Clear Sky Science · es
Análisis de aplicabilidad de aprendizaje en conjunto basado en árboles para modelos de predicción de contaminantes atmosféricos
Por qué un aire más limpio necesita pronósticos más inteligentes
Las personas en las grandes ciudades a menudo se despiertan preguntándose si el aire exterior es seguro para salir a correr, para el desplazamiento diario o para que los niños jueguen al aire libre. Las aplicaciones meteorológicas ya muestran índices de calidad del aire junto a la temperatura, pero esos números solo son tan fiables como los modelos que los sustentan. Este estudio plantea una pregunta práctica con consecuencias reales: ¿qué herramientas modernas de inteligencia artificial hacen el mejor trabajo prediciendo varios contaminantes atmosféricos importantes a la vez, y por qué?
Monitoreando el aire urbano día a día
Los investigadores se centraron en cuatro de los municipios más grandes de China —Beijing, Shanghái, Tianjin y Chongqing— porque abarcan distintos climas y patrones de contaminación, desde la niebla invernal hasta el ozono veraniego. Reunieron más de cinco mil registros diarios entre 2021 y 2024, cada uno combinando mediciones de seis contaminantes clave (incluyendo partículas finas, polvo, dióxido de nitrógeno, dióxido de azufre, monóxido de carbono y ozono) con datos meteorológicos como temperatura, humedad, viento, precipitación y presión atmosférica. Para aprovechar al máximo estas observaciones, añadieron pistas adicionales: cómo la contaminación de días anteriores puede persistir, cómo interactúan temperatura y viento para dispersar el aire sucio, y cómo medidas combinadas de partículas y gases pueden reflejar mejor los riesgos para la salud.
Enseñar a los “árboles” digitales a leer el aire
En lugar de utilizar modelos meteorológicos tradicionales fuertemente basados en la física, el equipo recurrió a una familia de herramientas impulsadas por datos conocidas como aprendizaje automático basado en árboles. Estos algoritmos toman decisiones dividiendo repetidamente los datos en ramas, algo así como un juego de veinte preguntas que reduce las opciones hasta encontrar la respuesta final. El estudio comparó tres versiones: un árbol de decisión simple; un bosque aleatorio, que promedia los resultados de muchos árboles para suavizar el ruido; y el boosting por gradiente, que construye árboles uno tras otro para corregir gradualmente errores anteriores. Los científicos ajustaron cuidadosamente cada método y usaron una estrategia de evaluación sensible al tiempo para que los modelos aprendieran de días pasados y se evaluaran con días posteriores, reflejando condiciones reales de pronóstico.
Qué modelos destacan para qué contaminantes
El cara a cara reveló que ningún método único es el mejor para todo, pero surgieron algunas opciones destacadas. Los bosques aleatorios fueron excepcionalmente precisos para partículas finas y gruesas y para el dióxido de azufre, explicando alrededor del 99 por ciento de la variación en sus niveles —cerca de lo que los propios instrumentos pueden medir. Para el monóxido de carbono y el dióxido de nitrógeno, una forma de boosting por gradiente igualó casi el rendimiento del bosque, lo que sugiere que este enfoque de corrección por pasos se adapta bien a emisiones relacionadas con el tráfico y la combustión que suben y bajan rápidamente. Sorprendentemente, el árbol de decisión simple, a pesar de ser la herramienta más sencilla, se mantuvo competitivo en la predicción del ozono, un contaminante que se forma mediante química impulsada por la luz solar y tiende a seguir patrones de tipo umbral que las reglas de ramificación pueden capturar.
Asomarse dentro de la caja negra
Para que estos modelos potentes fueran útiles en política, los autores necesitaban mostrar no solo qué tan bien predicen, sino por qué. Utilizaron una técnica llamada SHAP, que asigna a cada entrada —como temperatura, velocidad del viento u otro contaminante— una puntuación de contribución para cada pronóstico. Este análisis reveló vínculos esclarecedores. El monóxido de carbono emergió como un ayudante clave en la formación de partículas finas, coherente con su papel como marcador de combustión incompleta que produce vapores formadores de partículas. La temperatura impulsó fuertemente el ozono, reflejando cómo los días cálidos y soleados potencian su producción. El aire húmedo interactuando con dióxido de azufre tendió a frenar el crecimiento de partículas, y los vientos fuertes ayudaron a limpiar las partículas diminutas hasta un umbral, más allá del cual la mezcla turbulenta podría en realidad atraparlas localmente. Estos patrones conectan las matemáticas con procesos atmosféricos reales, ofreciendo pistas para controles dirigidos.
