Clear Sky Science · es
Un conjunto de datos de reconocimiento de entidades nombradas en chino para el patrimonio cultural inmaterial
Por qué proteger tradiciones vivas requiere una lectura inteligente
En todo el mundo, las tradiciones vivas, como la música popular, la artesanía y las fiestas locales, corren el riesgo de desaparecer de la vida cotidiana. En China existe ya una gran cantidad de textos que describen estas prácticas, pero la mayor parte permanece en páginas web extensas que resultan difíciles de buscar o analizar, tanto para las personas como para los ordenadores. Este estudio presenta un conjunto de datos en chino cuidadosamente elaborado y un modelo de inteligencia artificial avanzado que pueden detectar automáticamente piezas clave de información en esos textos, como nombres de oficios, maestros artesanos, materiales y lugares. Juntos, ofrecen nuevas herramientas para ayudar a preservar y estudiar el patrimonio cultural inmaterial a escala digital.
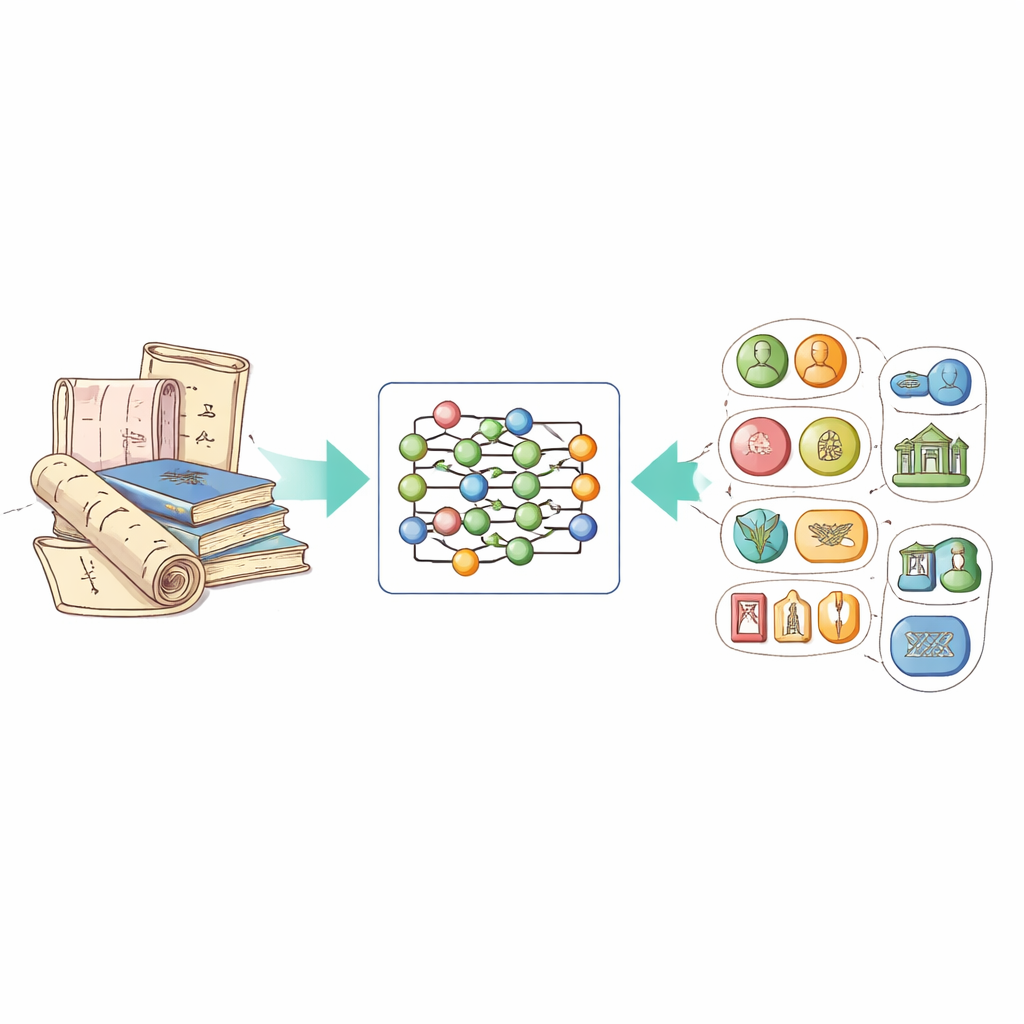
Convertir texto desordenado en conocimiento organizado
La idea central del trabajo es una tecnología llamada reconocimiento de entidades nombradas, que enseña a los ordenadores a resaltar elementos importantes en el texto: personas, ubicaciones, fechas, organizaciones, etc. Para el patrimonio cultural inmaterial, esto también implica reconocer tipos especiales de entidades, como los nombres de proyectos patrimoniales, técnicas artesanales específicas y los materiales que emplean. El problema es que, hasta ahora, no existía un conjunto de datos público adaptado a este dominio en chino, y los sistemas de uso general tenían dificultades con descripciones vívidas, lenguaje poético y expresiones regionales que aparecen en los documentos patrimoniales.
