Clear Sky Science · es
Extracción de relaciones basada en transformadores y normalización de conceptos usando un corpus anotado de ensayos clínicos
Ayudando a los médicos a encontrar a los pacientes adecuados más rápido
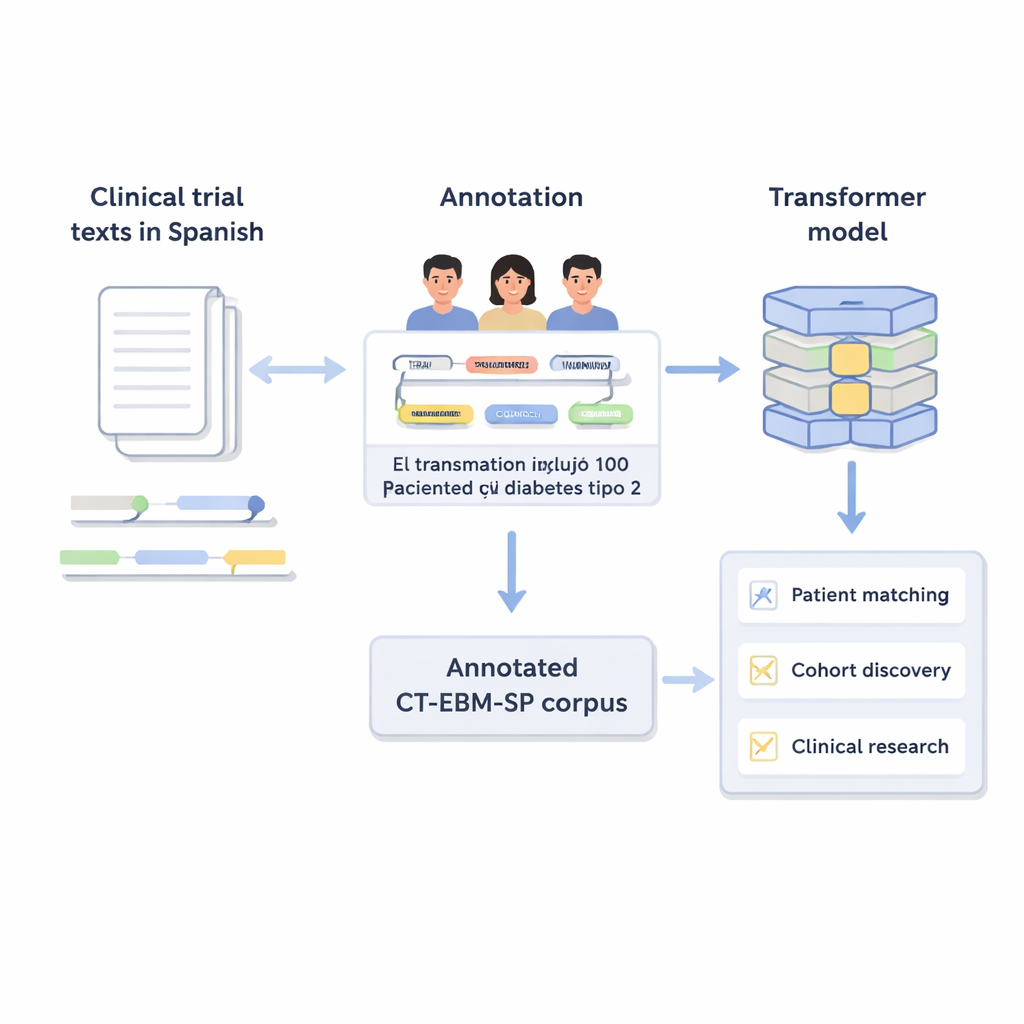
Cada ensayo clínico depende de encontrar pacientes que cumplan una larga lista de condiciones médicas, tratamientos y marcos temporales. Hoy en día, los médicos a menudo tienen que leer manualmente las historias clínicas electrónicas y las descripciones de los ensayos, lo que es lento y propenso a errores. Este artículo presenta una colección amplia y cuidadosamente revisada de textos de ensayos clínicos en español y muestra cómo la inteligencia artificial moderna puede convertir ese lenguaje no estructurado en datos organizados, allanando el camino para una investigación médica más rápida, equitativa y precisa.
