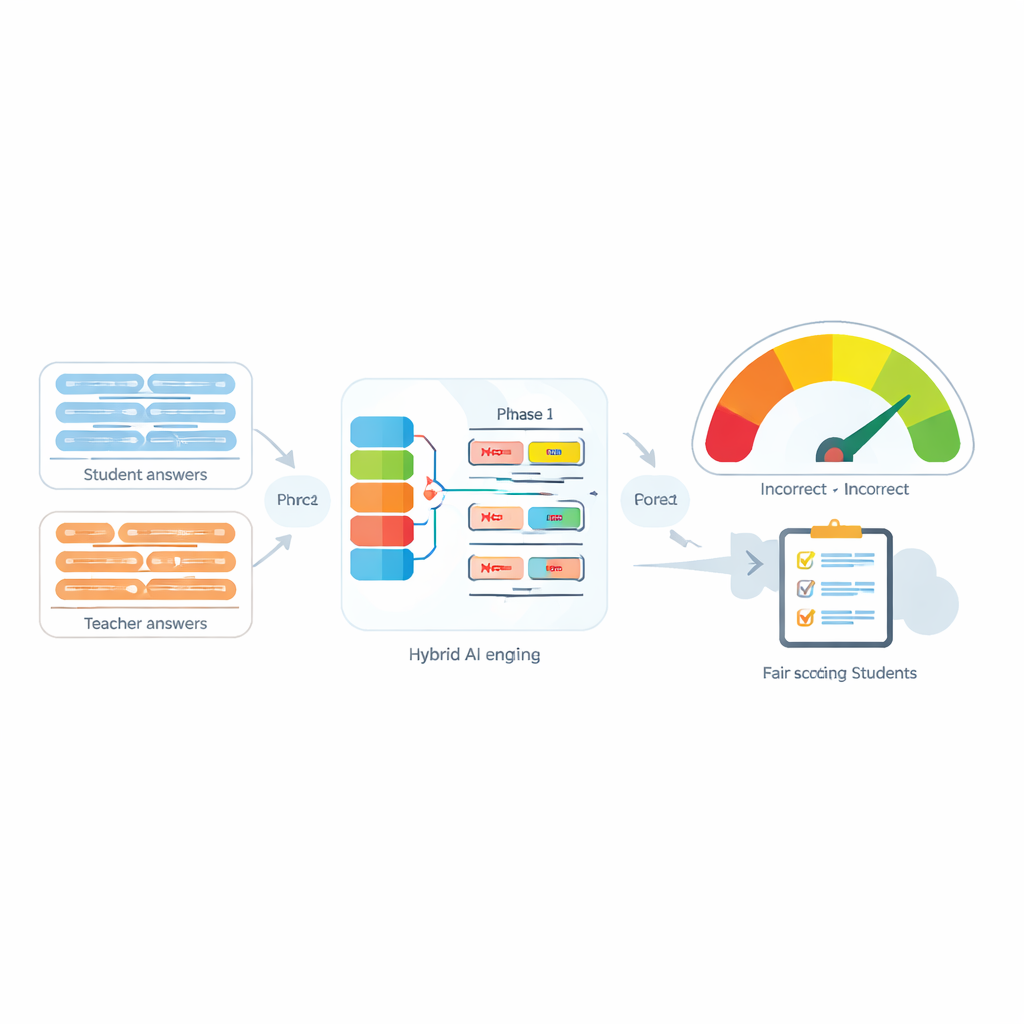
El desafío de las palabras diminutas con gran impacto
Los Sistemas de Evaluación Automática se usan cada vez más para aliviar la carga de trabajo de los docentes comparando la respuesta de un estudiante con la respuesta modelo del instructor. Muchas herramientas modernas hacen esto convirtiendo cada oración en una “huella” numérica y midiendo cuán cercanas están esas huellas. Estas herramientas funcionan razonablemente bien cuando no hay negación, pero con frecuencia fallan cuando aparecen palabras como “no”, “nunca” o “ninguno”. Por ejemplo, “El método es preciso” y “El método no es preciso” pueden parecer sorprendentemente similares para el ordenador, aunque signifiquen lo contrario. Los autores muestran que no solo la presencia de la negación, sino también cuántas palabras de negación aparecen y dónde se colocan en la oración, pueden cambiar por completo el significado pretendido.
