Clear Sky Science · es
Evitar que los datos de proteómica se conviertan en tumbas digitales mediante responsabilidad colectiva y compromiso comunitario
Por qué tus datos médicos no deberían acabar en un cementerio digital
La medicina moderna depende cada vez más de enormes conjuntos de datos que describen los miles de proteínas que actúan en nuestras células. Estos archivos a menudo se comparten públicamente en línea, con la promesa de que otros científicos puedan verificar resultados o plantear nuevas preguntas sin realizar experimentos adicionales. Pero si los datos se publican en formatos confusos, faltan detalles clave o están ligados a software propietario, se convierten en “tumbas de datos”: visibles para todos, pero prácticamente inutilizables. Este artículo muestra cómo un curso universitario convirtió a estudiantes en detectives de datos para exponer este problema oculto, y sugiere correcciones sencillas que podrían hacer que los datos compartidos sean realmente reutilizables.
Aprender ciencia rehaciendo estudios reales
En la Universidad de Helsinki, a estudiantes de posgrado de un curso de proteómica por espectrometría de masas se les pidió algo ambicioso: elegir conjuntos de datos proteicos reales y públicos de un repositorio importante e intentar reproducir los resultados publicados. Trabajando en pequeños equipos, descargaron seis proyectos de la red ProteomeXchange, que aloja resultados de espectrometría de masas de muchos laboratorios de todo el mundo. Usando una canalización de análisis compartida en el lenguaje R, los estudiantes siguieron los mismos pasos generales que los investigadores originales: identificar proteínas, medir su abundancia, limpiar los datos y probar qué proteínas cambian entre condiciones, como tejido enfermo frente a sano.
Grandes promesas, instrucciones que faltan
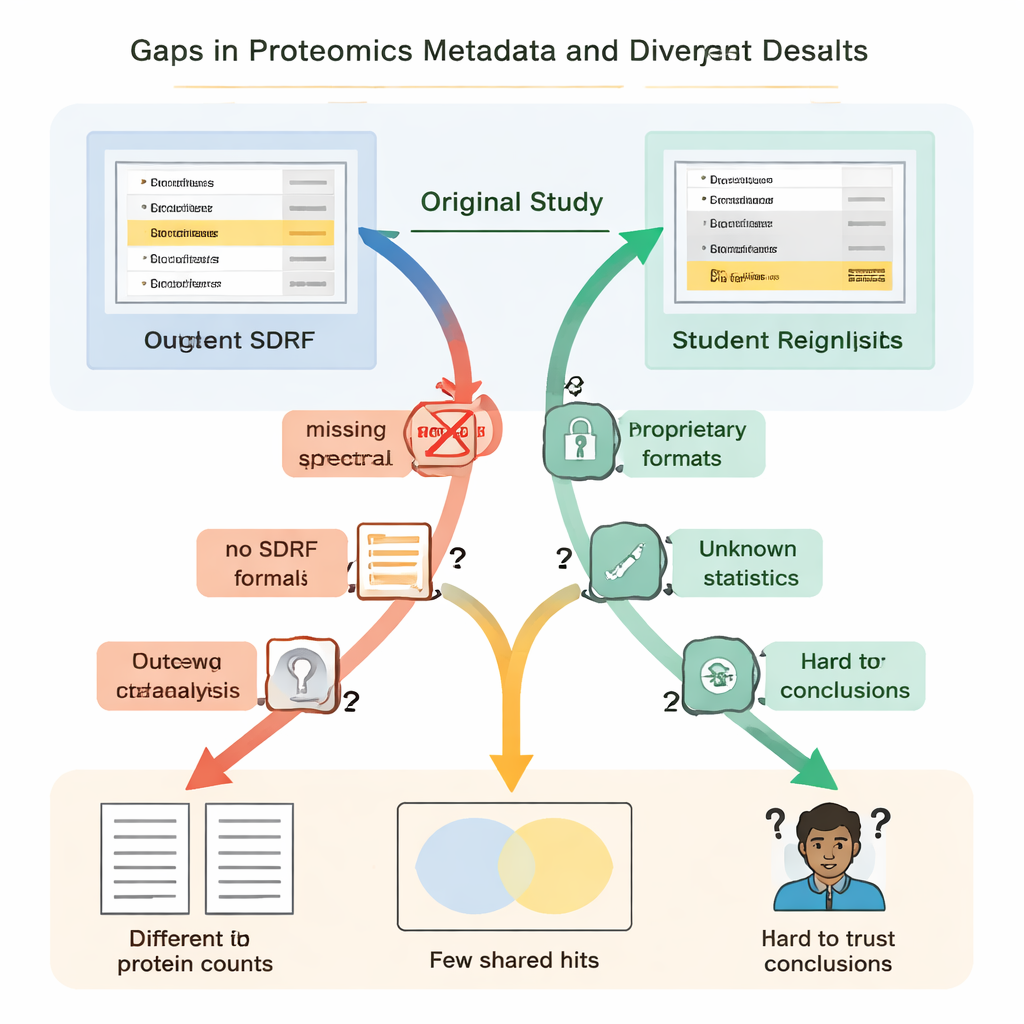
Los estudiantes descubrieron rápidamente que “abierto” no siempre significaba “reutilizable”. En todos los casos faltaban instrucciones esenciales o eran difíciles de encontrar. Los enlaces clave entre muestras y archivos de datos no se describían en un formato simple y legible por máquina, por lo que los equipos tuvieron que adivinar qué archivos crudos correspondían a qué grupos biológicos leyendo los artículos y descifrando los nombres de archivo. Faltaban detalles sobre cómo se controlaron los falsos positivos —como el uso de secuencias proteicas “cebo”—, lo que hacía imposible juzgar con rigor cuán fiables eran realmente las listas de proteínas reportadas. En varios proyectos, los resultados principales estaban bloqueados dentro de formatos de archivo propietarios o dependían de software comercial al que los estudiantes no podían acceder, obligándoles a rehacer grandes partes del análisis desde cero.
