Clear Sky Science · es
Un conjunto de datos de citas científicas en las Office Actions de la Oficina de Patentes de EE. UU.
Por qué las citas de patentes importan para la innovación cotidiana
Cuando oyes hablar de un nuevo dispositivo, medicamento o tecnología de energía limpia, suele existir un rastro de ideas detrás. Gran parte de ese rastro se registra en las patentes y en los documentos que citan. Este artículo presenta un nuevo y amplio conjunto de datos que revela, con un detalle inusual, en qué trabajos de investigación científica se apoyan los examinadores de patentes al decidir si una invención merece protección. Al abrir esta ventana oculta al proceso de examen, los autores ofrecen a investigadores, responsables de políticas e incluso a ciudadanos curiosos una nueva forma de estudiar cómo el conocimiento científico alimenta la innovación en el mundo real.
Una capa oculta en el proceso de patentes
La mayoría de los estudios sobre patentes solo consideran las citas que aparecen en la primera página de las patentes concedidas. Estas listas parecen sencillas, pero son el resultado final de un complejo ida y vuelta entre solicitantes y examinadores gubernamentales. En el proceso, los examinadores emiten cartas formales llamadas Office Actions, en las que explican por qué una patente debe aceptarse o rechazarse y hacen referencia a trabajos anteriores que consideran relevantes. Muchos de estos elementos citados, especialmente artículos científicos, nunca aparecen en la patente final. Hasta ahora han sido difíciles de acceder en bloque, lo que ha llevado a que la investigación ignore en gran parte este registro rico sobre cómo se toman realmente las decisiones.
Construyendo un nuevo mapa a partir de las Office Actions
Los autores aprovechan un tesoro de datos de Office Actions publicados por la Oficina de Patentes y Marcas de EE. UU. y alojados en Google Cloud. A partir de millones de referencias, aíslan alrededor de 850.000 que no apuntan a otras patentes, sino a fuentes externas como artículos de revistas, libros, sitios web y manuales de producto. Diseñan un esquema con 14 categorías de uso cotidiano—que van desde libros y actas de congresos hasta páginas web y documentación de productos—y luego entrenan un modelo de aprendizaje automático para clasificar cada cita en uno de estos tipos. Este modelo, refinado con ejemplos etiquetados con la ayuda de un avanzado sistema de lenguaje, clasifica cerca de 847.000 cadenas de cita únicas.
De referencias desordenadas a registros de investigación limpios
Identificar qué citas son científicas es solo el primer paso. Las referencias del mundo real son desordenadas: los títulos pueden estar incompletos, los años mal escritos y los números de página mezclados. Para convertir este enredo en datos utilizables, el equipo introduce las cadenas crudas en una herramienta especializada que las analiza en piezas como autor, año, revista y rango de páginas, aplicando a la vez reglas de limpieza cuidadosas. Luego emparejan estos registros limpiados con OpenAlex, una gran base de datos abierta de publicaciones de investigación, usando dos estrategias. Cuando hay título disponible, buscan por título y conservan solo coincidencias de alta confianza; cuando no lo hay, se basan en combinaciones de nombres de autores, revista, año y páginas. Si OpenAlex no encuentra una coincidencia, recurren a Crossref, otra fuente principal de identificadores de publicaciones, y vuelven a OpenAlex usando los identificadores digitales (DOI) que encuentren.
¿Qué tan fiable es el nuevo conjunto de datos?
Dado que este recurso pretende sustentar estudios futuros, los autores dedican un esfuerzo sustancial a probar su precisión. Su clasificador asigna correctamente las referencias al tipo correcto en aproximadamente el 92 por ciento de los casos en general, y funciona especialmente bien en las clases más comunes, como artículos de revista y patentes. Para el paso de emparejamiento, comprobaciones manuales muestran que las búsquedas basadas en título se vuelven más precisas a medida que aumenta la puntuación de coincidencia, alcanzando percentiles en los años noventa medios en el mejor grupo, mientras que las búsquedas basadas en metadatos detallados son correctas en el 99 por ciento de las ocasiones en una muestra. Las comprobaciones cruzadas de registros recuperados a través de Crossref también muestran una concordancia casi perfecta. Los autores son transparentes respecto a puntos más débiles—como categorías raras tipo tesis o informes técnicos—y animan a los usuarios a refinar estas donde sea necesario.
