Clear Sky Science · es
SEA CDM: Modelo de Datos Común Study-Experiment-Assay y Bases de Datos para la Integración y el Análisis de Datos entre Dominios
Por qué nos importa a todos organizar los datos de laboratorio
La medicina moderna se basa en montañas de datos experimentales —desde ensayos de vacunas y estudios de infección hasta genómica del cáncer—. Sin embargo, a menudo estos datos quedan atrapados en formatos incompatibles, lo que dificulta que los científicos combinen resultados y detecten patrones importantes, como quién responde mejor a una vacuna o por qué algunas personas tienen más efectos secundarios. Este artículo describe una nueva forma de organizar y conectar experimentos biomédicos diversos para que los investigadores puedan plantear preguntas más ricas y obtener respuestas más rápidas y fiables que, en última instancia, influyan en cómo prevenimos y tratamos las enfermedades.
Un lenguaje común para los experimentos
Diferentes grupos de investigación y bases de datos tienden a describir sus estudios a su manera, incluso cuando realizan trabajos muy similares. Una base de datos puede centrarse en ensayos de vacunas, otra en la actividad génica en células individuales y una tercera en resultados clínicos, cada una usando etiquetas y estructuras distintas. El Modelo de Datos Común Study–Experiment–Assay, o SEA CDM, ofrece una “gramática” compartida simple para todos estos esfuerzos. Divide cualquier proyecto biomédico en tres pasos vinculados: el estudio general que plantea una pregunta, los experimentos realizados en personas o animales y los ensayos —como análisis de sangre o mediciones de expresión génica— que generan resultados. Alrededor de estos pasos, el modelo también estandariza elementos clave como quién o qué se estudió, qué muestras se tomaron, qué tratamientos se aplicaron y qué análisis se realizaron. 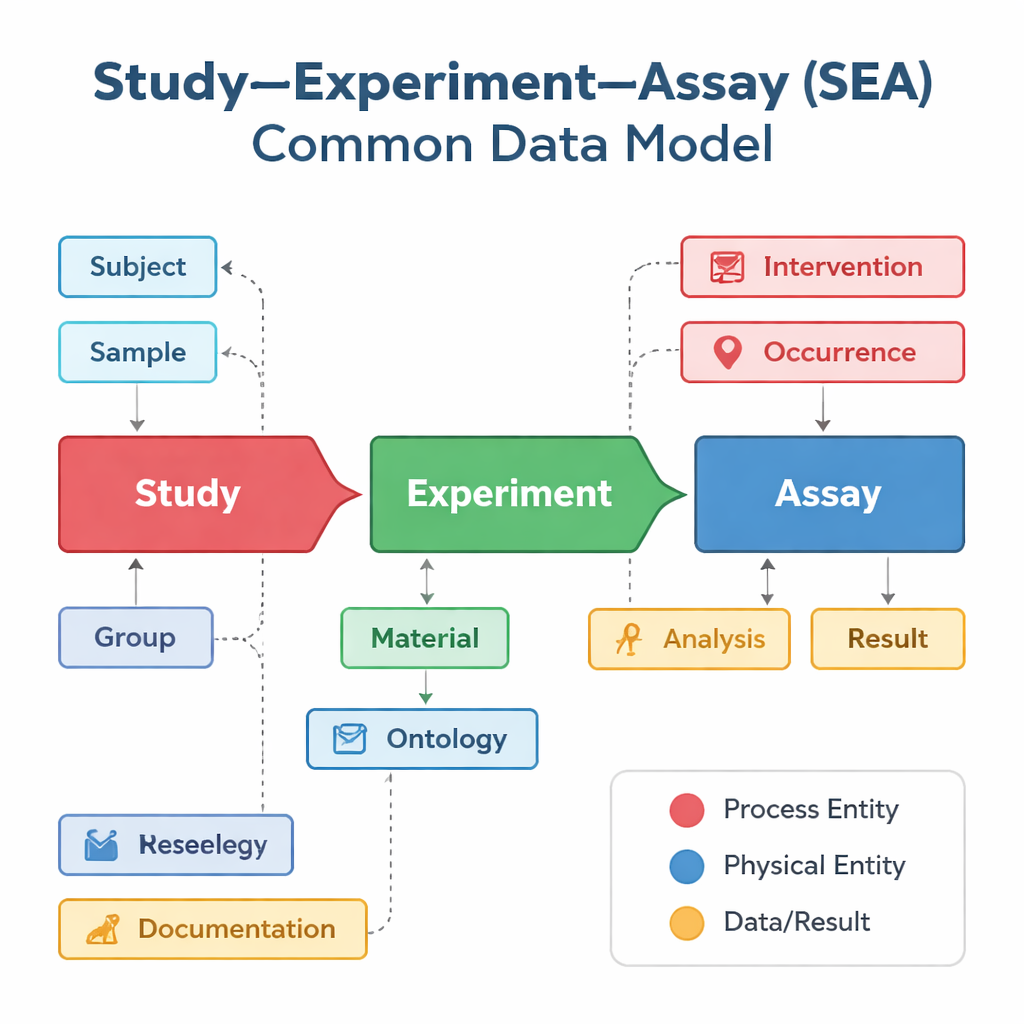
Ontologías: convertir etiquetas en conocimiento