Construcción de una colección centrada en textos sobre patrimonio
Para cubrir este vacío, los autores reunieron un nuevo conjunto de datos, llamado ICH-NER, a partir de la Red de Patrimonio Cultural Inmaterial oficial de China. Se centraron en entradas relacionadas con la artesanía —como textiles tradicionales, cerámica, metalistería y talla— porque estas descripciones contienen abundantes detalles sobre procesos y materiales. Tras eliminar avisos y duplicados, diseñaron ocho categorías clave de entidades: nombres de bienes patrimoniales, ubicaciones, personas, organizaciones, períodos temporales, grupos étnicos, materiales y técnicas artesanales. Cada carácter chino en los textos fue etiquetado con un código simple que indica si forma parte de una entidad y, en caso afirmativo, de qué tipo. En total, el conjunto de datos contiene 7.779 muestras y más de 21.000 entidades etiquetadas, lo que lo convierte en un punto de referencia sólido para investigaciones futuras.
Reglas cuidadosas para un etiquetado coherente
Como no existía un sistema de clasificación estándar para este tipo de textos patrimoniales, los investigadores elaboraron primero directrices detalladas basadas en listas nacionales de patrimonio y descripciones oficiales. Realizaron una fase piloto para resolver casos complejos, como lugares que forman parte de nombres de proyectos o frases anidadas donde una entidad aparece dentro de otra. A continuación, un único anotador formado etiquetó todo el conjunto de datos usando software de código abierto, revisando repetidamente trabajos previos para corregir inconsistencias. Los datos finales se dividieron en conjuntos de entrenamiento y desarrollo, prestando atención a mantener proporciones similares de cada tipo de entidad y una buena mezcla de términos regionales y estilos de escritura en ambas partes.
Diseñar un modelo de IA afinado al lenguaje patrimonial
Junto con el conjunto de datos, el estudio propone un modelo de reconocimiento especializado que apila varios componentes modernos de IA. Primero, un codificador lingüístico potente (RoBERTa) convierte los caracteres chinos en representaciones numéricas contextuales que reflejan el uso de las palabras en su entorno. Después, un módulo de Red Kolmogórov–Arnold aprende patrones sutiles y no lineales —por ejemplo, cómo ciertos materiales suelen asociarse con técnicas o regiones concretas. Una capa de atención multi‑cabeza examina a continuación las relaciones a lo largo de toda la oración desde múltiples perspectivas, y finalmente una capa de decodificación elige la secuencia de etiquetas de entidad más probable. Esta arquitectura está diseñada para manejar oraciones largas y complejas llenas de metáforas y referencias culturales en capas.
