Clear Sky Science · es
Un conjunto de datos a gran escala de células de sangre periférica para el análisis hematológico automatizado
Por qué importan las imágenes de células sanguíneas
Cada análisis de sangre de rutina oculta un mundo microscópico de células que puede revelar infecciones, anemia o incluso leucemias mucho antes de que los síntomas sean evidentes. Tradicionalmente, los médicos inspeccionan estas células a simple vista bajo el microscopio, una labor cuidadosa pero que consume mucho tiempo. Este estudio presenta una colección muy grande y cuidadosamente etiquetada de imágenes de células sanguíneas diseñada para enseñar a los ordenadores a reconocer estas células de forma automática. El objetivo es que las futuras pruebas sanguíneas sean más rápidas, consistentes y accesibles, proporcionando a la inteligencia artificial la experiencia visual que necesita para ayudar a los médicos a leer frotis sanguíneos con precisión.
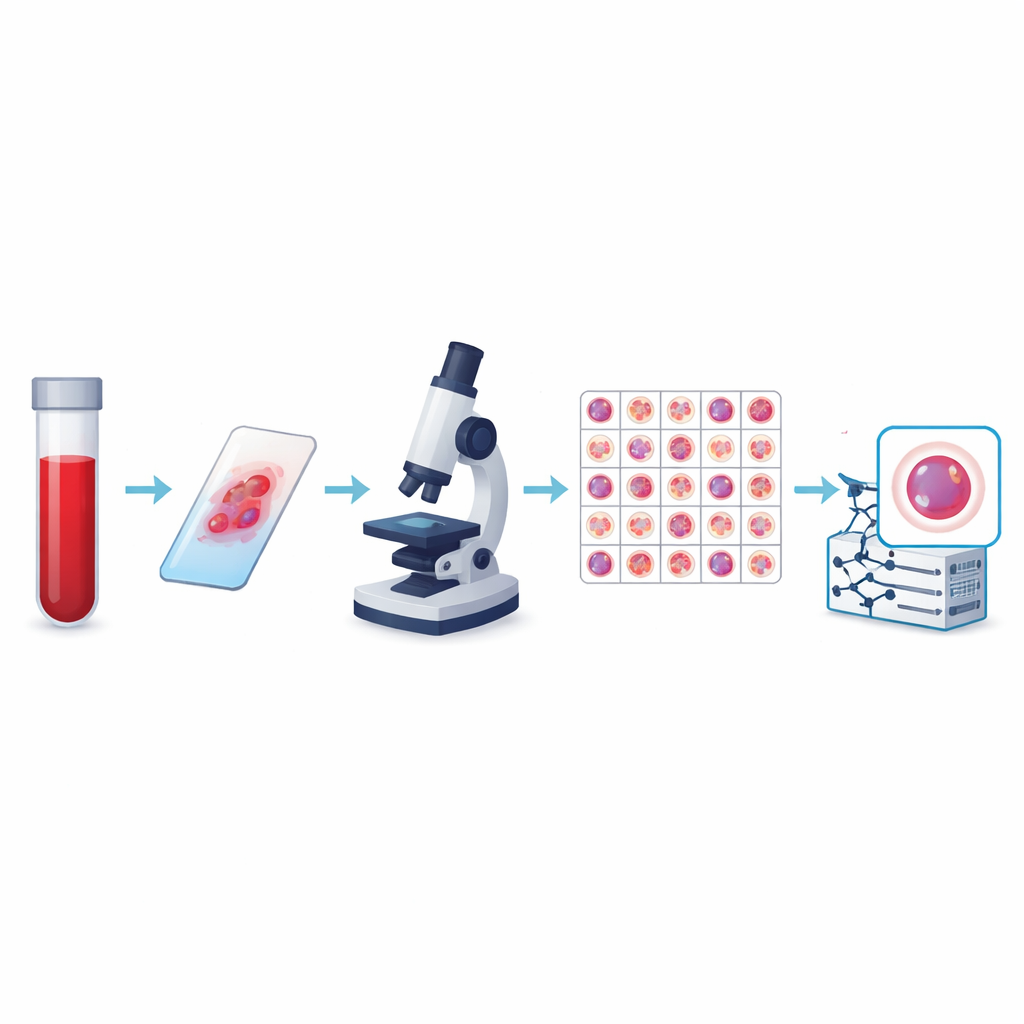
De los recuentos simples a la imagen inteligente
Los glóbulos blancos son defensores clave de nuestro sistema inmunitario, y su proporción y aspecto ofrecen pistas cruciales sobre nuestra salud. Un aumento en ciertos tipos celulares puede señalar infección o alergia, mientras que la aparición repentina de células inmaduras “blastos” puede advertir de una leucemia. Los laboratorios ya usan máquinas automáticas para contar células, pero los cambios sutiles de forma siguen requiriendo a menudo el ojo de un experto. Los revisores humanos pueden discrepar, y examinar portaobjetos uno por uno consume tiempo. A medida que la medicina depende más de la imagen digital y la inteligencia artificial, crece la necesidad de colecciones de imágenes grandes y fiables que puedan entrenar a los ordenadores para detectar estos patrones celulares tan característicos con la misma fiabilidad que un hematólogo experimentado.
