Clear Sky Science · es
Un conjunto de imágenes histopatológicas de alta magnificación para el diagnóstico y pronóstico del carcinoma escamocelular oral
Por qué importa esta investigación
El cáncer oral puede esconderse a plena vista, comenzando como una pequeña llaga en la boca y convirtiéndose en una enfermedad potencialmente mortal. Los médicos dependen de imágenes microscópicas del tejido para decidir la gravedad de un tumor y la probabilidad de que reaparezca o se disemine, pero interpretar estas imágenes es un trabajo lento y exigente. Este estudio presenta una nueva colección rica de imágenes diseñada para ayudar a los sistemas de inteligencia artificial (IA) a leer estas preparaciones junto a los patólogos, con el objetivo a largo plazo de proporcionar a los pacientes respuestas más rápidas y precisas sobre su enfermedad y las opciones de tratamiento.
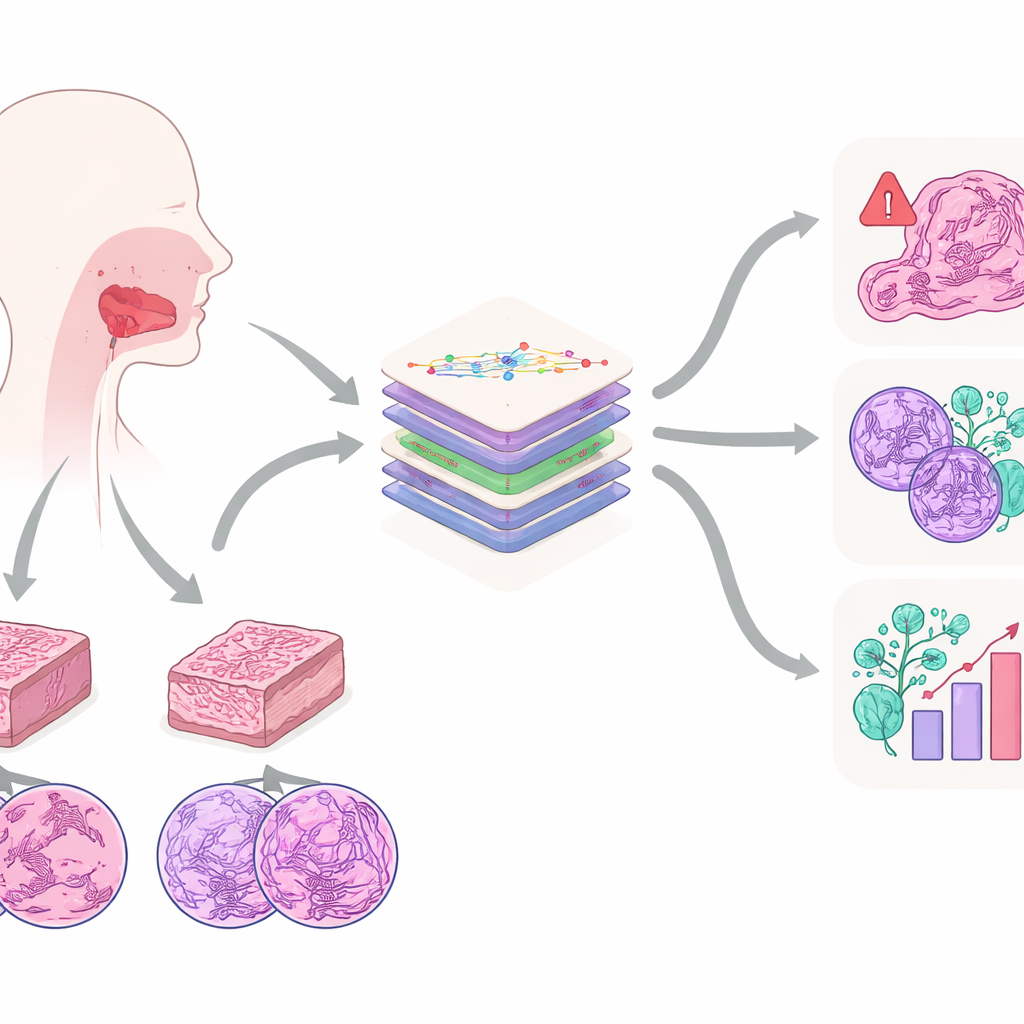
Una mirada más cercana a un cáncer de boca común
El trabajo se centra en el carcinoma escamocelular oral, uno de los cánceres de la boca más frecuentes y agresivos. Suele aparecer en personas con antecedentes de consumo de tabaco o alcohol y puede propagarse a tejidos cercanos y a los ganglios linfáticos del cuello. Hoy en día, el estándar de oro para el diagnóstico sigue siendo la evaluación del patólogo sobre cortes teñidos bajo el microscopio. A partir de estos cortes, los expertos juzgan cuán anormales se ven las células, qué tan profundamente ha crecido el tumor, si ha invadido nervios o vasos sanguíneos y muchas otras características que influyen en la supervivencia. Los autores sostienen que estos patrones microscópicos contienen mucha más información de la que cualquier humano puede seguir fácilmente, lo que los convierte en un objetivo ideal para la IA moderna.
