Clear Sky Science · es
Detección de objetos camuflados mediante interacción jerárquica consciente del contexto y la textura
Por qué importa localizar formas ocultas
Desde insectos con color de hoja hasta camuflajes militares e incluso crecimientos difíciles de ver en exploraciones médicas, nuestro entorno está lleno de objetos diseñados para confundirse con el fondo. Enseñar a los ordenadores a localizar con fiabilidad estos objetos ocultos podría ayudar a proteger la fauna, mejorar las inspecciones de seguridad y asistir a los médicos para detectar enfermedades antes. Este artículo presenta un nuevo sistema de inteligencia artificial, denominado CTHINet, que aprende a ver a través del camuflaje prestando atención no solo al contexto global de la escena, sino también a las pequeñas pistas de textura que a menudo pasan desapercibidas para el ojo humano.
Ver el bosque y los árboles
La detección de objetos camuflados es mucho más difícil que la detección de objetos ordinaria porque el objetivo a menudo se confunde con su entorno en color, brillo y forma. Métodos anteriores dependían de pistas simples diseñadas a mano, como el movimiento, los bordes o texturas básicas, que fallan en escenas con mucho desorden o ruido. Los enfoques modernos de aprendizaje profundo han avanzado entrenando grandes redes con colecciones especializadas de imágenes de animales camuflados y objetos artificiales. Muchos de estos métodos añaden indicios extra, como delimitar bordes alrededor de los objetos o estimar la incertidumbre, pero pueden ser fácilmente engañados cuando los propios bordes son difusos o ambiguos —exactamente el caso en un buen camuflaje.
Pequeñas pistas de textura que delatan
Los autores sostienen que incluso el mejor camuflaje deja rastros en la textura fina de una imagen: pequeñas diferencias en grano, patrón o suavidad que son fáciles de pasar por alto cuando uno se centra solo en los contornos. Basándose en esta idea, CTHINet separa el aprendizaje en dos ramas coordinadas. Una rama de “contexto”, basada en una potente columna vertebral tipo vision transformer, captura información amplia y multiescala sobre la escena completa: cómo se relacionan las regiones entre sí, dónde se encuentran las formas grandes y qué zonas podrían contener plausiblemente un objeto. En paralelo, una rama dedicada a la “textura” se centra de forma estrecha en patrones superficiales sutiles, entrenada con etiquetas de textura especiales que indican a la red qué tipos de detalle fino pertenecen al objeto oculto y cuáles al fondo.
Cómo funcionan juntas las dos ramas
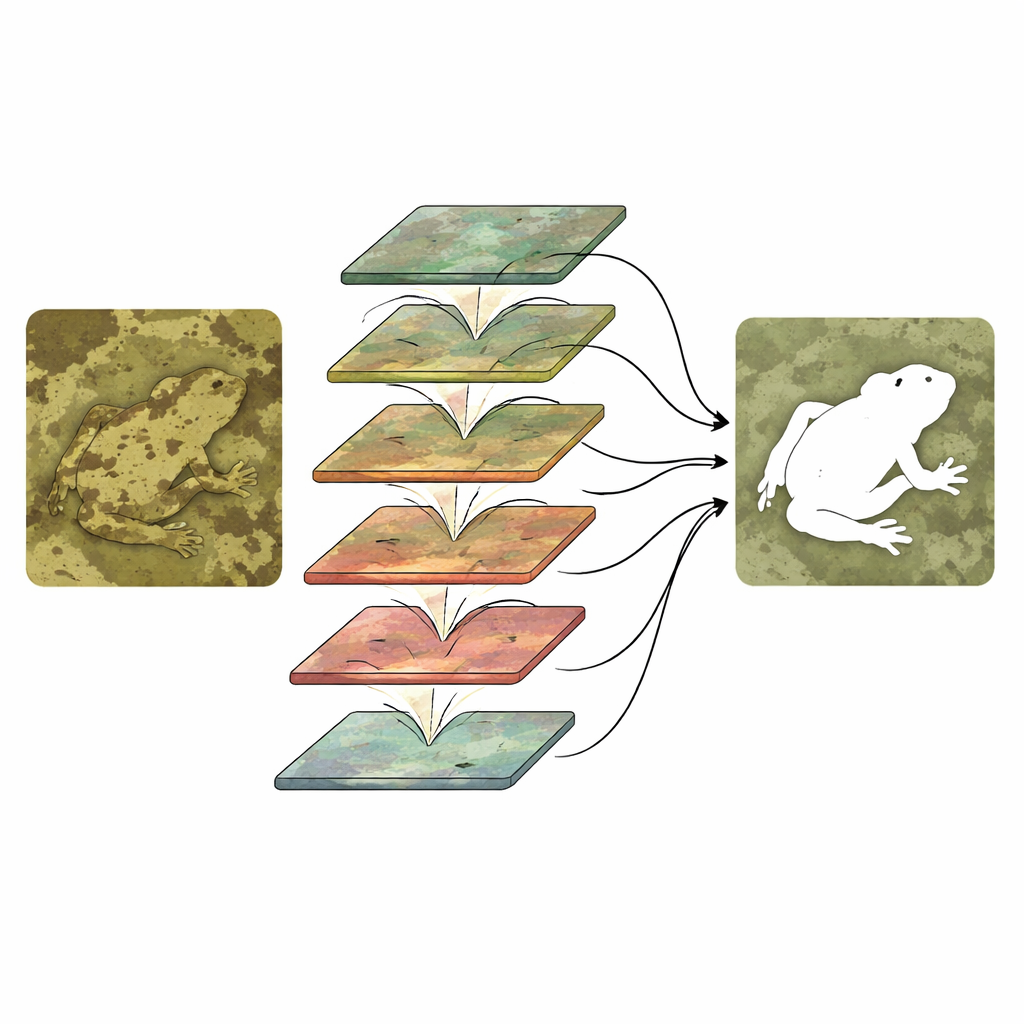
