Clear Sky Science · es
StatLLM: Un conjunto de datos para evaluar el rendimiento de los grandes modelos de lenguaje en análisis estadístico
Por qué esto importa para los usuarios de datos cotidianos
A medida que las herramientas de inteligencia artificial, como los asistentes conversacionales, forman parte del trabajo diario, más personas les piden que procesen cifras, ejecuten experimentos y analicen datos. Pero cuando una IA escribe el código para un estudio estadístico —por ejemplo, para comprobar si un nuevo tratamiento médico funciona o para explorar datos de rendimiento escolar—, ¿cómo sabemos si lo hizo correctamente? Este artículo presenta StatLLM, un conjunto de datos público diseñado para probar qué tan bien los grandes modelos de lenguaje manejan tareas reales de análisis estadístico, ofreciendo a investigadores y profesionales una visión más clara de cuándo confiar en el código generado por IA y cuándo ser cautelosos.
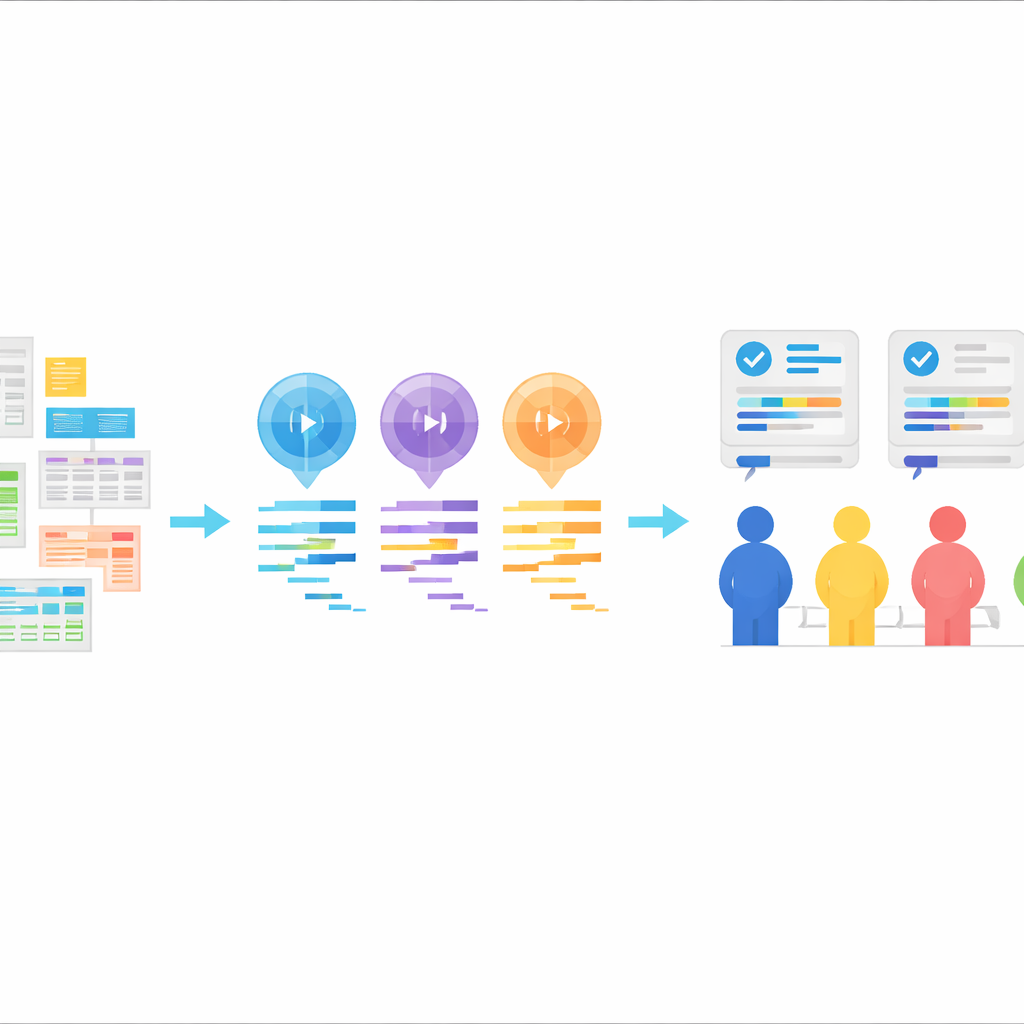
Un nuevo banco de pruebas para código estadístico generado por IA
El núcleo de StatLLM es una colección cuidadosamente ensamblada de 207 tareas de análisis estadístico construidas a partir de 65 conjuntos de datos reales procedentes de campos como educación, medicina, negocios, finanzas, ingeniería y deportes. Cada tarea incluye una descripción en lenguaje llano del problema, una explicación detallada del conjunto de datos y sus variables, y un breve fragmento de código SAS escrito y verificado por expertos humanos. Las tareas cubren lo que podría aprender un buen estudiante de grado o de máster en estadística: desde resúmenes de datos y gráficos sencillos hasta regresión, análisis de supervivencia y métodos más avanzados. Esto ofrece una prueba realista, tanto académica como industrial, sobre si las herramientas de IA pueden comprender preguntas prácticas y traducirlas en pasos de análisis sólidos.