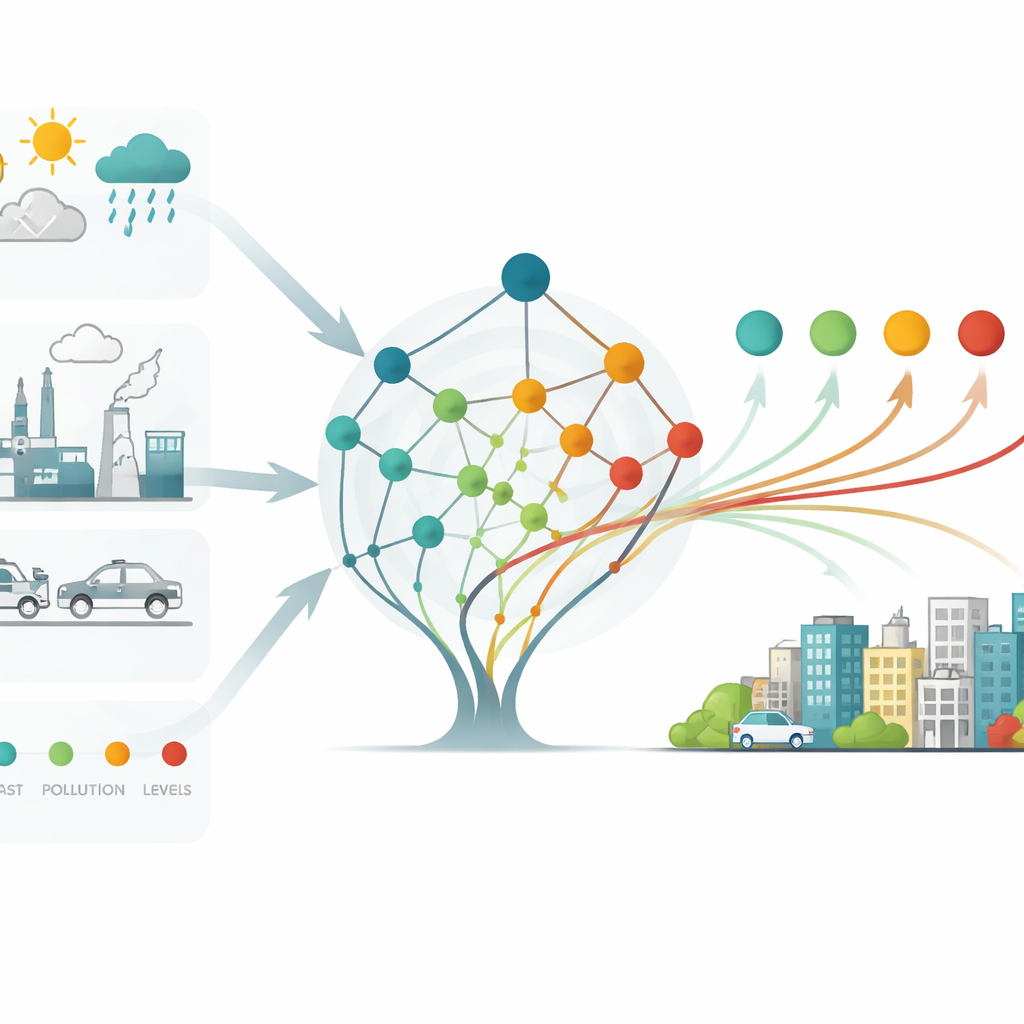
Del código de investigación a los sistemas de alerta urbana
A pesar de la precisión impresionante, los autores señalan que los modelos todavía tienen dificultades durante los episodios de smog más severos y están limitados por descripciones toscas del origen de las emisiones y por la ventana temporal relativamente corta de los datos. Proponen combinar simulaciones tradicionales de meteorología–química con aprendizaje automático y usar las perspectivas de SHAP para diseñar respuestas de emergencia más inteligentes cuando la contaminación se dispara. Su marco ya se está empleando en un sistema regional de alerta de calidad del aire que sirve a Beijing y ciudades vecinas. En términos cotidianos, el estudio muestra que una inteligencia artificial bien elegida y bien explicada puede ofrecer a los responsables municipales advertencias más tempranas y fiables sobre los días de mal aire —y una guía más clara sobre qué fuentes abordar primero.
Cita: Zhu, X., Li, B., Cao, Y. et al. Applicability analysis of tree-based ensemble learning for air pollutant prediction models. Sci Rep 16, 9602 (2026). https://doi.org/10.1038/s41598-025-32652-0
Palabras clave: pronóstico de calidad del aire, contaminación atmosférica urbana, modelos de aprendizaje automático, bosque aleatorio, predicción multipollutante