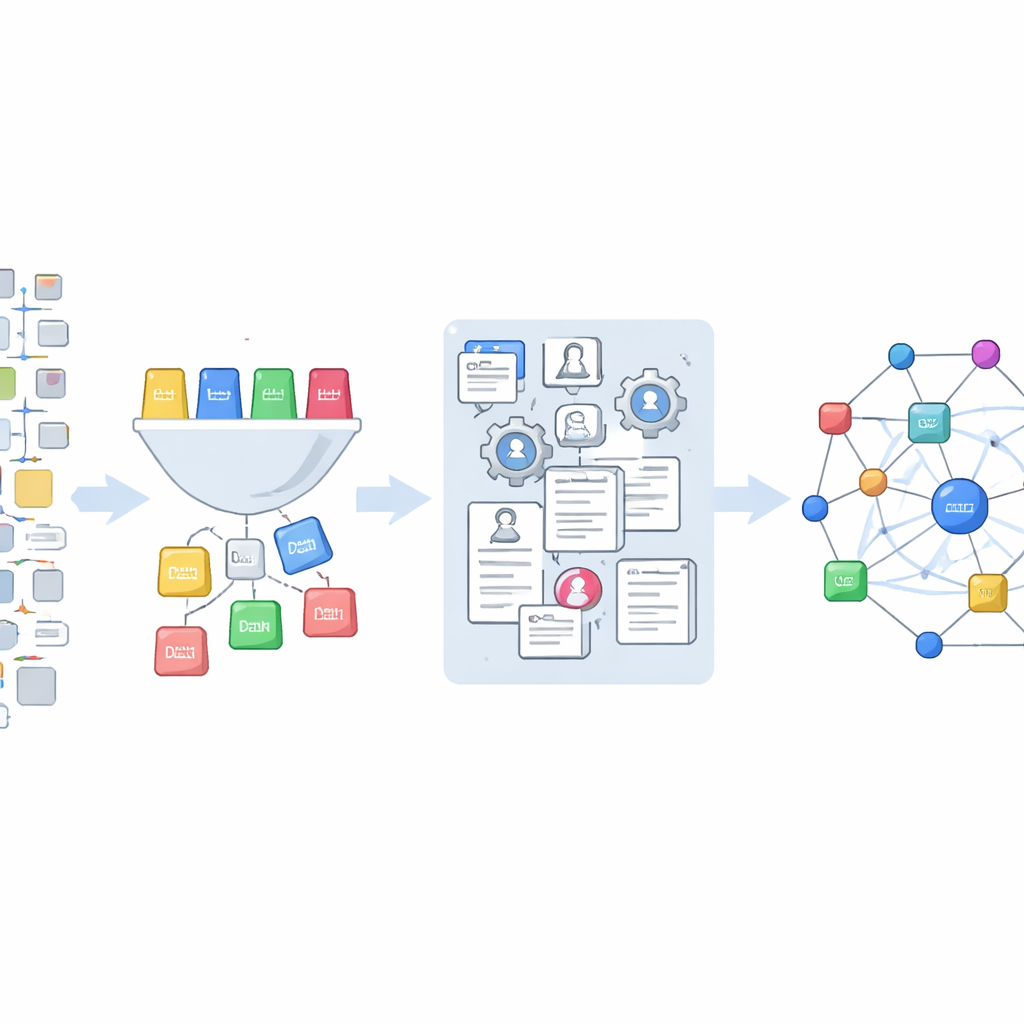
Nuevas formas de estudiar cómo la ciencia impulsa la tecnología
El conjunto de datos final vincula aproximadamente 265.000 referencias científicas extraídas de Office Actions con solicitudes de patentes individuales de EE. UU. y con completos registros de publicación en OpenAlex. Esto permite a los investigadores plantear nuevos tipos de preguntas: ¿Hasta qué punto distintos grupos de examinadores o áreas tecnológicas se apoyan en artículos científicos? ¿Qué estudios se consideran importantes durante el examen pero desaparecen de la patente final? ¿Las patentes abandonadas se nutren de una porción distinta del registro científico que las que tienen éxito? Dado que todo el código y los datos se publican abiertamente, otros pueden adaptar las herramientas, ampliar la cobertura y refinar las clasificaciones. En términos claros, este trabajo convierte un conjunto oscuro y disperso de documentos legales en un mapa claro y reutilizable de cómo se encuentran la ciencia y la tecnología dentro del sistema de patentes.
Cita: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Palabras clave: citas de patentes, office actions, literatura científica, datos de innovación, OpenAlex