Construyendo una imagen más completa a partir de las muestras de tejido
Para desbloquear esta información, el equipo creó el conjunto de datos Multi-OSCC: imágenes microscópicas de 1.325 pacientes tratados por cáncer oral en un único hospital entre 2015 y 2022. Para cada paciente, los patólogos prepararon dos bloques de tejido—uno del centro del tumor y otro de su borde invasivo—y capturaron imágenes de alta resolución en tres niveles de aumento, similar a ver una ciudad desde un avión, una azotea y una esquina de la calle. Esto produjo seis imágenes cuidadosamente seleccionadas por paciente, cada una conteniendo estructuras clave como nidos de células cancerosas, remolinos de queratina y núcleos celulares muy anormales. Junto con las imágenes, los investigadores recopilaron historias clínicas detalladas y seguimiento a largo plazo para ver qué tumores recurrieron o se diseminaron.
Seis preguntas que realmente importan a los médicos
Lo que distingue a Multi-OSCC es que refleja preguntas clínicas reales en lugar de centrarse en una única etiqueta. Cada paciente del conjunto de datos está anotado para seis resultados importantes. Uno es si el tumor recurrió dentro de los dos años posteriores a la cirugía, una ventana crítica en la que se producen la mayoría de las recaídas. Otro es si las células cancerosas ya habían alcanzado los ganglios linfáticos del cuello, lo que guía decisiones sobre cirugías cervicales más extensas. Cuatro etiquetas adicionales capturan qué tan bien diferenciadas están las células tumorales, la profundidad de la invasión tumoral y si ha entrado en vasos sanguíneos o crecido a lo largo de nervios—pistas sutiles pero poderosas sobre la amenaza que representa el cáncer. Este diseño permite a los modelos de IA aprender no solo “cáncer versus normal”, sino un retrato más completo del riesgo y la gravedad.
Enseñando a la IA a leer preparaciones complejas
Los investigadores evaluaron entonces cómo distintas estrategias de IA manejan este exigente conjunto de datos. Compararon varios backbones modernos de reconocimiento de imágenes, incluyendo redes convolucionales clásicas y modelos más nuevos basados en transformadores, y encontraron que los transformadores preentrenados específicamente en imágenes de patología ofrecían el mejor rendimiento global. Probaron formas de combinar la información de las seis imágenes por paciente y descubrieron que una estrategia simple—extraer características de cada imagen y luego concatenarlas—superó a esquemas de fusión más elaborados. También examinaron cómo la estandarización del color de las tinciones afectó el rendimiento, revelando que mantener el color original fue vital para predecir la recurrencia, mientras que una normalización suave del color ayudó en las otras tareas diagnósticas.
Límites, sorpresas y próximos pasos
Una sorpresa fue que entrenar un único modelo de IA para abordar las seis preguntas a la vez aún no superó a los modelos entrenados por separado para cada tarea. Otra fue que los fragmentos microscópicos detallados, aunque ricos en información celular, aún carecen de la visión arquitectónica amplia que proporcionan las imágenes de diapositiva completa. Aun así, los modelos entrenados con las imágenes de Multi-OSCC superaron claramente a los modelos que usaban solo datos clínicos como edad, hábitos e historial médico, especialmente para predecir la recurrencia tumoral. Los autores presentan Multi-OSCC como un punto de partida: un conjunto de datos público y bien documentado que otros pueden usar para desarrollar y comparar métodos. Para los pacientes, la promesa a largo plazo es que las herramientas futuras construidas sobre este recurso podrían ayudar a los médicos a identificar con mayor fiabilidad qué cánceres orales tienen probabilidad de volver o diseminarse, permitiendo tratamientos más personalizados y, en última instancia, mejores probabilidades de supervivencia.
Cita: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Palabras clave: cáncer oral, imágenes histopatológicas, inteligencia artificial, aprendizaje profundo, conjuntos de datos de imágenes médicas