Cómo el cerebro descubre reglas ocultas en un mundo ruidoso
Cada día identificamos patrones con facilidad: una luz roja significa detenerse, una calle llena de gente implica reducir la velocidad, cierta postura indica que una mascota está a punto de saltar. Detrás de estas habilidades está la capacidad del cerebro de desentrañar estructura oculta, o “latente”, en el mundo y reutilizarla en muchas tareas distintas. Este artículo plantea una pregunta aparentemente simple: ¿qué hace que un patrón de actividad poblacional neuronal sea mejor que otro para resolver con rapidez y precisión muchas tareas relacionadas?
Las perillas ocultas detrás de los códigos neuronales Figure 1.
Los autores estudian la actividad cerebral a nivel poblacional, tratando los disparos de muchas neuronas como puntos en un espacio de alta dimensión. Se centran en tareas que comparten un conjunto subyacente de variables latentes —por ejemplo, la forma, el tamaño y la posición de un objeto, o la ubicación y la velocidad de un animal. Una neurona o circuito aguas debajo lee estos patrones con una regla lineal simple, similar a trazar un plano a través de la nube de puntos para separar la “categoría A” de la “categoría B”. En lugar de simular cada neurona en detalle, los autores derivan una fórmula analítica que predice cuánto se generalizará dicha lectura a nuevos ejemplos, dado la geometría de la actividad neuronal. De forma notable, encuentran que el rendimiento está gobernado por solo cuatro estadísticas que capturan cuánto reflejan las neuronas las variables latentes, cuán claramente se separan diferentes variables, cómo se distribuye el ruido y cuántas dimensiones efectivas ocupa la actividad.
Cuatro ingredientes sencillos para una buena generalización
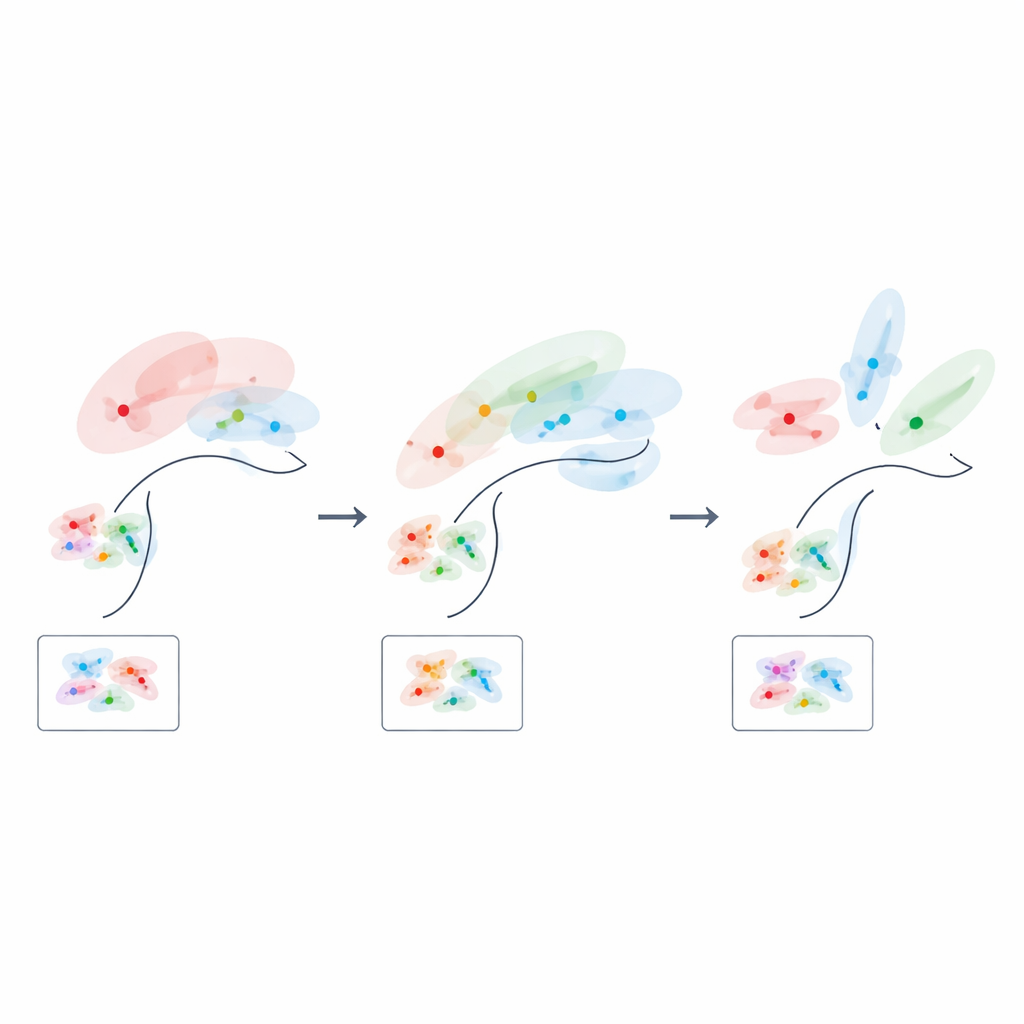
El primer ingrediente es la correlación global entre neuronas individuales y las variables latentes: cuando pequeños cambios en las variables ocultas provocan desplazamientos claros en las respuestas neuronales, las lecturas aguas abajo disponen de más señal para trabajar. El segundo y tercer ingredientes describen la “factorización”: idealmente, distintas variables latentes se codifican a lo largo de direcciones independientes, y el ruido aleatorio deriva en direcciones ortogonales a estos ejes de señal. Esto facilita que un único límite lineal se transfiera entre muchas tareas que dependen de la misma estructura oculta. El cuarto ingrediente es la dimensionalidad efectiva, que captura cuántas direcciones en el espacio de actividad usa realmente la población. Una mayor dimensionalidad tiende a diluir el ruido a lo largo de más direcciones, mejorando la fiabilidad, pero debe equilibrarse con la claridad con que la señal se alinea con las variables relevantes para el comportamiento.