Alinear encabezados de columna no basta; un mismo concepto puede denominarse de formas diferentes en distintos sitios. SEA CDM se apoya en vocabularios curados conocidos como ontologías para asegurarse de que “vacuna contra la gripe”, “vacuna inactivada trivalente contra la influenza” y una marca comercial como “Fluzone” se reconozcan como ideas relacionadas. Estas ontologías están estructuradas como árboles genealógicos de términos médicos y biológicos. Porque SEA CDM asigna un identificador oficial de una ontología a cada variable —como una enfermedad, un tipo celular o una vacuna—, los ordenadores pueden recorrer automáticamente esos árboles, encontrar todos los registros relevantes e incluso inferir relaciones. Por ejemplo, una consulta breve puede extraer todos los estudios que usaron cualquier vacuna trivalente contra la influenza entre cientos de productos nombrados, lo que permite búsquedas semánticas potentes que van mucho más allá de la coincidencia simple de palabras clave. 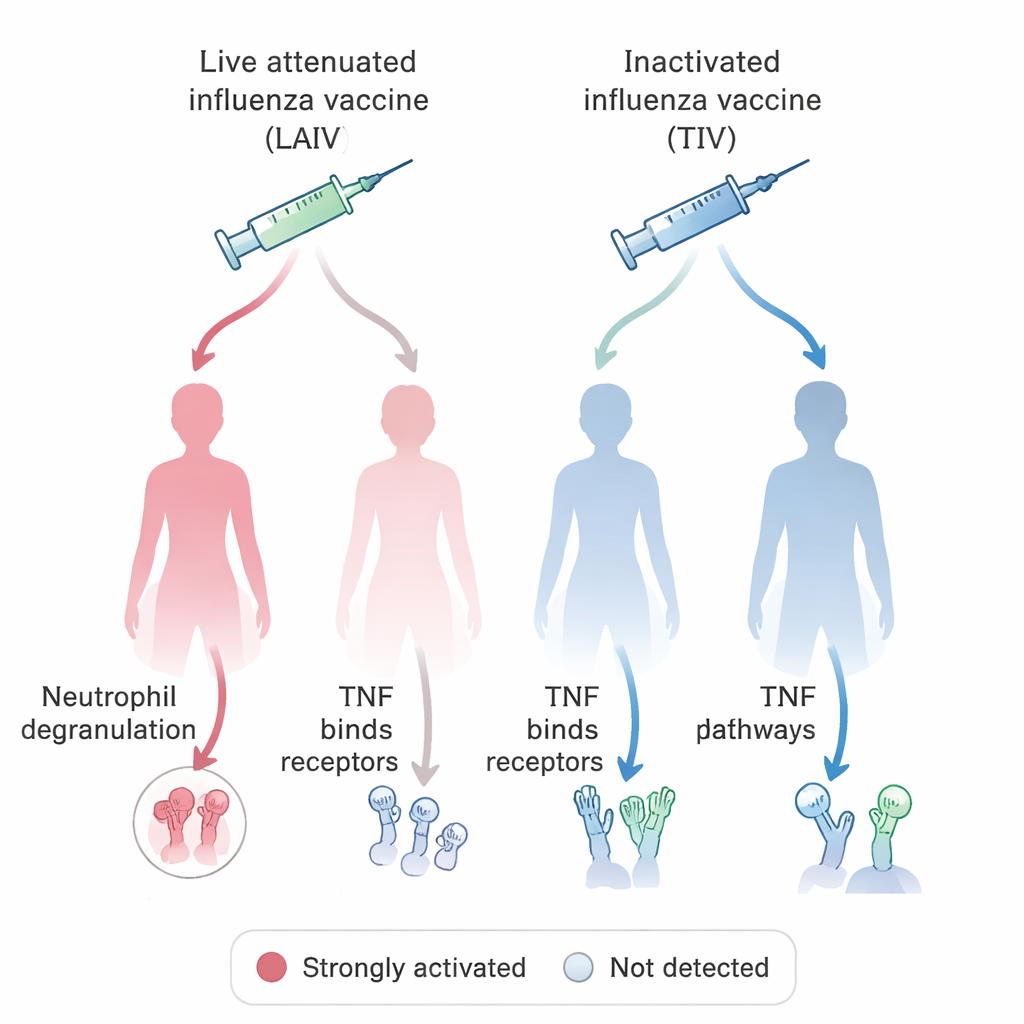
De archivos dispersos a bases de datos conectadas
Para probar su modelo en el mundo real, los autores construyeron una familia de bases de datos y herramientas bajo el nombre paraguas OSEAN. Convirtieron tres grandes recursos públicos al formato SEA CDM: ImmPort, que aloja metadatos de estudios sobre la respuesta inmune; VIGET, que vincula estudios de vacunas con datos de actividad génica; y CELLxGENE, que se centra en mediciones a nivel de célula única. Usando canalizaciones personalizadas, tradujeron decenas de tablas y formatos de archivo originales a un conjunto coherente de tablas SEA CDM o nodos de grafo. Esto les permitió almacenar más de mil estudios relacionados con la inmunidad, más de dos millones de muestras y numerosas descripciones de vacunas, enfermedades y métodos de laboratorio en un marco coherente que puede buscarse con el mismo software.
Lo que los datos unificados pueden revelar sobre las vacunas y las diferencias por sexo
Con este sistema unificado en funcionamiento, el equipo planteó una pregunta biológica de relevancia médica directa: ¿cómo estimulan las distintas vacunas contra la influenza el sistema inmunitario en mujeres y hombres? Consultando la base de datos OSEAN basada en VIGET y aplicando reglas sencillas para definir qué se considera un gen “estimulado”, identificaron cientos de genes cuya