Clear Sky Science · es
Un conjunto de datos unificado para el diseño de anticuerpos y nanocuerpos que incluye secuencia, estructura y datos de afinidad de unión
Por qué importan las herramientas inmunitarias diminutas y los grandes datos
Los anticuerpos y sus parientes más pequeños, los nanocuerpos, son los misiles guiados de precisión del organismo contra infecciones y cáncer. Los desarrolladores de fármacos intentan ahora diseñar estas moléculas por ordenador, de forma análoga a cómo los ingenieros diseñan aeronaves. Pero hasta hace poco, la materia prima para ese diseño basado en inteligencia artificial—datos fiables sobre los componentes de los anticuerpos, sus formas y la intensidad con que se unen a sus dianas—estaba dispersa en muchas bases de datos incompatibles. Este artículo presenta el Conjunto de Datos para el Diseño de Anticuerpos y Nanocuerpos (ANDD), un recurso público y unificado creado para proporcionar a los investigadores datos limpios y completos necesarios para desarrollar la próxima generación de terapias dirigidas.
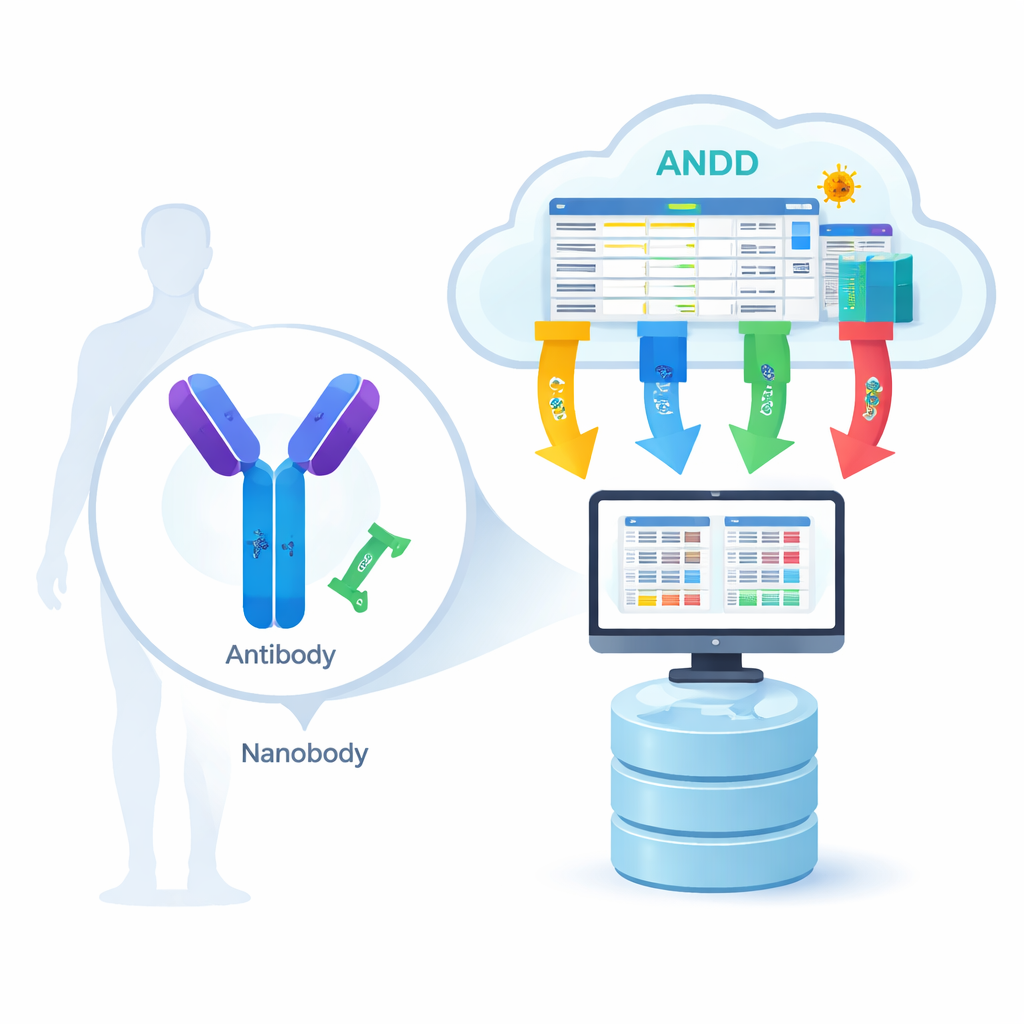
Del principio biológico de cerradura y llave al plano digital
Los anticuerpos son grandes proteínas con forma de Y, mientras que los nanocuerpos son versiones mucho más pequeñas y de una sola pieza que se encuentran en animales como llamas y alpacas. Ambos reconocen “cerraduras” específicas en virus, células cancerosas u otras proteínas relacionadas con la enfermedad. Para que los modelos informáticos aprendan cómo funciona este reconocimiento, necesitan cuatro tipos de información para muchos ejemplos distintos: la secuencia de aminoácidos (la lista de componentes), la estructura 3D (la forma), el antígeno (la diana) y la fuerza de unión (qué tan firmemente se adhieren). Hasta ahora, la mayoría de los recursos capturaban solo una o dos de estas piezas a la vez, obligando a los científicos a saltar entre bases de datos y ensamblar manualmente la información, lo que ralentizaba el progreso e introducía errores.
