Clear Sky Science · es
Conjunto de datos PreprintToPaper: conectando preprints de bioRxiv con publicaciones en revistas
Por qué la investigación temprana nos importa a todos
Mucho antes de que un descubrimiento científico aparezca en una revista de gran formato, a menudo se publica como un “preprint”: una versión temprana y de libre acceso del trabajo. Durante la pandemia de COVID‑19, estos preprints marcaron titulares, debates públicos e incluso políticas sanitarias. Sin embargo, ha sido sorprendentemente difícil rastrear qué estudios tempranos se convirtieron después en artículos formales de revista y cuáles no lo hicieron. Este artículo presenta el conjunto de datos PreprintToPaper, un mapa amplio y cuidadosamente verificado que vincula los preprints de ciencias de la vida en el servidor bioRxiv con sus publicaciones finales en revistas, ofreciendo al público, a periodistas y a investigadores una visión más clara de cómo los hallazgos iniciales transitan por el sistema científico.
Siguiendo el recorrido del borrador al artículo
Los autores se centraron en bioRxiv, un servidor en línea importante donde los investigadores de ciencias de la vida publican preprints. Reunieron información sobre 145.517 preprints de dos ventanas temporales clave: 2016–2018, antes de la pandemia de COVID‑19, y 2020–2022, durante la intensa actividad editorial provocada por la pandemia. Para cada preprint registraron datos como el título, el resumen, los autores, las instituciones, el área temática, la licencia y las fechas de envío. Luego recurrieron a Crossref, un registro central de artículos de revistas, para obtener información coincidente sobre los artículos publicados: nombres de revistas, fechas de publicación y listas completas de autores. Al combinar estas fuentes construyeron un registro unificado y detallado que sigue un estudio desde su primera aparición pública como preprint hasta su forma final en una revista científica.
Clasificando los preprints en grupos claros
Para dar sentido a esta gran colección, el equipo clasificó cada preprint en uno de tres grupos. Los preprints “publicados” tenían un vínculo digital claro desde bioRxiv hacia un artículo de revista. Los elementos “Solo preprint” se publicaron en el servidor pero no mostraron indicios de haber sido publicados en otra parte. El grupo más intrigante, llamado la “Zona Gris”, contiene casos que parecen haber sido publicados en una revista pero carecen de un enlace oficial en bioRxiv. Para capturar cómo cambian los preprints con el tiempo, los investigadores también elaboraron un archivo separado de historial de versiones que lista cada versión disponible para los preprints que tuvieron una versión original y al menos una actualización posterior. Esto permite a otros estudiar cómo evolucionan los títulos, las listas de autores y otros detalles entre el primer borrador y la última versión del preprint.
Detectando coincidencias ocultas y verificándolas manualmente
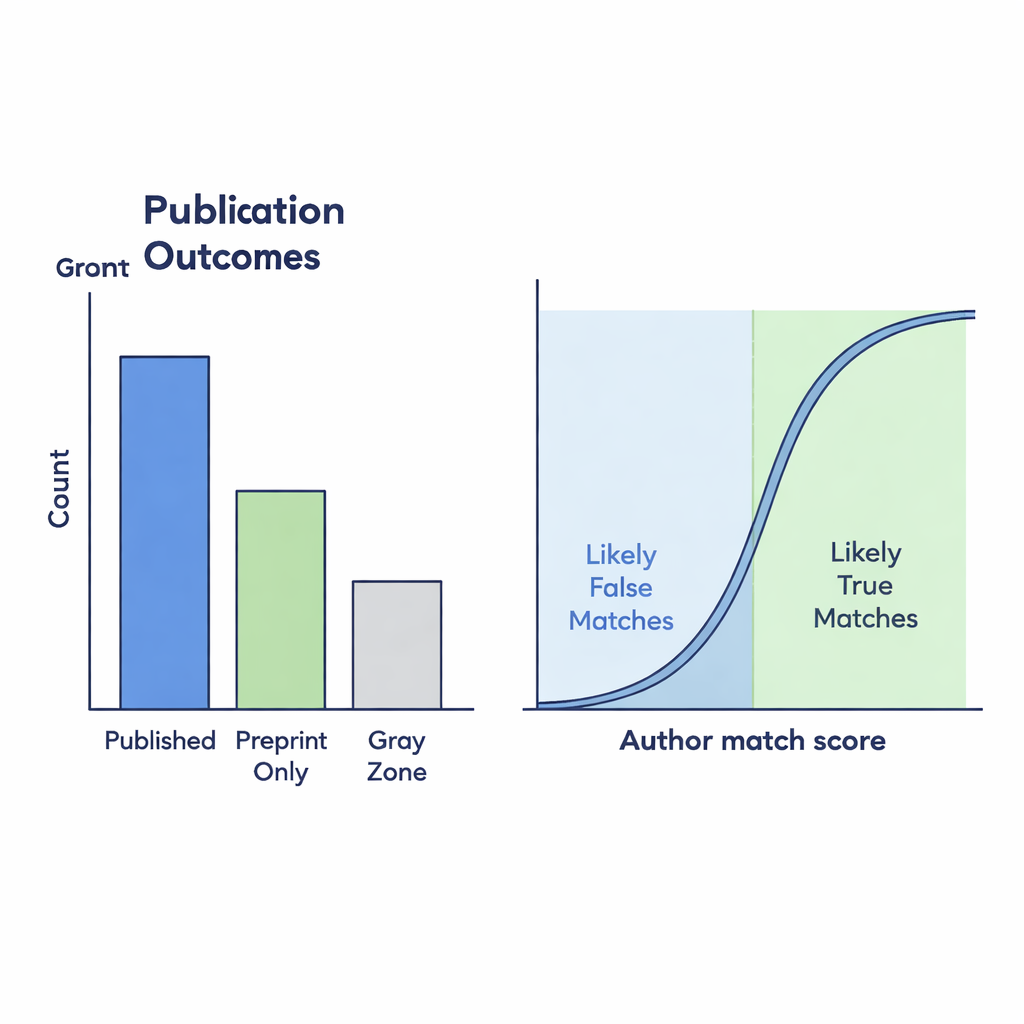
