Clear Sky Science · es
Alineación semántica del modelo de metadatos del Archivo Alemán de Genoma-Fenoma Humano en el campo de la genómica de Europa
Por qué compartir datos genómicos requiere más que simples archivos
La medicina moderna depende cada vez más de leer nuestro ADN para diagnosticar enfermedades y personalizar tratamientos. Pero el verdadero potencial de la genómica aparece cuando los datos de muchos hospitales y países pueden combinarse. Eso solo funciona si cada conjunto de datos se describe de forma clara y compatible y si se respetan estrictamente las leyes de privacidad, como el RGPD europeo. Este artículo explica cómo el Archivo Alemán de Genoma-Fenoma Humano (GHGA) está construyendo un «sistema de descripción» detallado para estudios genómicos de modo que los datos valiosos puedan ser encontrados, comprendidos y compartidos de forma segura en toda Europa.
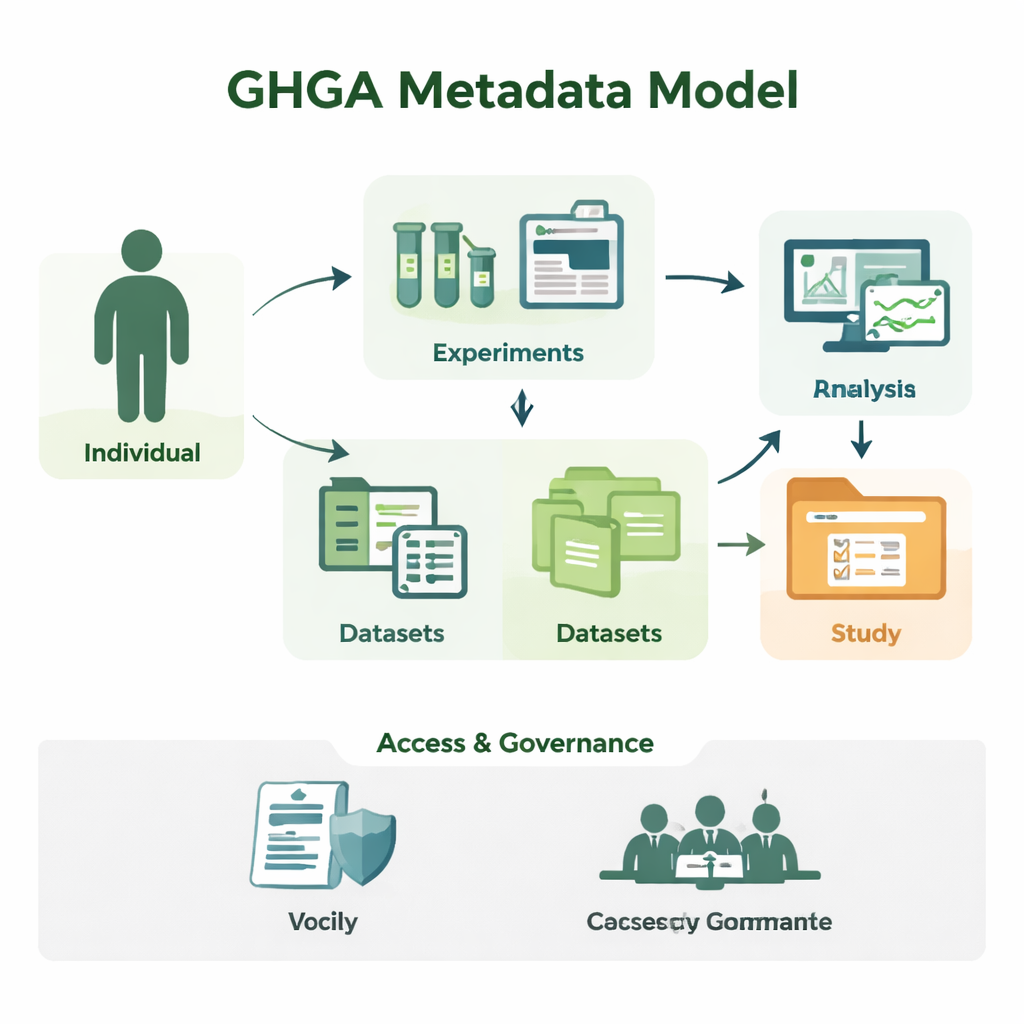
De las secuencias crudas a estudios comprensibles
La investigación genómica produce enormes cantidades de datos de secuencia, pero por sí solo un archivo de letras de ADN no tiene sentido. Los investigadores necesitan saber de quién procedía la muestra, qué tejido se utilizó, cómo se realizó el experimento y bajo qué condiciones puede reutilizarse la información. GHGA captura esta información contextual como metadatos. Su modelo organiza los metadatos en 16 bloques constructivos, como la persona que participa en el estudio (el «Individuo»), la muestra tomada, el experimento y el análisis realizados, los archivos de datos creados y los conjuntos de datos y estudios que los agrupan. Al separar los detalles científicos de los administrativos, como las condiciones de acceso, el modelo refleja cómo funciona realmente un laboratorio y un portal de datos, pero de una forma que los ordenadores pueden procesar de manera fiable.