Cuando pequeñas lagunas generan grandes diferencias
Estas piezas ausentes no eran solo molestias; condujeron a resultados científicos radicalmente distintos. En un estudio sobre enfermedad renal, los autores originales reportaron algo menos de cinco mil proteínas, mientras que el reanálisis de los estudiantes —usando una herramienta abierta y una librería espectral casera— encontró más de trece mil. Una proteína destacada en el artículo original como especialmente importante no aparecía de forma convincente en el archivo de identificación subyacente y ni siquiera se detectó en el flujo de trabajo de los estudiantes. En otro caso, el estudio original listó 108 proteínas como cambiantes entre condiciones, pero los estudiantes, partiendo de los mismos datos crudos pero con información incompleta sobre cómo se realizaron las estadísticas originales, solo pudieron señalar con confianza 11. En otros proyectos, la falta de réplicas biológicas en los archivos subidos impidió que se realizaran pruebas estadísticas adecuadas.
Qué debería contener realmente un conjunto de datos “reutilizable”
De estos seis estudios de caso emergió un patrón claro: las principales barreras para la reproducibilidad no eran las máquinas de espectrometría de masas en sí, sino la forma en que se empaquetaban y compartían los resultados. Los autores sostienen que cada conjunto de datos de proteómica debería acompañarse de un paquete mínimo de reanálisis. Esto incluye los datos crudos más formatos de resultados abiertos y estandarizados por la comunidad; una tabla estandarizada que vincule cada muestra con sus condiciones experimentales; resúmenes básicos de control de calidad; cualquier biblioteca espectral o archivo de secuencias proteicas necesarios para repetir la búsqueda; y parámetros y código de análisis completos, idealmente almacenados con contenedores de software versionados. Los repositorios, revistas y revisores podrían ayudar incentivando o requiriendo que los remitentes proporcionen este paquete desde el principio, de modo que otros no tengan que reconstruir el flujo de trabajo a partir de pistas dispersas.
Formar científicos mientras se arregla el sistema
El curso en sí tuvo un doble propósito. Para los estudiantes, ofreció una forma práctica de dominar métodos complejos de proteómica, estadística y programación, a la vez que reveló cuán frágiles pueden ser las conclusiones publicadas cuando la documentación es incompleta. Para la comunidad en general, las dificultades de los estudiantes sirvieron como una prueba de esfuerzo de las prácticas actuales de intercambio de datos, destacando exactamente dónde fallan los metadatos y los registros de análisis. Los autores sugieren que se podrían impartir cursos similares en otros lugares, convirtiendo las aulas en motores de control de calidad que impulsen continuamente datos más claros y transparentes.
De tumbas de datos a recursos vivos
En términos sencillos, el artículo concluye que muchos conjuntos de datos proteómicos que ahora reposan en repositorios públicos corren el riesgo de convertirse en cementerios digitales: experimentos costosos cuyos resultados no pueden comprobarse ni ampliarse de forma fiable. Sin embargo, la solución es relativamente sencilla: tratar los metadatos, los formatos abiertos y el código compartible como partes integrales del experimento, no como añadidos. Si investigadores, revisores y repositorios insisten colectivamente en un paquete simple y bien documentado cada vez que se comparten datos de proteómica, esos conjuntos de datos podrán seguir “vivos”: listos para ser reanalizados, combinados con nuevos estudios y utilizados para reforzar la evidencia tras los descubrimientos biomédicos.
Cita: Vadadokhau, U., Soliman, M., Castillon, L. et al. Preventing Proteomics Data Tombs Through Collective Responsibility and Community Engagement. Sci Data 13, 287 (2026). https://doi.org/10.1038/s41597-026-06614-8
Palabras clave: proteómica, reproducibilidad de datos, ciencia abierta, espectrometría de masas, compartir datos de investigación