Construir un conjunto de datos que enseñe matices
Para entrenar un sistema que realmente entienda la negación, los autores primero necesitaron datos que destacaran estos casos complejos. Crearon el Conjunto de Datos de Similitud de Oraciones con Negación, que contiene 8.575 pares de oraciones procedentes de cuatro dominios de la informática: sistemas operativos, bases de datos, redes de computadoras y aprendizaje automático. Para cada par, humanos asignaron una puntuación de similitud que ya tiene en cuenta la negación. El conjunto de datos también registra cuántas palabras de negación usa cada oración y qué tipo de patrón de negación sigue, como un único “no”, un número par o impar de negaciones, o casos más complejos donde la negación interactúa con conectores como “porque” o “pero”. Este etiquetado detallado ofrece al modelo pistas explícitas sobre cómo la negación modela el significado.
Un motor híbrido que fusiona múltiples puntos de vista
El núcleo del sistema propuesto, llamado Evaluador de Similitud Alineado con Negación, es un motor de dos fases. En la primera fase, el sistema pasa cada oración por varios modelos de lenguaje diferentes, cada uno de los cuales captura aspectos ligeramente distintos del significado. Sus salidas se combinan y luego se pasan por una red recurrente bidireccional que analiza la oración en su conjunto, teniendo en cuenta el orden de las palabras y el contexto local. Esto produce un resumen compacto de cada oración mejor afinado para frases sutiles, incluyendo la posición de las palabras de negación respecto a otras palabras.
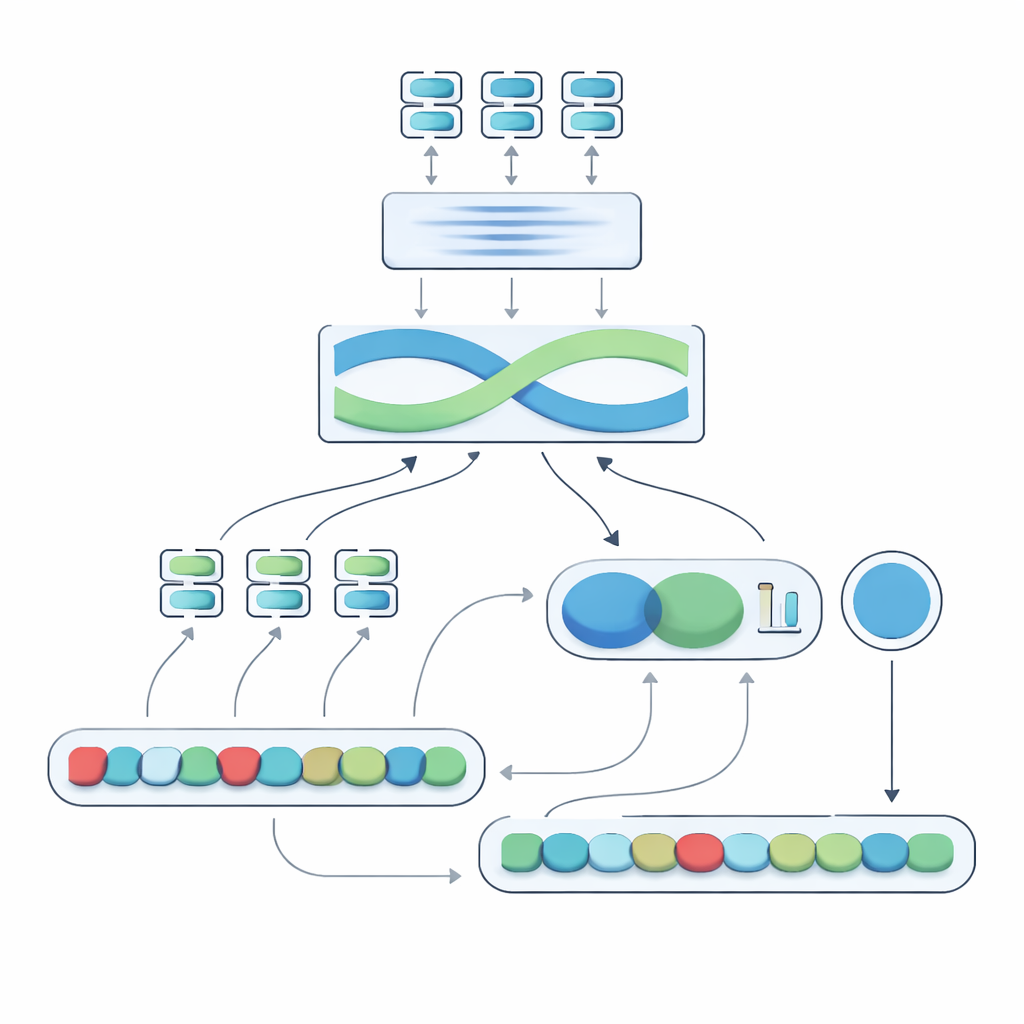
Enseñar al modelo a percibir la inversión de la negación
En la segunda fase, el sistema compara los dos resúmenes de oración y añade información explícita sobre la negación. Observa cuánto difieren los resúmenes, cuánto se solapan y combina esas señales con tres características simples: la diferencia en el número de palabras de negación, si las oraciones tienen un conteo de negaciones par o impar (lo que puede invertir o cancelar el sentido negativo) y si la negación aparece en posiciones aproximadamente correspondientes. Todas estas pistas se integran en una pequeña red de predicción que genera una puntuación de similitud de 0 a 100. Entrenada de forma end-to-end en el conjunto de datos curado, esta puntuación se vuelve sensible a la forma en que la negación remodela el significado en lugar de tratar “no” como una palabra más.