Mantener los datos útiles sin identificar a las personas
Porque GHGA maneja datos sensibles sobre la salud humana, el equipo tuvo que diseñar el modelo para que fuera científicamente rico sin facilitar la identificación de las personas detrás de los datos. Las normas europeas del RGPD establecen que la información que pueda vincularse razonablemente a un individuo se considera datos personales, incluso si se eliminan los nombres. El artículo describe un análisis de privacidad cuidadoso que mostró cómo la combinación de detalles como la edad, el código postal y diagnósticos raros puede revelar identidades. En respuesta, el portal público de GHGA evita datos de localización de alta resolución, agrupa las edades en rangos amplios en lugar de años exactos y fusiona códigos de diagnóstico detallados en categorías más generales. De este modo, los investigadores siguen pudiendo valorar si un conjunto de datos es relevante para su trabajo, mientras que el esfuerzo necesario para identificar a una persona se vuelve poco realista.
Comprobar la compatibilidad con el ecosistema genómico europeo
Para ser realmente útiles, los metadatos de GHGA deben encajar en una red europea más amplia de archivos y herramientas genómicas. Por ello, los autores compararon su modelo, elemento por elemento, con otros cuatro marcos de uso extendido: dos versiones del European Genome-phenome Archive (EGA), el estándar ISA-tab y el modelo FAIR Genomes del sistema sanitario neerlandés. Realizaron un «mapeo» detallado que preguntó, para cada campo de GHGA, si existía un equivalente en los otros modelos y viceversa. Encontraron que la mayoría de las propiedades clave de GHGA tienen contrapartes claras en otros lugares, especialmente para describir estudios, muestras, experimentos, análisis y formatos de archivo. Esto significa que los conjuntos de datos de GHGA pueden entenderse e integrarse junto con datos almacenados en otros sistemas europeos.
Encontrar puntos en común — y lo que aún falta
A partir de esta comparación, el equipo extrajo 25 campos de metadatos «consensuados» que aparecen en al menos tres de los cinco modelos. Estos cubren aspectos esenciales como el sexo y el estado de salud de los participantes, el tejido utilizado, el tipo de secuenciación y aparato, el método de análisis, los formatos de archivo y descripciones básicas del estudio y los datos de contacto. Estos campos compartidos coinciden con las guías mínimas de reporte existentes y pueden servir como lista de verificación básica para quien diseñe nuevos portales de datos genómicos. Al mismo tiempo, el análisis reveló información que algunos modelos recogen pero que GHGA omite actualmente o solo acepta en forma libre de texto, como las fechas exactas de muestreo y secuenciación, diagnósticos excluidos y nombres de contacto detallados. Muchas de estas omisiones son compensaciones deliberadas en favor de la privacidad y el anonimato.
Qué significa esto para la investigación sanitaria futura
En conjunto, el estudio muestra que el modelo de metadatos de GHGA es detallado, flexible y está estrechamente alineado con las prácticas internacionales, al tiempo que se mantiene dentro de las estrictas normas de privacidad europeas. Ya cubre todos los campos que otros archivos consideran obligatorios, y puede ampliarse a nuevas tecnologías como la ómica de una sola célula y la ómica espacial. Al ofrecer una forma clara de describir quién y qué implica un estudio genómico, cómo se produjeron los datos y en qué condiciones pueden volver a utilizarse, GHGA ayuda a convertir silos de datos aislados en un recurso de investigación conectado. Para los pacientes, esto mejora las posibilidades de que sus datos, una vez donados, puedan contribuir de forma segura a descubrimientos y mejores tratamientos más allá de las fronteras durante años.
Cita: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Palabras clave: compartición de datos genómicos, estándares de metadatos, privacidad y GDPR, GHGA, medicina personalizada