Convertir texto libre en información organizada
Los ensayos clínicos describen quién puede y quién no puede participar usando un lenguaje médico cotidiano: límites de edad, enfermedades pasadas, resultados de pruebas y tratamientos probados. A los ordenadores les cuesta manejar ese tipo de texto libre. Los autores crearon la versión 3 del corpus CT-EBM-SP, un conjunto de datos de 1.200 textos de ensayos clínicos en español que contiene casi 300.000 palabras. Expertos humanos revisaron estos textos y marcaron 23 tipos de entidades médicas, como enfermedades, fármacos, resultados de pruebas y expresiones temporales, así como indicadores de negación (por ejemplo, «sin antecedentes de») e incertidumbre. También etiquetaron 11 atributos que capturan detalles como si un evento está en el pasado o en el futuro y si le ocurrió al paciente o a un familiar.
Hacer que los términos médicos hablen el mismo idioma
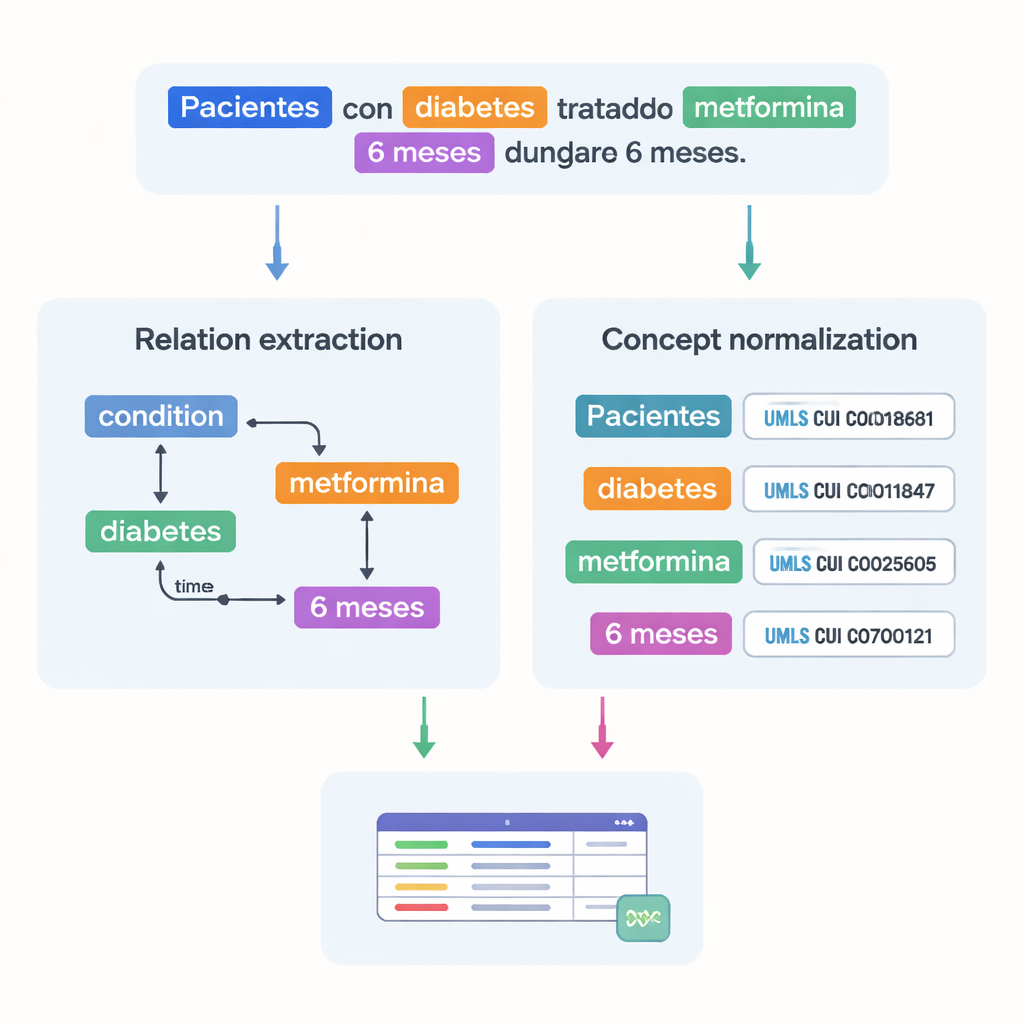
Un desafío importante en medicina es que el mismo concepto puede escribirse de muchas maneras. Para resolver esto, el equipo vinculó la mayoría de las entidades marcadas a códigos estandarizados del Unified Medical Language System (UMLS), un gran diccionario médico multilingüe. Este paso, llamado normalización de conceptos, significa que diferentes ortografías o frases apuntan al mismo identificador único. Por ejemplo, varias variantes de «25-hidroxivitamina D» se asignan a un único concepto UMLS. En total, el corpus incluye más de 87.000 entidades y más de 68.000 relaciones, y aproximadamente el 82 % de las entidades se normalizaron con éxito. Dos expertos verificaron de forma independiente estos enlaces, logrando un acuerdo muy alto, lo que indica que las anotaciones son fiables.
Capturar cómo se relacionan los hechos médicos
Más allá de listar términos médicos, el conjunto de datos registra cómo se conectan entre sí. Los autores diseñaron 18 tipos de relaciones para capturar patrones relevantes en los ensayos, como qué dosis pertenece a qué fármaco, cuánto dura un tratamiento o qué condición padece un paciente. Las relaciones temporales muestran si un evento ocurre antes o después de otro, y otros vínculos indican dónde se localiza una enfermedad en el cuerpo o si una frase expresa negación o especulación. En conjunto, estas relaciones permiten a los ordenadores construir grafos de la situación de un paciente—quién es el paciente, qué condición tiene, qué tratamiento recibe y en qué momento—en lugar de limitarse a reconocer palabras aisladas.
