Clear Sky Science · es
Multi-TPC: Un conjunto de datos multimodal para conversaciones de tres personas con habla, movimiento y mirada
Por qué importan cómo nos movemos y miramos al hablar
Cuando las personas hablan cara a cara, hacen mucho más que intercambiar palabras. Nos inclinamos hacia adelante, asentimos, nos miramos y hacemos pausas en los lugares precisos. Estos gestos sutiles se vuelven aún más importantes cuando tres personas conversan a la vez, ya que la atención y los turnos de palabra cambian constantemente. Sin embargo, hasta ahora, científicos e ingenieros han disponido de muy pocos datos de alta calidad que muestren cómo el habla, el movimiento corporal y la mirada funcionan conjuntamente en conversaciones de pequeños grupos. Este artículo presenta un nuevo conjunto de datos diseñado para cubrir esa laguna y ayudar a construir asistentes virtuales más naturales, robots sociales y herramientas para estudiar la interacción humana cotidiana.
Una nueva ventana a las conversaciones de tres personas
Los autores presentan Multi-TPC, una colección pública de conversaciones de tres personas grabadas en laboratorio mediante captura de movimiento, rastreadores oculares y micrófonos individuales. A diferencia de muchos recursos anteriores que se centran en un solo hablante o en conversaciones entre solo dos personas, Multi-TPC captura discusiones espontáneas entre tres desconocidos que se sitúan en un triángulo y hablan sobre el tema que prefieran. Se incluyen más de 5,3 horas de grabaciones de 21 participantes jóvenes adultos, divididas en 24 sesiones. Para cada instante de estas conversaciones, el conjunto de datos ofrece información detallada sobre cómo habla cada persona, cómo mueve su cuerpo y hacia dónde dirige su mirada.
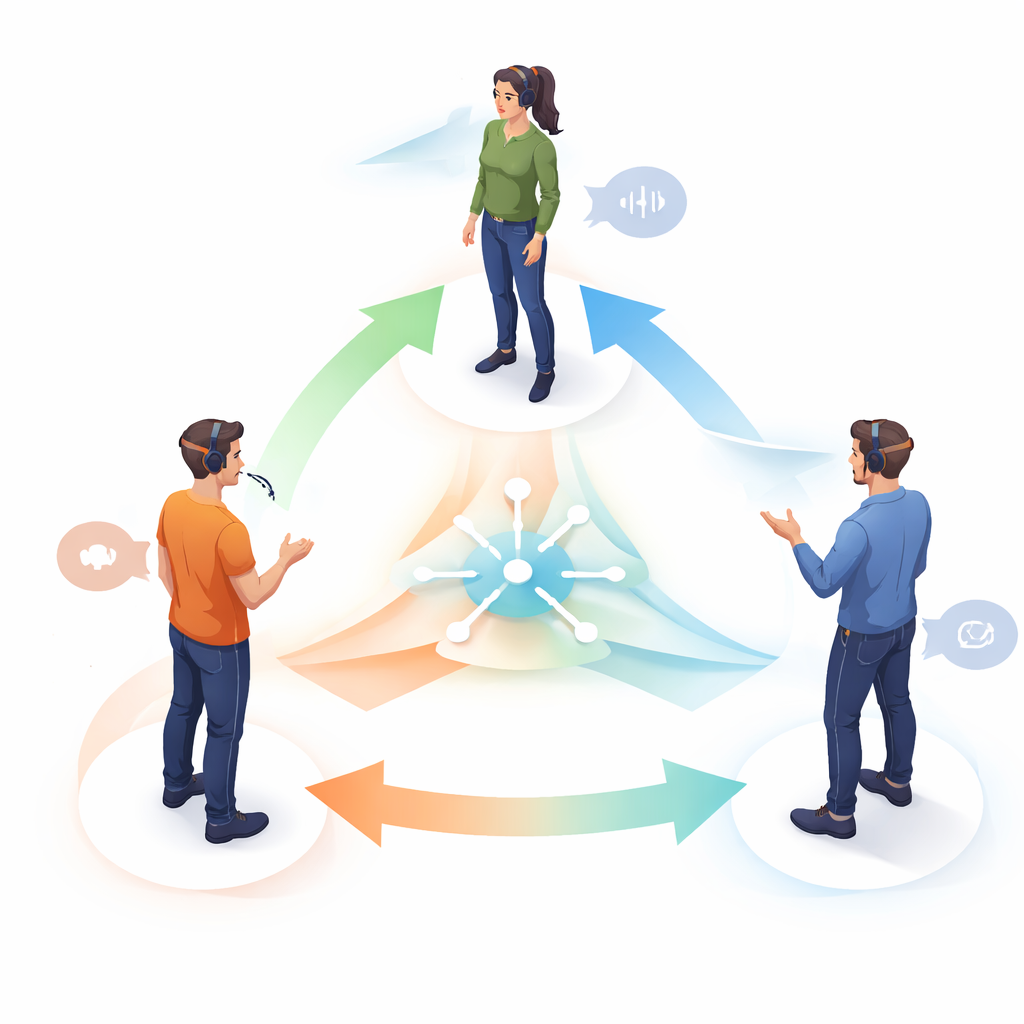
Cómo se capturaron las conversaciones
