Clear Sky Science · es
Manifiesto de Datos Biomédicos: una documentación de datos ligera que aumenta la transparencia para IA/ML
Por qué importan unas notas de datos más inteligentes para su salud
Mientras hospitales e investigadores se apresuran a usar la inteligencia artificial para predecir enfermedades y orientar tratamientos, la calidad de los datos que alimentan estas herramientas configura en silencio quién se beneficia y quién puede quedarse atrás. Este artículo presenta una forma práctica de “etiquetar la caja” para conjuntos de datos biomédicos, de modo que cualquier persona que construya sistemas de IA pueda ver rápidamente de dónde provienen los datos, a quién representan y cómo deben —y no deben— utilizarse. Al simplificar este tipo de documentación, los autores pretenden que la IA médica sea más justa, segura y más fácil de confiar.
Las historias ocultas dentro de los datos médicos
La mayoría de los grandes conjuntos de datos biomédicos —colecciones de resultados de laboratorio, imágenes o desenlaces de tratamientos— no se crearon pensando en la IA. A menudo carecen de registros claros sobre cómo se recopilaron los datos, qué pacientes se incluyeron o qué se modificó con el tiempo. Estos detalles ausentes pueden ocultar sesgos, como la infrarrepresentación de ciertos grupos o la grabación inconsistente de información clave. Cuando esos datos se usan para entrenar sistemas de aprendizaje automático, las herramientas resultantes pueden funcionar bien para algunos pacientes pero mal para otros, reforzando las brechas existentes en la atención. Los autores sostienen que una documentación mejor y estandarizada es esencial para descubrir y gestionar estos riesgos antes de desplegar algoritmos.
Combinando las mejores ideas en una guía simple
Ya existen varios enfoques de “hojas de datos” en la comunidad de IA, como Datasheets for Datasets, Data Cards y HealthSheets. Cada uno ofrece preguntas estructuradas sobre el propósito de un conjunto de datos, su contenido, métodos de recolección y límites. Sin embargo, fueron diseñados principalmente por científicos informáticos para conjuntos de datos específicos de IA y pueden ser largos y difíciles de completar para investigadores biomédicos ocupados. Para evitar reinventar la rueda, el equipo primero mapeó y armonizó campos de cuatro plantillas ampliamente citadas, construyendo una lista consolidada de 136 preguntas que capturaban los conceptos más importantes mientras eliminaban solapamientos. Luego refinaron esa lista hasta 100 campos agrupados en siete categorías intuitivas, que van desde información básica y cómo se usan los datos hasta cuestiones como ética, limitaciones legales y cómo se crearon las etiquetas.
Escuchando a las personas que usan y crean los datos
A continuación, los investigadores pidieron a partes interesadas biomédicas del mundo real —incluidos clínicos, científicos de laboratorio, gestores de datos y expertos computacionales— que valoraran cuán esencial era cada campo de documentación para su trabajo. Veintitrés participantes de una red de investigación sobre cáncer multicéntrica completaron la encuesta. El equipo agrupó a los encuestados en dos “personas” amplias: quienes están más cerca de la recolección de datos en el banco o la cabecera, y quienes gestionan, curan o analizan datos principalmente. Esto reveló diferencias claras en prioridades. Por ejemplo, ambos grupos valoraron mucho saber cuándo se actualizó por última vez un conjunto de datos y cuándo podría volver a cambiar. Pero solo los gestores de datos y los expertos computacionales priorizaron con fuerza detalles sobre cómo se asignaron las etiquetas o cómo serían las futuras actualizaciones, mientras que los clínicos y los científicos de laboratorio dieron más énfasis a los usos previstos e inapropiados de los datos.