Dejar que la IA escriba el código y luego calificar su trabajo
Usando estas tareas, los autores solicitaron a tres grandes modelos de lenguaje —GPT-3.5, GPT-4 y Llama‑3.1 70B— que generaran código SAS. Cada modelo recibió los mismos elementos: una descripción de la tarea, una descripción del conjunto de datos, el archivo de datos real y una instrucción explícita para producir código SAS. Los modelos se usaron en modo "zero-shot", lo que significa que no se les mostraron ejemplos de código SAS correcto previamente. Sus respuestas se limpiaron para que quedara solo el código, sin explicaciones. Esta configuración imita un patrón común en el mundo real: un usuario describe lo que quiere, la IA devuelve código y ese código se ejecuta en un paquete estadístico.
Expertos humanos como estándar de referencia
Para valorar la calidad real del código generado por la IA, el equipo organizó una revisión humana rigurosa. Nueve usuarios experimentados de SAS formaron tres grupos, cada uno centrado en una parte del rendimiento: si el código en sí era lógicamente correcto y legible, si realmente se ejecutaba sin errores y si la salida resultante respondía a la pregunta original de forma clara y precisa. Para cada tarea, los programas SAS de los tres modelos se barajaron para que los evaluadores no supieran qué modelo produjo cada código. Las puntuaciones se asignaron en una escala de cinco puntos y se combinaron en un total global, proporcionando una visión matizada de las fortalezas y debilidades a lo largo de cientos de pares modelo–tarea. Estas valoraciones de expertos ahora acompañan a todo el código y las tareas en el conjunto de datos StatLLM.
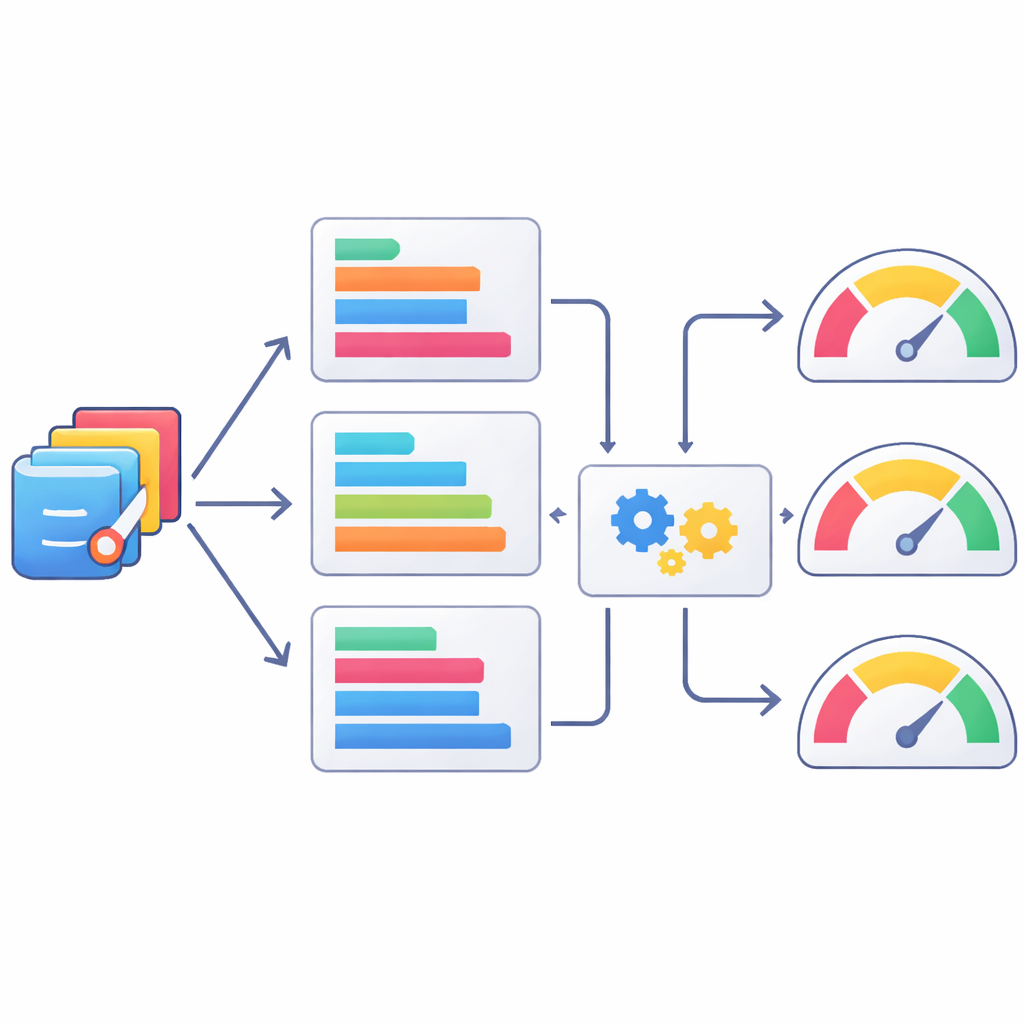
Enseñar a las máquinas a juzgar el código como lo hacen los humanos
Dado que la revisión humana es lenta y cara, los autores también exploraron qué tan bien los métricas automáticas basadas en texto pueden servir como jueces aproximados de la calidad del código estadístico. Compararon los programas SAS generados por IA con las versiones verificadas por humanos usando un conjunto de métricas bien conocidas en el procesamiento del lenguaje natural, y luego comprobaron cómo se alineaban estas puntuaciones con las valoraciones humanas. Algunas métricas, como variantes de la puntuación ROUGE que rastrean solapamientos en secuencias cortas de tokens, se correlacionaron