Para construir este conjunto de datos, el equipo creó una configuración de grabación híbrida. Cada participante vistió un traje de captura de movimiento de cuerpo entero con marcadores reflectantes para que una matriz de ocho cámaras pudiera rastrear su postura, el movimiento de la cabeza y los gestos en tres dimensiones. Gafas ligeras de seguimiento ocular, similares en sensación a unas gafas normales, midieron hacia dónde miraba cada persona en su campo visual. Micrófonos inalámbricos sujetos cerca del cuello grabaron la voz de cada hablante en pistas de audio separadas. Antes de grabar, los participantes fueron calibrados en el sistema e instruidos para permanecer en posiciones fijas formando un triángulo equilátero a aproximadamente un metro de distancia. Un clapboard, visible para las cámaras, los rastreadores oculares y los micrófonos, proporcionó una señal precisa para alinear todos los dispositivos en el tiempo, garantizando que movimiento, mirada y habla pudieran coincidir cuadro por cuadro.
Limpieza, organización y enriquecimiento de los datos
Recoger señales crudas fue solo el primer paso. Los investigadores procesaron cuidadosamente los datos de movimiento, etiquetando todos los marcadores y rellenando pequeños huecos mediante interpolación matemática mientras verificaban las posiciones de marcadores cercanos. Las grabaciones de audio se limpiaron con métodos de reducción de ruido y luego se introdujeron en software de reconocimiento de voz para generar transcripciones palabra por palabra, que más tarde se corrigieron manualmente. Los puntos de mirada medidos en píxeles de cámara se convirtieron en ángulos 3D que muestran hacia dónde miraba cada persona en el espacio. Todas las señales se muestrearon a 60 fotogramas por segundo y se sincronizaron, para luego almacenarse en formatos simples y abiertos. El conjunto de datos final está organizado por modalidad—movimiento, mirada, audio, palabras y características prosódicas como intensidad y tono—con reglas claras de nomenclatura de archivos para que los investigadores puedan rastrear fácilmente cualquier instante en el tiempo a través de los tres participantes.
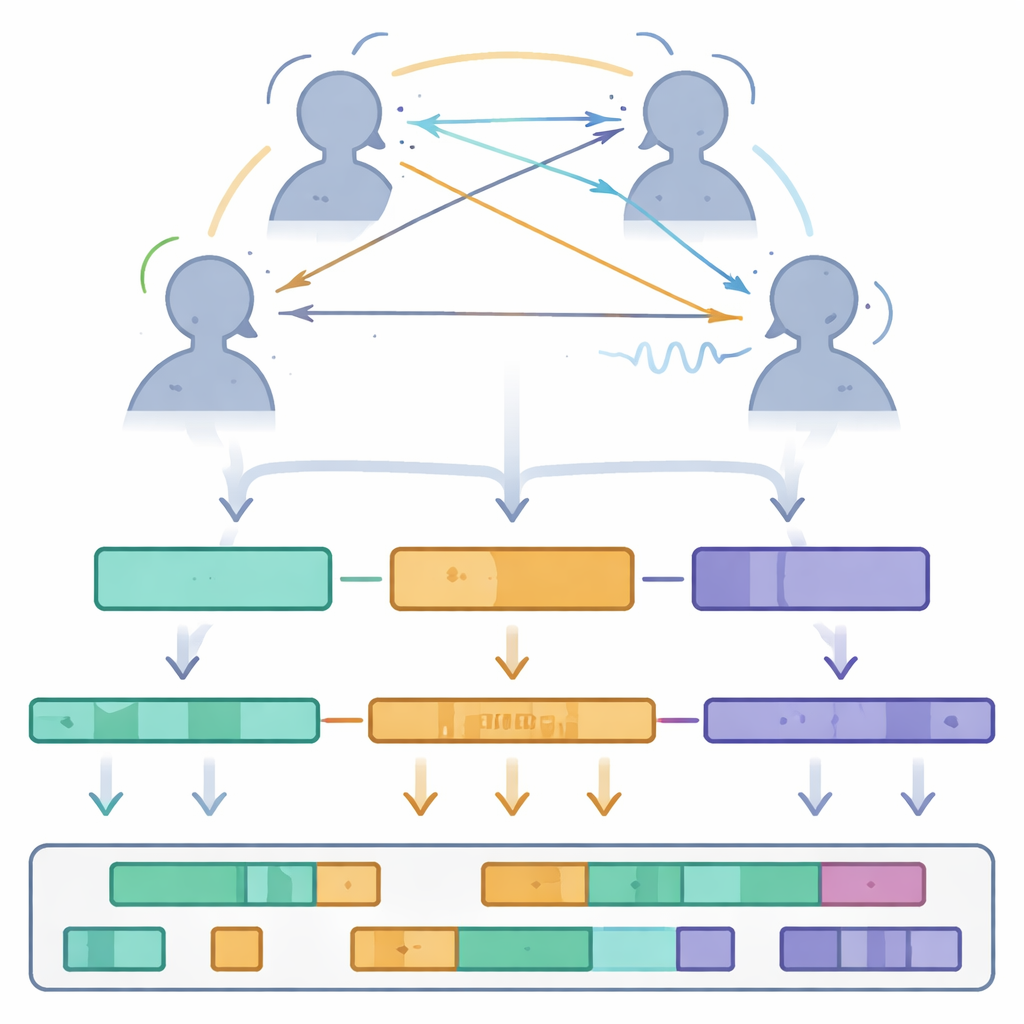
Qué revela el conjunto de datos sobre la conversación en grupo