actividad aumentó tras la vacunación con vacunas atenuadas vivas (que contienen virus debilitados) o con vacunas inactivadas «muertas». Luego compararon las vías en las que participan esos genes, separando los datos por sexo. Un patrón llamativo implicó a los neutrófilos, un tipo de glóbulo blanco que ataca microbios liberando gránulos tóxicos, y la señalización a través del TNF, una molécula inflamatoria clave. En la mayoría de los grupos, la vacunación contra la influenza se asoció con señales de degranulación de neutrófilos, pero esta firma faltó en las mujeres que recibieron la vacuna atenuada viva. En contraste, la señalización relacionada con TNF fue especialmente prominente en estas mujeres, pero no en los grupos masculinos paralelos. Estos hallazgos hacen eco de estudios en animales que sugieren que el comportamiento de los neutrófilos y las respuestas a vacunas pueden diferir de forma sistemática entre machos y hembras.
Construir un ecosistema para descubrimientos futuros
Los autores sostienen que el verdadero poder del SEA CDM reside en hacer que los datos biomédicos sean más FAIR —localizables, accesibles, interoperables y reutilizables. Al dar a los experimentos una estructura compartida y anclar cada etiqueta importante a un término ontológico bien definido, su sistema facilita combinar datos de diferentes fuentes, rastrear cómo se manipularon las muestras y reproducir análisis. El estudio de caso sobre influenza muestra que incluso consultas relativamente simples, ejecutadas sobre una base de datos armonizada, pueden descubrir patrones sutiles y específicos por sexo en la respuesta a vacunas que podrían influir en la dosificación o la elección de la vacuna. A medida que más recursos adopten este modelo común y las herramientas asociadas, los investigadores estarán mejor equipados para conectar pistas entre enfermedades, tecnologías y poblaciones, convirtiendo conjuntos de datos fragmentados en un verdadero ecosistema integrador de biodatos.
Cita: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Palabras clave: integración de datos, ontología biomédica, respuesta a vacunas, diferencias por sexo, grafo de conocimiento