Clear Sky Science · es
Conjunto de datos Kymata Soto sobre el lenguaje: un conjunto electro‑magnetoencefalográfico para el procesamiento del habla natural
Escuchar cómo el cerebro oye conversaciones reales
La mayor parte de lo que decimos y oímos a diario son conversaciones informales, no palabras sueltas ni frases leídas con cuidado. Sin embargo, gran parte de la investigación cerebral sobre el lenguaje se ha basado en tareas artificiales. El conjunto de datos Kymata Soto cambia esto al ofrecer una colección abierta y rica de registros cerebrales de personas que simplemente escuchan animadas conversaciones radiofónicas en inglés y ruso, proporcionando a los científicos una ventana poderosa sobre cómo nuestros cerebros procesan el habla natural.
Una nueva biblioteca de respuestas cerebrales al habla real
Este proyecto reúne dos métodos avanzados de registro cerebral—electroencefalografía (EEG) y magnetoencefalografía (MEG)—de 35 adultos: 20 hablantes nativos de inglés y 15 hablantes nativos de ruso. Mientras permanecían sentados y escuchaban en silencio unos seis minutos y medio de conversación estilo radiofónico en su propio idioma, se registró su actividad cerebral a mil veces por segundo. Cada persona escuchó el mismo audio varias veces, lo que permitió a los investigadores promediar las repeticiones y separar las respuestas cerebrales fiables del ruido de fondo. El resultado es un registro detallado, sincronizado en el tiempo, de cómo reacciona el cerebro, momento a momento, mientras las personas siguen una discusión en desarrollo.

Conversaciones sobre helados y café
En lugar de usar historias clásicas o frases artificiales, el equipo eligió temas atractivos pero cotidianos: la historia del helado para los oyentes de inglés y la historia del café colombiano para los oyentes de ruso. Ambas grabaciones proceden de discusiones en estudio de la BBC con tres hablantes (dos hombres y una mujer). Las conversaciones fueron editadas a unos 400 segundos y se presentaron a niveles cómodos de audición mediante auriculares. Tras cada repetición, los participantes respondieron una o dos preguntas sencillas de opción múltiple sobre el contenido—lo justo para asegurar que se mantenían atentos y seguían la historia, no para ponerlos a prueba a fondo.
Mantener los ojos ocupados pero la mente en el sonido
Mientras los participantes escuchaban, fijaban la vista en una cruz central en una pantalla. Alrededor de ella, nubes de puntos de colores flotaban y cambiaban de forma aparentemente aleatoria. Estos puntos móviles tenían dos propósitos: ayudaban a mantener la mirada estable, lo que mejora la calidad de los datos, y creaban patrones controlados de movimiento visual y color que otros investigadores pueden analizar después. Es importante destacar que los puntos no se sincronizaban con el contenido del habla, por lo que no “ilustraban” la historia ni añadían significado, pero sí proporcionaban un fondo visual consistente que puede estudiarse junto con los sonidos.