Construyendo una enorme biblioteca de células sanguíneas
Los autores crearon lo que actualmente es la mayor colección pública de imágenes de células de sangre periférica, denominada conjunto de datos KU-Optofil PBC. Contiene 31.489 imágenes en alta resolución de células individuales distribuidas en 13 grupos, incluidos defensores comunes como linfocitos y neutrófilos segmentados, así como tipos más raros pero médicamente críticos como blastos, mielocitos y linfocitos reactivos. Todas las imágenes provienen de frotis sanguíneos teñidos preparados bajo condiciones estandarizadas en un único hospital utilizando el mismo sistema de imagen. Esta coherencia significa que los ordenadores que aprenden a partir de los datos ven una visión estable y bien controlada de cada tipo celular en lugar de un mosaico de imágenes incompatibles.
Ojos expertos y curación cuidadosa
Para que el conjunto de datos fuera fiable, cada imagen fue etiquetada de forma independiente por dos técnicos de laboratorio experimentados, y un tercer experto resolvió las discrepancias. Los controles estadísticos mostraron un acuerdo muy alto entre los revisores para cada tipo celular principal, incluyendo acuerdo perfecto en algunos casos. El equipo también aplicó reglas estrictas para decidir qué imágenes conservar, descartando células borrosas, superpuestas o mal teñidas. Las imágenes finales tienen todas el mismo tamaño y formato de color, y están organizadas en carpetas de entrenamiento, validación y prueba para que otros investigadores puedan comparar algoritmos de forma justa. Archivos adicionales vinculan cada imagen con un paciente anónimo, lo que permite estudios que comprueben si un modelo realmente generaliza de una persona a otra.
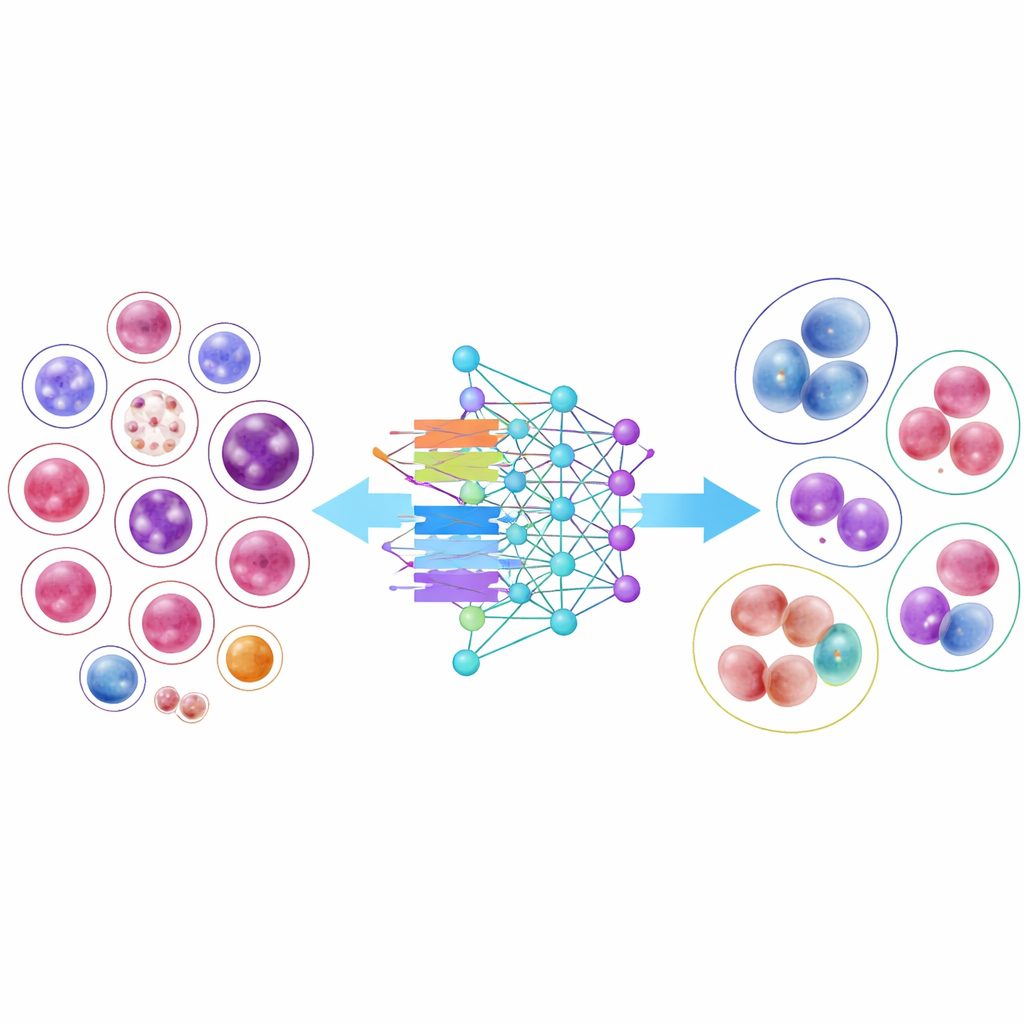
Poniendo a prueba modelos de IA