mejor con los juicios humanos que otras, pero todas mostraron solo una alineación moderada. El equipo fue un paso más allá y entrenó modelos de aprendizaje automático para predecir las puntuaciones humanas a partir de combinaciones de estas métricas. Métodos como XGBoost mejoraron la concordancia con las valoraciones humanas, pero todavía quedaron lejos de capturar perfectamente el juicio de los expertos, lo que subraya que las puntuaciones automáticas son, en el mejor de los casos, proxies parciales.
Construyendo herramientas estadísticas impulsadas por IA para el futuro
Más allá del benchmarking, los autores muestran cómo StatLLM puede apoyar nuevas herramientas y líneas de investigación. Dado que cada tarea se describe en términos generales, los mismos problemas pueden usarse para probar la generación de código en otros lenguajes como R o Python, o incluso para combinar código de múltiples lenguajes. El artículo destaca enfoques en ensamblaje que podrían mezclar distintas soluciones generadas por IA para mayor fiabilidad y demuestra una aplicación prototipo en R Shiny donde los usuarios suben un conjunto de datos y la descripción de la tarea, y un sistema de IA produce y ejecuta automáticamente código en R. StatLLM también ofrece una plataforma para diseñar y evaluar software estadístico de próxima generación que entienda instrucciones en lenguaje natural y que pueda someterse a estándares claros y medibles.
Qué significa esto para el uso de la IA en el análisis de datos
Para los no especialistas, la principal conclusión es que la IA ya puede escribir fragmentos cortos de código estadístico, pero la fiabilidad está lejos de estar garantizada, especialmente en tareas que van más allá de ejemplos sencillos. StatLLM ofrece una forma transparente y reutilizable de ver qué tan bien rinden distintos modelos, mejorar las comprobaciones automáticas de su trabajo y diseñar herramientas de análisis de datos más seguras y robustas. A medida que aparezcan modelos de lenguaje más recientes, se podrán integrar en este benchmark viviente, manteniendo al campo honesto sobre lo que la IA puede y no puede hacer todavía en trabajos estadísticos serios.
Cita: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Palabras clave: grandes modelos de lenguaje, análisis estadístico, evaluación de código, conjunto de datos de referencia, programación SAS