Qué tan bien funciona el nuevo evaluador en la práctica
Para probar su enfoque, los autores lo evalúan tanto en su conjunto de datos personalizado como en un punto de referencia ampliamente usado de similitud de oraciones. En comparación con fuertes baselines basados en transformadores que emplean métodos estándar, el nuevo evaluador logra un menor error de predicción y una calidad de clasificación mucho mayor, con una puntuación F1 cercana a 0,97. En ejemplos escogidos con cuidado, asigna puntuaciones de similitud bajas cuando la negación claramente invierte el significado y puntuaciones altas cuando la doble negación efectivamente se anula, mientras que los modelos competidores tienden a sobrestimar la similitud. Un estudio de ablación confirma que ambos ingredientes clave—la capa recurrente sensible a la secuencia y las características explícitas de negación—son importantes para esta mejora en el rendimiento.
Qué supone esto para estudiantes y herramientas futuras
Para un lector no especializado, la conclusión es sencilla: la forma en que decimos “no” importa, y se puede enseñar a las máquinas a notarlo. Al combinar múltiples modelos de lenguaje, procesamiento contextual y simples recuentos y posiciones de palabras de negación, el evaluador propuesto ofrece una forma más justa y fiable de juzgar cuándo dos oraciones realmente significan lo mismo. Esto puede ayudar a los sistemas de corrección automática a evitar errores graves, como tratar “no está permitido” como si fuera “está permitido”. Aunque el método exige más recursos computacionales y sigue centrado en dominios técnicos, señala hacia herramientas futuras que capturen mejor la lógica de grano fino del lenguaje cotidiano, haciendo que las tecnologías automáticas del lenguaje sean más inteligentes y confiables.
Cita: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Palabras clave: similitud de oraciones, negación en el lenguaje, evaluación automatizada, procesamiento del lenguaje natural, modelos de aprendizaje profundo