Clear Sky Science · es
Búsqueda de IP de alto rendimiento mediante aceleración por GPU para soportar enrutamiento escalable y eficiente en redes de comunicación basadas en datos
Por qué importan carreteras de Internet más rápidas
Cada foto que compartes, vídeo que reproduces o mensaje que envías debe atravesar un laberinto de cruces digitales llamados routers. Cada router debe decidir rápidamente a dónde enviar el siguiente paquete de datos. A medida que el uso global de Internet se dispara, estas decisiones ocurren miles de millones de veces por segundo, y hasta pequeños retrasos pueden traducirse en navegación más lenta o redes congestionadas. Este artículo explora una nueva forma de acelerar uno de los pasos más consumidores de tiempo en ese proceso de decisión aprovechando la enorme potencia paralela de los procesadores gráficos, los mismos chips que impulsan los videojuegos y la IA, para mantener las redes futuras rápidas y escalables.
La agenda oculta de direcciones de Internet
En el corazón de cada router hay una gran agenda de direcciones, llamada tabla de reenvío, que asigna rangos de direcciones IP al siguiente salto del trayecto. Cuando llega un paquete, el router debe buscar qué entrada coincide mejor con el destino del paquete, usando la regla de “coincidencia de prefijo más largo”: entre todas las coincidencias parciales, elige la más específica. Los métodos tradicionales en software almacenan estos prefijos en estructuras tipo árbol y las recorren paso a paso. Esto funciona, pero a medida que las tablas crecen hasta decenas o cientos de miles de entradas, el proceso se vuelve más lento y exige más memoria, sobre todo en procesadores centrales convencionales que solo gestionan un número limitado de tareas a la vez.
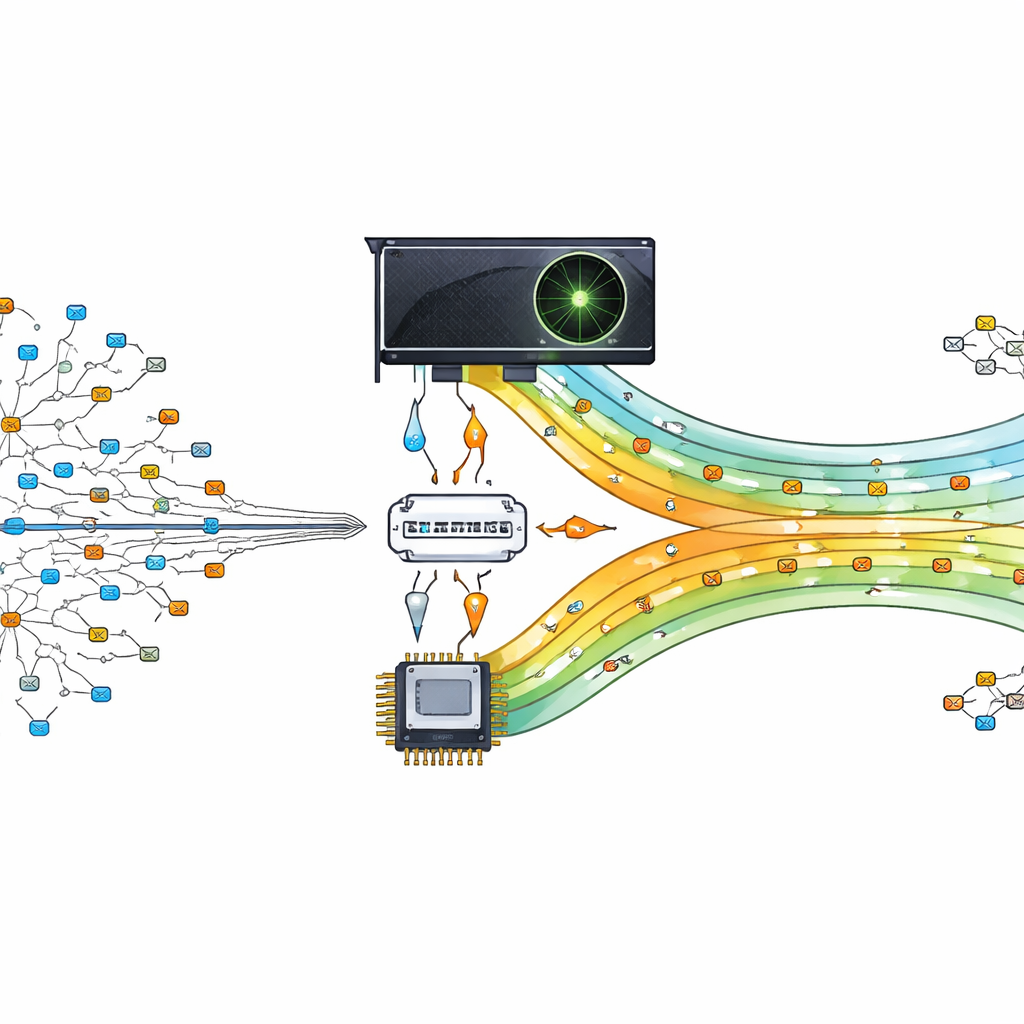
Convertir un chip gráfico en un agente de tráfico