Entrenar y evaluar modelos de IA modernos
Para demostrar que el corpus es útil en la práctica, los autores afinaron varios modelos de IA basados en transformadores, incluidas versiones multilingües de BERT y RoBERTa. Entrenaron estos modelos en dos tareas: extracción de relaciones, que aprende a recuperar los vínculos entre entidades, y normalización de conceptos médicos, que asigna texto a códigos UMLS. En extracción de relaciones, el mejor modelo alcanzó una puntuación F1 cercana a 0,88, lo que significa que identificó correctamente la mayoría de las relaciones con relativamente pocos errores. Para la normalización de conceptos, un modelo multilingüe llamado SapBERT, utilizado sin entrenamiento adicional, acertó el concepto correcto en su primera propuesta casi el 90 % de las veces. Estos resultados muestran que conjuntos de datos bien anotados y de tamaño medio pueden impulsar modelos precisos y eficientes incluso sin sistemas de lenguaje general masivos.
Por qué este recurso importa para la atención futura
El corpus CT-EBM-SP y los modelos asociados proporcionan una base para herramientas que puedan analizar automáticamente textos de ensayos clínicos en español, compararlos con registros de pacientes y apoyar el descubrimiento de cohortes en los hospitales. Dado que los datos están alineados con estándares médicos internacionales y han sido revisados cuidadosamente por expertos, también pueden ayudar a desarrollar recursos similares para otros idiomas con menos herramientas digitales. En términos cotidianos, este trabajo pretende facilitar y hacer más seguro que a los pacientes adecuados se les ofrezcan los ensayos adecuados, acelerando los descubrimientos médicos y reduciendo la carga sobre los profesionales sanitarios.
Cita: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Palabras clave: ensayos clínicos, minería de texto médico, sanidad en España, modelos transformer, medicina basada en la evidencia