Muchos preprints que en realidad están publicados nunca reciben un enlace de retorno adecuado en bioRxiv, lo que crea puntos ciegos para quien intenta rastrear la producción científica. Para descubrir estas conexiones faltantes, los autores compararon los títulos y las listas de autores de los preprints con los registros de revistas en Crossref. Usaron una puntuación de similitud entre 0 y 1 para medir cuánto coinciden dos títulos; los posibles enlaces de la Zona Gris necesitaban una puntuación de al menos 0,75. Luego refinaron estos candidatos con medidas basadas en los autores: cuán diferentes eran los recuentos de autores y cuán similares parecían los nombres. Para comprobar si estas reglas automatizadas eran fiables, dos anotadores humanos examinaron manualmente 299 casos limítrofes. Sus juicios concordaron con fuerza, y un modelo estadístico mostró que cuando las listas de autores coincidían bien, era muy probable que el supuesto enlace fuera genuino.
Qué revelan los números sobre la producción científica
El conjunto de datos final muestra cómo los patrones de prepublicación y publicación cambiaron antes y durante la pandemia. En conjunto, contiene más de 90.000 preprints claramente publicados, más de 35.000 que parecen permanecer sólo en el servidor y alrededor de 19.000 casos de la Zona Gris donde el enlace a un artículo de revista requirió trabajo de detective. Cuando solo se cuenta el grupo oficialmente vinculado de “Publicados”, parece que una proporción mucho menor de preprints se convierte en artículos de revista con el tiempo. Pero cuando se incluyen los emparejamientos probables de la Zona Gris—aquellos con fuerte similitud de autores—la caída en las tasas de publicación es mucho menos pronunciada. Esto sugiere que los enlaces faltantes en la infraestructura subyacente pueden inducir a error sobre cómo está cambiando el panorama científico.
Por qué este recurso es útil más allá de los especialistas
Para los no especialistas, el mensaje principal es que los resultados científicos tempranos no desaparecen en una caja negra. Con el conjunto de datos PreprintToPaper es posible ver qué hallazgos publicados rápidamente sobreviven finalmente a la revisión por pares, cuánto tiempo tarda ese recorrido y qué tipos de estudios nunca abandonan la etapa de preprint. Los responsables de políticas pueden usar esta información para juzgar qué tan bien funcionan las prácticas de ciencia abierta; los periodistas pueden evaluar mejor la solidez de un resultado; y los investigadores pueden construir herramientas que filtren y resuman el abrumador flujo de artículos. En resumen, este conjunto de datos convierte una avalancha caótica de investigación temprana en un registro más trazable y responsable de cómo las ideas pasan de la primera publicación a la publicación pulida.
Cita: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Palabras clave: preprints, publicación científica, ciencia abierta, investigación sobre COVID-19, bibliometría