Los autores proponen descargar este pesado trabajo de búsqueda a una unidad de procesamiento gráfico (GPU), un chip diseñado para ejecutar miles de pequeñas tareas en paralelo. Su diseño trata a la GPU como un ayudante del procesador principal. El procesador central prepara y organiza la tabla de enrutamiento, y luego envía versiones compactas de los datos a la GPU. Cuando llegan paquetes, sus direcciones de destino se dividen y se envían a la GPU, donde muchos hilos buscan simultáneamente la mejor coincidencia. Al permitir que cientos o miles de búsquedas ocurran en paralelo, el router puede mantenerse al ritmo de las demandas de comunicación modernas impulsadas por los datos.
Reducir direcciones para acelerar las decisiones
Una idea clave del trabajo es que las direcciones más cortas son más rápidas de buscar. En lugar de usar direcciones IP sin procesar, los autores las comprimen mediante un método sin pérdida llamado codificación de Huffman, que asigna códigos más cortos a los patrones de dirección más comunes. Esto reduce el número medio de bits necesarios para representar cada entrada, disminuyendo tanto el uso de memoria como la altura de la estructura de búsqueda subyacente. Después almacenan los prefijos en un árbol “multibit” que examina varios bits a la vez, en lugar de solo uno, reduciendo aún más el número de pasos necesarios. Para ajustarse a las fortalezas de la GPU, transforman ese árbol en simples arreglos unidimensionales, reemplazando el complejo seguimiento de punteros por cálculos de índices regulares que miles de hilos pueden ejecutar de manera eficiente.
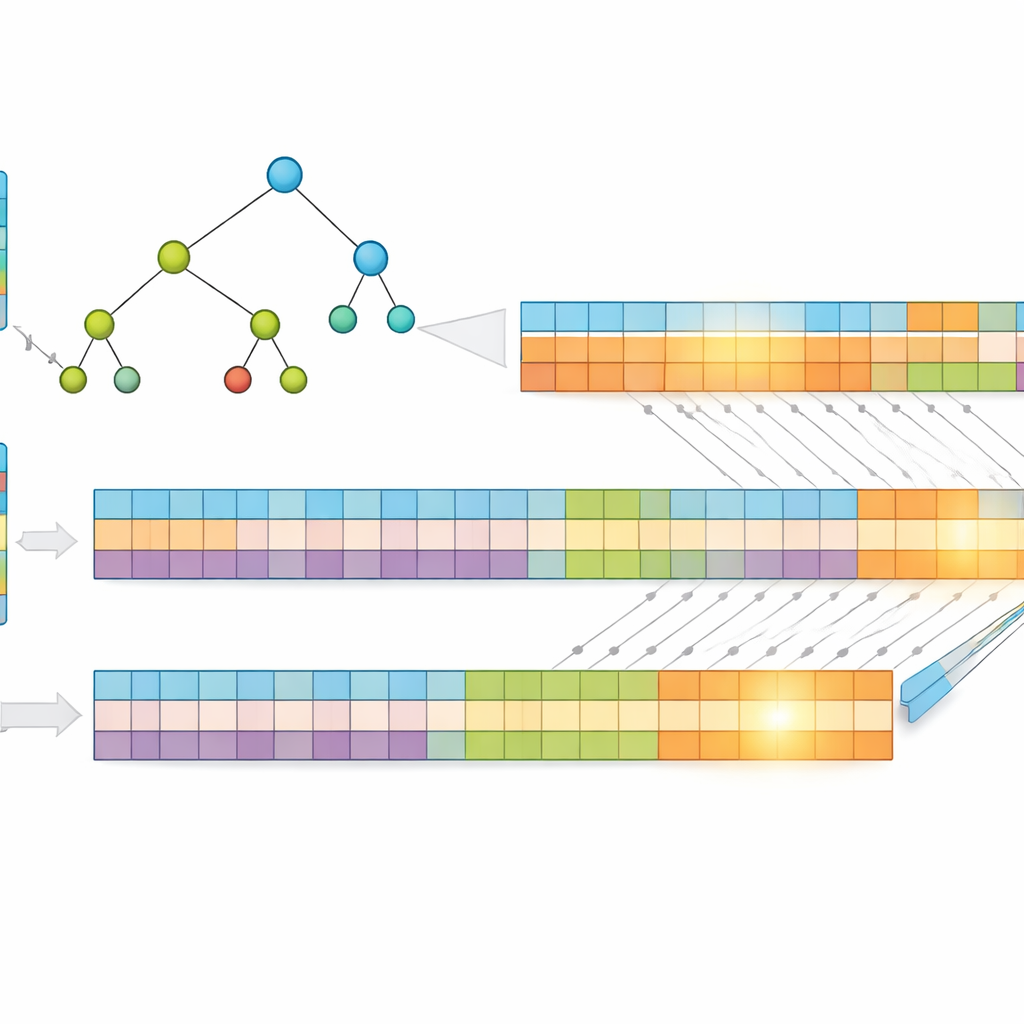
Dividir el problema para un paralelismo masivo
Para impulsar aún más el rendimiento, los investigadores dividen cada dirección comprimida en dos mitades iguales y construyen dos árboles separados: uno para la primera mitad y otro para la segunda. Cuando llega un paquete, la GPU busca en ambos árboles en paralelo. Cada búsqueda devuelve un pequeño conjunto de posibles coincidencias, y la respuesta final se obtiene intersectando estos conjuntos para encontrar el prefijo compartido más específico. Debido a que el trabajo se reparte y se procesa simultáneamente, el tiempo requerido depende principalmente de la longitud máxima del prefijo y del número de bits examinados por paso, no de cuántas entradas contiene la tabla. Pruebas con datos reales de enrutamiento de Internet muestran que este diseño mantiene un tiempo de búsqueda casi constante incluso cuando la tabla crece.