Ejecutar simplemente dos ramas no basta; deben interactuar de forma inteligente. CTHINet primero refina las características de contexto usando un Módulo de Agregación de Características Multifoco (Multi‑head Feature Aggregation Module). Este módulo divide la información en varias partes, cada una procesada con un “nivel de zoom” efectivo diferente, de modo que el sistema puede responder tanto a insectos diminutos como a animales grandes. Luego recombina estas vistas para que se informen entre sí sin disparar el coste computacional. A continuación, una serie de Módulos de Interacción Mixta Jerárquica (Hierarchical Mixed‑scale Interaction Modules) enlazan los canales de contexto y textura. En cada etapa, la red agrupa y mezcla canales de ambas ramas, les permite intercambiar información y luego los repondera para amplificar las combinaciones más informativas mientras suprime las menos útiles. Este apilamiento de grueso a fino afina gradualmente el contorno del objeto oculto y lo separa del detalle distractor del fondo.
Demostrando que funciona en la naturaleza y en la clínica
Para evaluar CTHINet, los investigadores lo probaron en tres benchmarks públicos desafiantes de animales y objetos camuflados, que contienen miles de imágenes en ambientes naturales variados. En varias métricas estándar de precisión, el nuevo método superó de forma consistente a más de veinte sistemas líderes, especialmente en escenas difíciles con objetivos pequeños, fuerte coincidencia con el fondo o oclusión parcial. El equipo también aplicó la misma red, con cambios mínimos, a una tarea médica: segmentar pólipos en imágenes de colonoscopia. Los pólipos a menudo se confunden con la pared intestinal de manera semejante a como los animales se confunden con el follaje. Aquí también, CTHINet logró los mejores resultados entre varios modelos sólidos de imágenes médicas, lo que sugiere que su manera de combinar contexto y textura es de utilidad general.
Qué significa esto para encontrar lo casi invisible
En términos cotidianos, CTHINet encarna una idea simple pero poderosa: para encontrar algo que está diseñado para permanecer oculto, un ordenador debe observar tanto la imagen global como los detalles superficiales más diminutos, y permitir que estas dos perspectivas se informen mutuamente paso a paso. Diseñando una red que separa claramente estos roles y luego los reúne mediante interacciones cuidadosamente escalonadas, los autores logran una detección más precisa de objetivos camuflados y muestran prometedoras aplicaciones en tareas médicas e industriales donde estructuras importantes pueden pasarse fácilmente por alto. A medida que los conjuntos de datos de imágenes siguen creciendo, sistemas conscientes del contexto y la textura como este podrían convertirse en herramientas clave para revelar lo que se pretendía mantener invisible.
Cita: Wang, Z., Deng, Y., Shen, C. et al. Camouflaged object detection via context and texture-aware hierarchical interaction. Sci Rep 16, 9328 (2026). https://doi.org/10.1038/s41598-025-32409-9
Palabras clave: detección de objetos camuflados, visión por ordenador, análisis de textura, segmentación de imágenes médicas, aprendizaje profundo