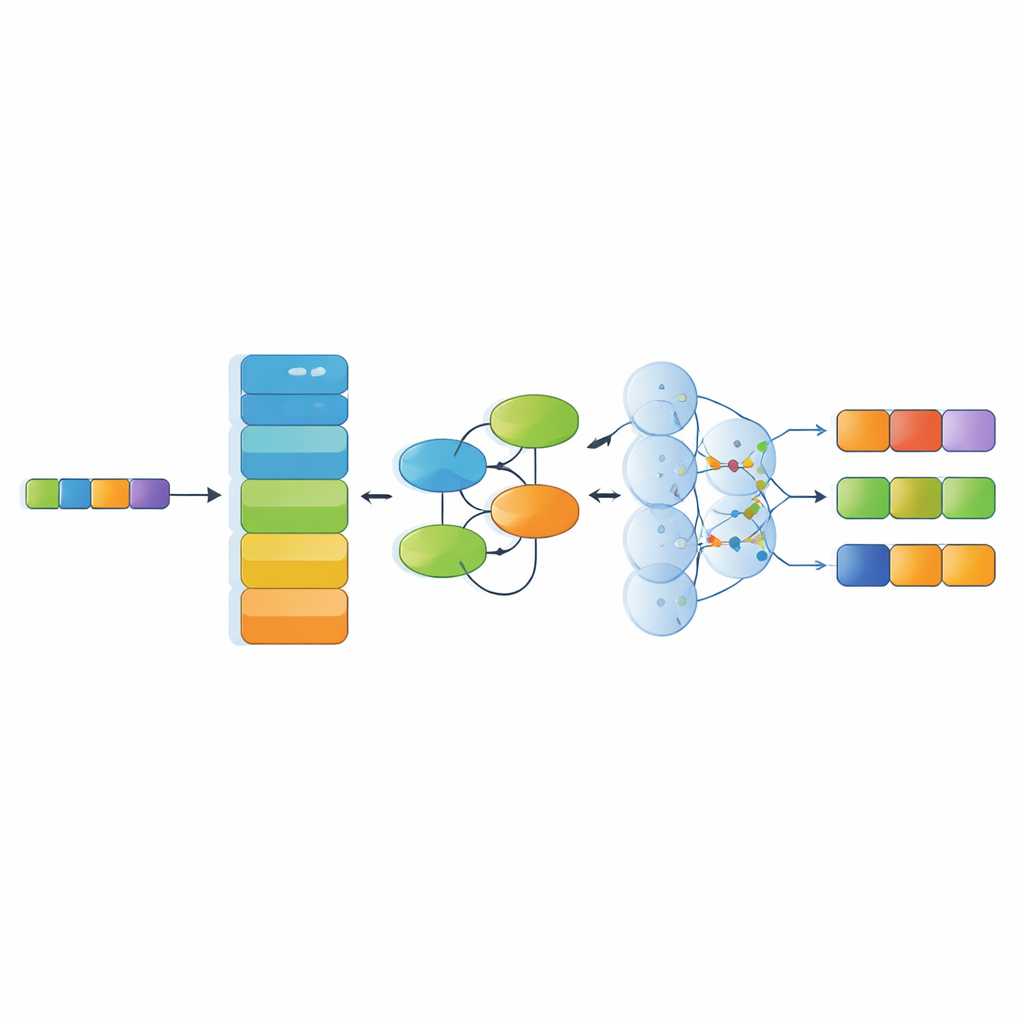
Qué tan bien entiende el sistema los textos patrimoniales
Los autores compararon su modelo con varias líneas base sólidas utilizadas comúnmente en investigación lingüística, incluidos sistemas basados en redes recurrentes, estructuras de entramado para texto chino y un método reciente que trata las entidades como segmentos refinados paso a paso. En el conjunto de datos ICH-NER, los métodos que se apoyan en modelos de lenguaje preentrenados modernos superaron claramente a los enfoques más antiguos. Su sistema combinado RoBERTa–KAN–atención–decodificador alcanzó el mejor equilibrio general entre precisión y exhaustividad, especialmente en categorías difíciles como materiales, organizaciones y técnicas artesanales, donde los datos son relativamente escasos y las descripciones a menudo son intrincadas o ambiguas.
Qué significa esto para la cultura viva en la era digital
En términos prácticos, el nuevo conjunto de datos y el modelo facilitan que los ordenadores identifiquen quién, qué, dónde y cuándo en descripciones ricas de oficios tradicionales. Esta información estructurada puede integrarse en grafos de conocimiento, mapas interactivos o herramientas de búsqueda que ayuden a investigadores, conservadores y al público a explorar cómo se difunden las técnicas, cómo determinadas familias o regiones modelan un oficio y cómo evolucionan las prácticas con el tiempo. Aunque el trabajo es técnico, su impacto es humano: ofrece una forma de convertir descripciones dispersas y ligadas al texto de tradiciones vivas en conocimiento organizado que puede respaldar mejor la preservación y la comprensión del patrimonio cultural inmaterial.
Cita: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Palabras clave: patrimonio cultural inmaterial, reconocimiento de entidades nombradas, procesamiento del lenguaje chino, conjuntos de datos culturales, preservación digital