Qué revelan los experimentos
El equipo comparó su método basado en GPU con una variedad de enfoques bien conocidos, incluidos árboles binarios clásicos, árboles comprimidos y otros esquemas acelerados por GPU como hashing y árboles de búsqueda binaria. Con conjuntos de datos reales de enrutamiento, su sistema ofreció ganancias dramáticas: alrededor de un 83–91 por ciento más rápido que los métodos de árbol populares basados en procesador central, y un 89–97 por ciento más rápido que métodos GPU anteriores. La compresión también redujo el uso de memoria en aproximadamente un tercio en promedio, aliviando la presión sobre la memoria limitada en chip y ayudando a mantener las estructuras de búsqueda de la GPU poco profundas y eficientes. Es importante destacar que el rendimiento del método se mantuvo estable a través de diferentes tamaños de tablas de enrutamiento, subrayando su idoneidad para redes en crecimiento.
Qué significa esto para los usuarios cotidianos
Para un público no especializado, la conclusión es que los autores muestran cómo convertir un chip gráfico en un agente de tráfico muy eficiente para los datos de Internet, usando técnicas inteligentes de reducción y división de la información de direcciones. Combinando compresión, diseños de árbol más inteligentes y búsqueda paralela masiva, su enfoque encuentra la mejor ruta para cada paquete mucho más rápido que muchas técnicas existentes, sin ralentizarse a medida que las agendas de direcciones de Internet se expanden. Aunque el trabajo se demuestra principalmente para el sistema de direcciones actual, las mismas ideas podrían extenderse al espacio de direcciones más amplio del futuro, ayudando a mantener los servicios en línea sensibles mientras nuestro apetito por los datos continúa creciendo.
Cita: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Palabras clave: Enrutamiento por GPU, Búsqueda de IP, escalabilidad de redes, reenvío de paquetes, computación paralela