Reuniendo piezas dispersas en una biblioteca organizada
El equipo de ANDD recopiló datos de 15 fuentes principales, incluidas bases de datos dedicadas a anticuerpos y nanocuerpos, repositorios generales de proteínas e incluso documentos de patentes. A continuación, procesaron estas entradas crudas mediante una canalización cuidadosamente guionizada: descarga, reformateo a un esquema común, verificación cruzada de identificadores, eliminación de duplicados y armonización de reglas de nomenclatura. Cuando las bases de datos discrepaban, se priorizaron fuentes curadas y experimentos directos. El resultado final es una única tabla junto con un conjunto de archivos de estructura que conectan secuencia, estructura, diana e información de unión de forma consistente, con cada registro etiquetado para que los usuarios puedan rastrear exactamente su origen y cómo se procesó.
Detalle en capas para diferentes necesidades de investigación
No todas las entradas en ANDD tienen el mismo nivel de información, por lo que los autores organizaron la colección en capas de detalle creciente. En el nivel más amplio hay 48.683 entradas de anticuerpos y nanocuerpos con información de secuencia. Un subconjunto amplio añade estructuras 3D, y un subconjunto más pequeño incluye además la secuencia de las proteínas diana. La capa de mayor detalle—miles de entradas—añade la afinidad de unión medida o predicha. Para los anticuerpos, por ejemplo, 18.464 entradas tienen secuencias; ese mismo número combina secuencia y estructura; más de 8.000 incluyen también secuencias de antígenos; y 7.737 tienen secuencia completa, estructura, antígeno y datos de afinidad. Existe una jerarquía paralela para nanocuerpos, lo que proporciona flexibilidad tanto a los experimentalistas como a los desarrolladores de modelos: pueden elegir conjuntos de datos grandes y simples o subconjuntos más pequeños y ricos en información.
Rellenando los huecos sobre la fuerza de unión
La fuerza de unión es crucial para el diseño de fármacos, pero los valores experimentales son escasos y se informan de forma desigual. Para abordar esta laguna sin difuminar la línea entre dato y predicción, los autores usaron una herramienta especializada de aprendizaje profundo, ANTIPASTI, para estimar la afinidad de unión solo en las entradas que tenían estructuras pero carecían de mediciones. Estos 2.271 valores predichos están claramente etiquetados y se mantienen separados de los aproximadamente 7.000 valores medidos experimentalmente. El equipo comprobó luego la consistencia general usando otro modelo, AlphaBind, y comparando medidas matemáticamente relacionadas de unión. Las fuertes correlaciones y el bajo error sugirieron que los valores experimentales curados son fiables y que los valores predichos siguen tendencias razonables sin tratarse como verdad absoluta.