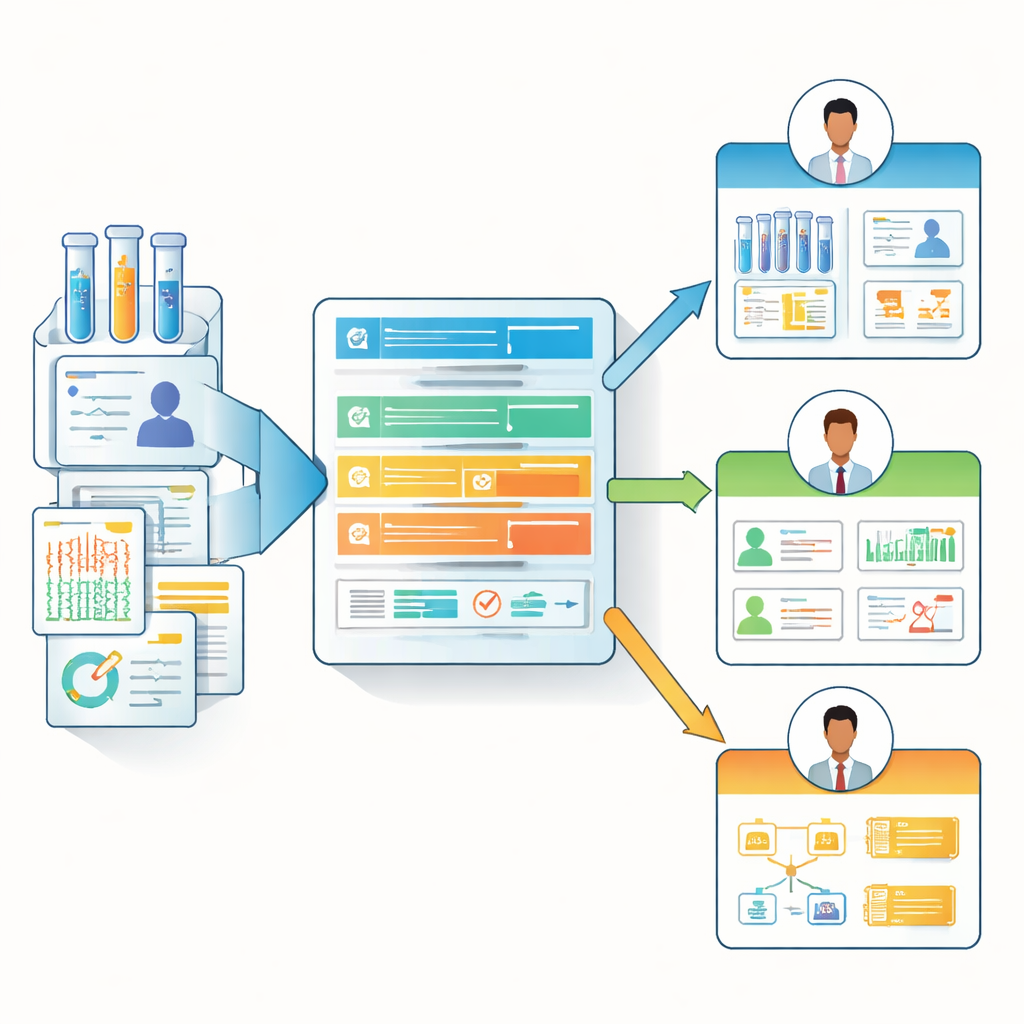
De talla única a notas de datos conscientes del rol
Basándose en estos hallazgos de la encuesta, los autores diseñaron el “Manifiesto de Datos Biomédicos”, una plantilla de documentación ligera basada en web que se adapta a distintos roles. En lugar de obligar a cada contribuyente a completar una lista de verificación masiva, el manifiesto usa una jerarquía de preguntas centrales y otras opcionales y más detalladas. Puede resaltar los campos más relevantes para cada persona —por ejemplo, mostrando la procedencia de los datos y los detalles de actualización para analistas, mientras enfatiza el contexto clínico y las restricciones para investigadores y clínicos de primera línea. El equipo proporciona un formulario listo para usar (por ejemplo, en Microsoft Forms), una plantilla de visualización en HTML y un paquete R de código abierto llamado BioDataManifest. Este software puede convertir automáticamente las respuestas de la encuesta en páginas de manifiesto claras e incluso extraer información de repositorios públicos importantes como el Genomic Data Commons y dbGaP para crear manifiestos parciales de conjuntos de datos existentes.
Lo que esto significa para la IA médica futura
En última instancia, el Manifiesto de Datos Biomédicos es una herramienta práctica para facilitar la creación, el intercambio y la comprensión de la “letra pequeña” de los conjuntos de datos biomédicos. Al separar la documentación sobre los datos de la documentación sobre modelos de IA específicos, y al adaptar lo que se muestra a distintos roles de usuario, el marco reduce la carga sobre los investigadores a la vez que ofrece a los usuarios posteriores el contexto que necesitan para juzgar si un conjunto de datos es adecuado para un propósito determinado. En términos cotidianos, convierte conjuntos de datos médicos opacos en paquetes claramente etiquetados, ayudando a los desarrolladores de IA a detectar limitaciones y sesgos potenciales antes de que afecten a los pacientes. Si se adopta ampliamente, este tipo de documentación reutilizable y consciente del rol podría hacer que la IA biomédica sea más transparente, reproducible y equitativa.
Cita: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Palabras clave: documentación de datos biomédicos, IA responsable en medicina, transparencia de conjuntos de datos, sesgo en aprendizaje automático, gestión de datos