Evaluando la teoría en cerebros artificiales y biológicos Figure 2.
Para comprobar su teoría, los autores la aplican primero a redes neuronales artificiales. En perceptrones multicapa entrenados en muchos problemas de clasificación relacionados, y en una red profunda entrenada para seguir partes del cuerpo de ratones en vídeo, miden las cuatro cantidades geométricas en cada capa. Los errores predichos coinciden estrechamente con el rendimiento real de lecturas simples entrenadas sobre esas representaciones internas. Luego investigan datos cerebrales reales. Registros de áreas visuales de macacos muestran que, a medida que las señales viajan desde los ojos hacia la corteza visual superior, la geometría evoluciona de forma que se reduce el error de generalización: aumentan las correlaciones con las variables latentes, la variabilidad no deseada se desplaza fuera de las direcciones de señal y ciertas formas de dimensionalidad se remodelan. En ratas que aprenden una tarea de alternancia espacial, tanto el comportamiento como el rendimiento de las lecturas mejoran con días de entrenamiento, mientras que la geometría de la actividad hipocampal y prefrontal cambia de maneras sistemáticas que reflejan las predicciones de la teoría.
Cómo el aprendizaje reescribe el espacio neuronal
Puesto que su fórmula enlaza la geometría directamente con el rendimiento, los autores pueden preguntar cómo debería ser un código neuronal “óptimo” en distintas fases del aprendizaje. Al principio, cuando solo hay pocos ejemplos de entrenamiento disponibles, los mejores códigos son de baja dimensión y están fuertemente alineados con las variables latentes más informativas, comprimiendo efectivamente las características menos útiles. A medida que se acumula la experiencia, la solución óptima cambia: la representación de la estructura relevante para la tarea se expande hacia más dimensiones, y la estrecha correlación entre neuronas individuales y variables concretas en realidad se relaja. En otras palabras, el cerebro parece empezar con un boceto centrado y de baja dimensión de la tarea y, conforme aprende, va completando un mapa más rico y distribuido.
Por qué esto importa para entender cerebros y máquinas
Para un lector no especializado, el mensaje clave es que la actividad poblacional cerebral no es solo un enredo de espigas; tiene una forma, y esa forma importa. Al identificar cuatro características geométricas medibles que controlan cuánto pueden generalizar lecturas simples entre tareas relacionadas, este trabajo ofrece un lenguaje común para comparar redes neuronales biológicas y artificiales. Sugiere que, a medida que animales y máquinas aprenden, reorganizan su actividad interna desde códigos compactos y muy alineados hacia otros de mayor dimensionalidad y mejor factorización que siguen protegiendo la información relevante para la tarea frente al ruido. Esta visión geométrica ayuda a explicar cómo los mismos circuitos cerebrales pueden reutilizar con flexibilidad la estructura oculta en muchas situaciones, sustentando la aparente generalización sin esfuerzo que subyace a la inteligencia cotidiana.
Cita: Wakhloo, A.J., Slatton, W. & Chung, S. Neural population geometry and optimal coding of tasks with shared latent structure.
Nat Neurosci29, 682–692 (2026). https://doi.org/10.1038/s41593-025-02183-y
Palabras clave: geometría de poblaciones neuronales, codificación de variables latentes, aprendizaje multitarea, representaciones desentrelazadas, generalización en redes neuronales