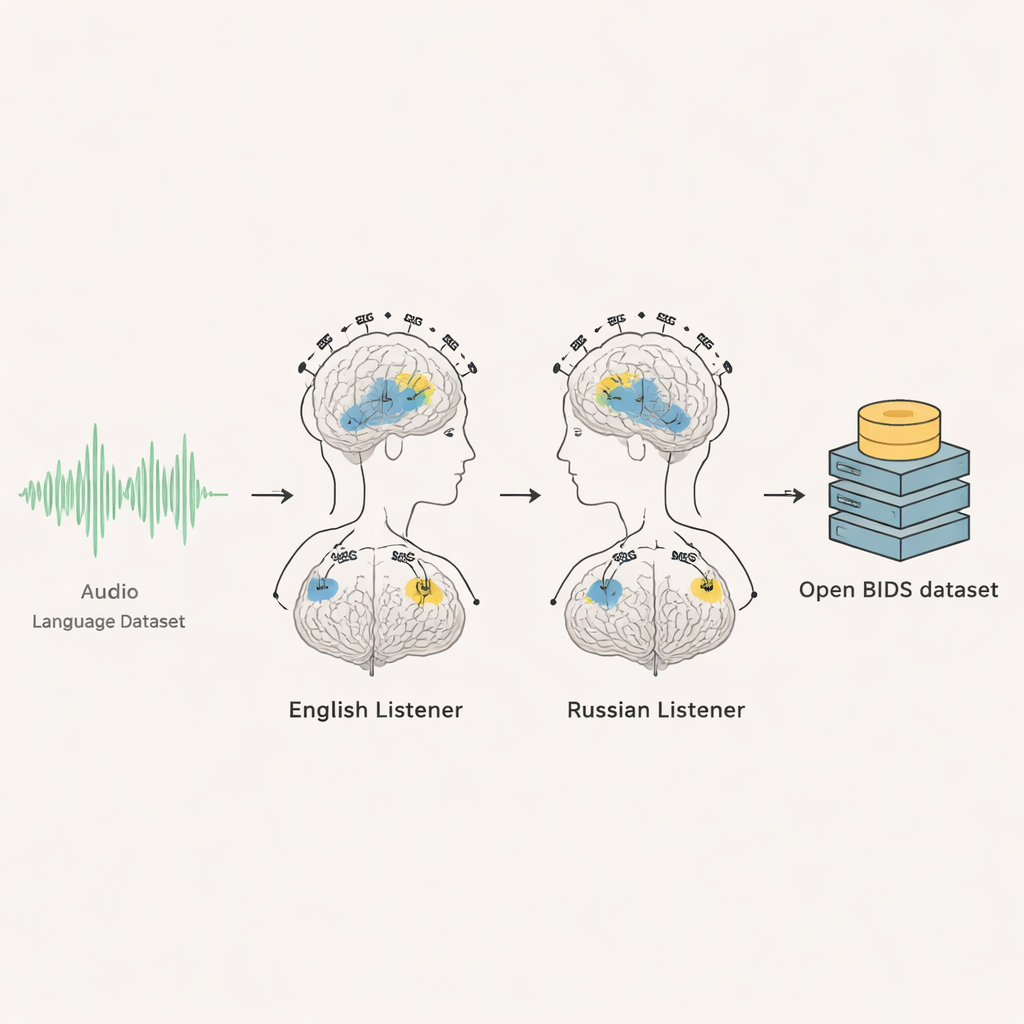
De las señales cerebrales crudas a datos listos para usar
Los investigadores documentaron cuidadosamente cada parte del experimento y organizaron el conjunto de datos siguiendo un estándar internacional para datos cerebrales llamado BIDS. Para cada voluntario hay registros crudos de EEG y MEG, marcadores temporales de cuándo empezó el audio, eventos visuales por segundo y segmentos de práctica. El equipo también facilita los archivos de audio originales, transcripciones completas y tiempos precisos de cuándo empezó cada palabra e incluso cada sonido individual del habla. Incluyen guiones para que otros puedan reproducir automáticamente los extractos exactos de audio utilizados. Para el grupo de inglés se comparten escáneres MRI anonimizados para que las respuestas cerebrales puedan mapearse en la anatomía individual del cerebro; para el grupo ruso, el consentimiento no permitió compartir imágenes MRI, por lo que se recomienda a los usuarios basarse en plantillas cerebrales promedio estándar.
Comprobar que las señales tienen sentido
Para garantizar que los datos son científicamente fiables, los autores realizaron análisis de validación centrados en cómo el cerebro sigue los cambios en la sonoridad del sonido a lo largo del tiempo. Transformaron el audio en varias descripciones matemáticas de la “sonoridad que varía en el tiempo” y luego examinaron dónde y cuándo las respuestas cerebrales se alineaban con esos patrones de sonoridad. Tanto en oyentes de inglés como de ruso, el cerebro mostró patrones temporales similares, coherentes con lo informado en trabajos anteriores. Esta concordancia entre idiomas y con estudios previos es un indicio sólido de que los registros son limpios, fiables y están listos para que otros los utilicen.
Por qué esto importa para la investigación futura sobre cerebro y lenguaje
Para los no especialistas, la conclusión principal es que este conjunto de datos es un nuevo recurso común que permite a muchos equipos de investigación estudiar cómo se procesa en el cerebro el habla real y espontánea. Al ser abierto, bien anotado y grabado en dos idiomas distintos, puede apoyar proyectos que vayan desde preguntas básicas sobre cómo entendemos una conversación, hasta comparaciones entre idiomas y esfuerzos ambiciosos para decodificar el habla directamente desde la actividad cerebral. En resumen, el conjunto de datos Kymata Soto sobre el lenguaje no se centra en responder una única pregunta, sino en ofrecer a la comunidad científica una base compartida y de alta calidad para explorar cómo nuestros cerebros dan sentido a las conversaciones que llenan nuestra vida cotidiana.
Cita: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Palabras clave: cerebro y lenguaje, percepción del habla, EEG MEG, conversación naturalista, datos abiertos de neuroimagen