Para demostrar la utilidad de esta biblioteca, los investigadores entrenaron 14 modelos modernos de reconocimiento de imágenes, desde redes neuronales convolucionales clásicas hasta diseños más recientes basados en transformadores. Varios modelos compactos y eficientes funcionaron sorprendentemente bien, y una arquitectura, DenseNet-121, clasificó correctamente las células más del 95 por ciento de las veces en promedio. Sin embargo, los resultados también pusieron de manifiesto una dificultad importante en el mundo real: los tipos celulares comunes con miles de ejemplos se reconocieron casi a la perfección, mientras que las células muy raras con sólo unas pocas decenas de imágenes siguieron siendo mucho más difíciles de clasificar. Incluso cuando los investigadores ajustaron el entrenamiento para “prestar más atención” a estas clases escasas, la precisión global descendió y las mejoras en las clases raras fueron modestas, subrayando el desafío de aprender a partir de ejemplos limitados.
Qué supone esto para las futuras pruebas sanguíneas
Para no especialistas, el mensaje clave es que este trabajo proporciona la experiencia visual cruda que los sistemas informáticos necesitan para convertirse en socios fiables en la lectura de frotis sanguíneos. Al ensamblar una biblioteca grande, diversa y cuidadosamente comprobada de imágenes de células sanguíneas y mostrar que muchos modelos de IA diferentes pueden aprender de ella, los autores sientan las bases para herramientas que podrían acelerar el diagnóstico, reducir el error humano y llevar análisis a nivel de experto a clínicas con menos especialistas. Al mismo tiempo, los resultados mixtos en tipos celulares raros nos recuerdan que incluso los conjuntos de datos grandes tienen puntos ciegos, y que mejorar la atención de pacientes con enfermedades inusuales o en fases tempranas requerirá ampliar y refinar aún más estas colecciones de imágenes.
Cita: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Palabras clave: imágenes de células sanguíneas, IA médica, hematología, aprendizaje profundo, conjuntos de datos médicos