Utilizando Multi-TPC, los autores realizaron un recorrido estadístico inicial sobre cómo se desarrollan las conversaciones de tres personas. Midieron los turnos de palabra y los silencios, encontrando que un turno típico dura aproximadamente 2,7 segundos, separados por pausas de poco más de un segundo. También examinaron los asentimientos y negaciones de cabeza como forma de retroalimentación del oyente, detectando aproximadamente un cuarto de asentimiento o negación por segundo en promedio—evidencia de que los oyentes señalan constantemente atención y actitud sin decir una palabra. El análisis de la mirada mostró que las personas rara vez fijan la vista directamente en la cara de otro por mucho tiempo. En su lugar, a menudo miran ligeramente de lado, y sus patrones de mirada cambian según quién esté hablando, si hay una pausa o si más de una persona habla a la vez. Durante el solapamiento del habla, la mirada de los participantes tiende a distribuirse más uniformemente o a alejarse de ambos interlocutores, lo que sugiere incertidumbre sobre quién tiene el turno de la conversación.
Por qué este recurso importa para la tecnología futura
Al empaquetar todas estas capas de información en un conjunto de datos bien documentado y compartible, Multi-TPC ofrece una nueva base para estudiar cómo los pequeños grupos gestionan los turnos de palabra, la atención y la retroalimentación mediante palabras y movimiento. Para los lectores en general, la conclusión es que la danza de la conversación—quién habla cuándo, quién mira dónde y cómo los sutiles asentimientos moldean el flujo—ahora está capturada en detalle fino. Para científicos y desarrolladores, esto abre la puerta a crear personajes virtuales y robots sociales que respondan más parecido a las personas reales en contextos grupales, así como a estudios más profundos sobre cómo nos coordinamos entre nosotros mediante la voz, el cuerpo y la mirada.
Cita: Lee, MC., Deng, Z. Multi-TPC: A Multimodal Dataset for Three-Party Conversations with Speech, Motion, and Gaze. Sci Data 13, 429 (2026). https://doi.org/10.1038/s41597-026-06819-x
Palabras clave: conversación multimodal, gesto y mirada, conjunto de datos de interacción social, turnos de palabra, agentes virtuales