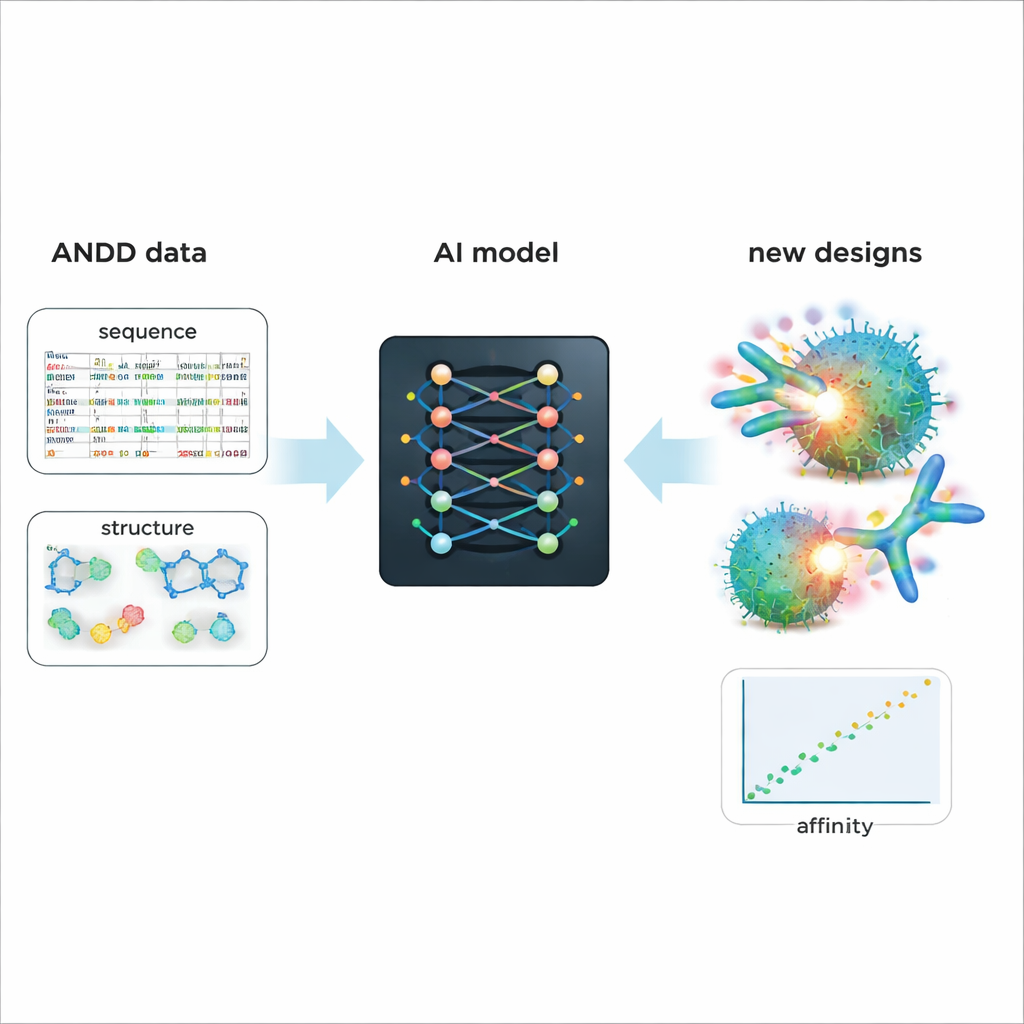
Impulsando un diseño más inteligente de futuros medicamentos
Para demostrar el valor práctico de ANDD, los autores ajustaron un modelo generativo de IA existente que diseña anticuerpos y nanocuerpos. El entrenamiento con la información combinada de secuencia, estructura, diana y afinidad de ANDD produjo moléculas generadas con mejor afinidad prevista y formas más realistas que un modelo de referencia entrenado con datos más antiguos y simples. Más allá de este estudio de caso, ANDD está disponible abiertamente bajo una licencia permisiva, incluye documentación completa y una canalización de construcción reproducible, y está diseñada para actualizarse regularmente. Para los no especialistas, el mensaje clave es que ANDD transforma un mosaico desordenado de datos sobre anticuerpos en una biblioteca coherente y fiable, ofreciendo a las herramientas de IA un punto de partida mucho mejor para diseñar fármacos biológicos más precisos y efectivos.
Cita: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Palabras clave: diseño de anticuerpos, nanocuerpos, afinidad de unión, terapéuticos biológicos, IA para el descubrimiento de fármacos