Clear Sky Science · es
Fiabilidad de los LLM como asistentes médicos para el público general: un estudio aleatorizado preregistrado
Por qué tu teléfono puede no ser el mejor primer médico
Cada vez más personas recurren a chatbots de IA cuando se sienten mal, buscando respuestas rápidas sobre si preocuparse, qué pueden significar sus síntomas y si deben ir al hospital. Este estudio plantea una pregunta sencilla pero urgente: si personas corrientes usan modelos de lenguaje potentes como ayudantes médicos en casa, ¿toman realmente mejores decisiones sobre su salud, o podría la tecnología dar una falsa sensación de seguridad?
Probar máquinas inteligentes con casos al estilo de la vida real
Para averiguarlo, investigadores del Reino Unido diseñaron diez historias médicas realistas, como un dolor de cabeza repentino y severo o dificultad para respirar, basadas en condiciones comunes que muchos podríamos enfrentar. Un equipo de médicos experimentados acordó cuál era el “siguiente paso” más adecuado para cada historia —que iba desde quedarse en casa y cuidarse hasta llamar a una ambulancia— y enumeró las condiciones clave que una persona cuidadosa debería considerar. Luego, 1.298 adultos de todo el Reino Unido fueron asignados al azar a una de cuatro opciones: usar uno de tres chatbots de IA líderes, o usar lo que normalmente emplearían en casa, como búsquedas en la web o la experiencia personal.
Cómo se desempeñaron personas y máquinas—por separado y juntos
Cuando se probaron los modelos de lenguaje por sí solos, alimentándolos con las descripciones completas de los casos y pidiéndoles directamente un diagnóstico y la acción recomendada, lo hicieron de forma notable. Entre los tres sistemas, sugirieron correctamente al menos una condición médica relevante en aproximadamente el 95% de los casos y eligieron el nivel correcto de urgencia en más de la mitad de las ocasiones —mucho mejor que al azar. Sobre el papel, estos sistemas parecían candidatos sólidos para orientar a pacientes preocupados.
Cuando el consejo de la IA se encuentra con personas reales
Pero una vez que entraron en escena los usuarios cotidianos, el panorama cambió. Los participantes que usaron IA no fueron más precisos que el grupo de control al elegir qué hacer a continuación, y en realidad lo hicieron peor al nombrar condiciones subyacentes relevantes. Las personas en el grupo no-IA tenían aproximadamente 1,8 veces más probabilidades de identificar una condición correcta que quienes usaban chatbots. La mayoría de los participantes en todos los grupos subestimaron la gravedad de la situación. En otras palabras, el acceso a un modelo de lenguaje avanzado no ayudó a la gente a entender mejor sus síntomas, ni les empujó claramente hacia decisiones más seguras.
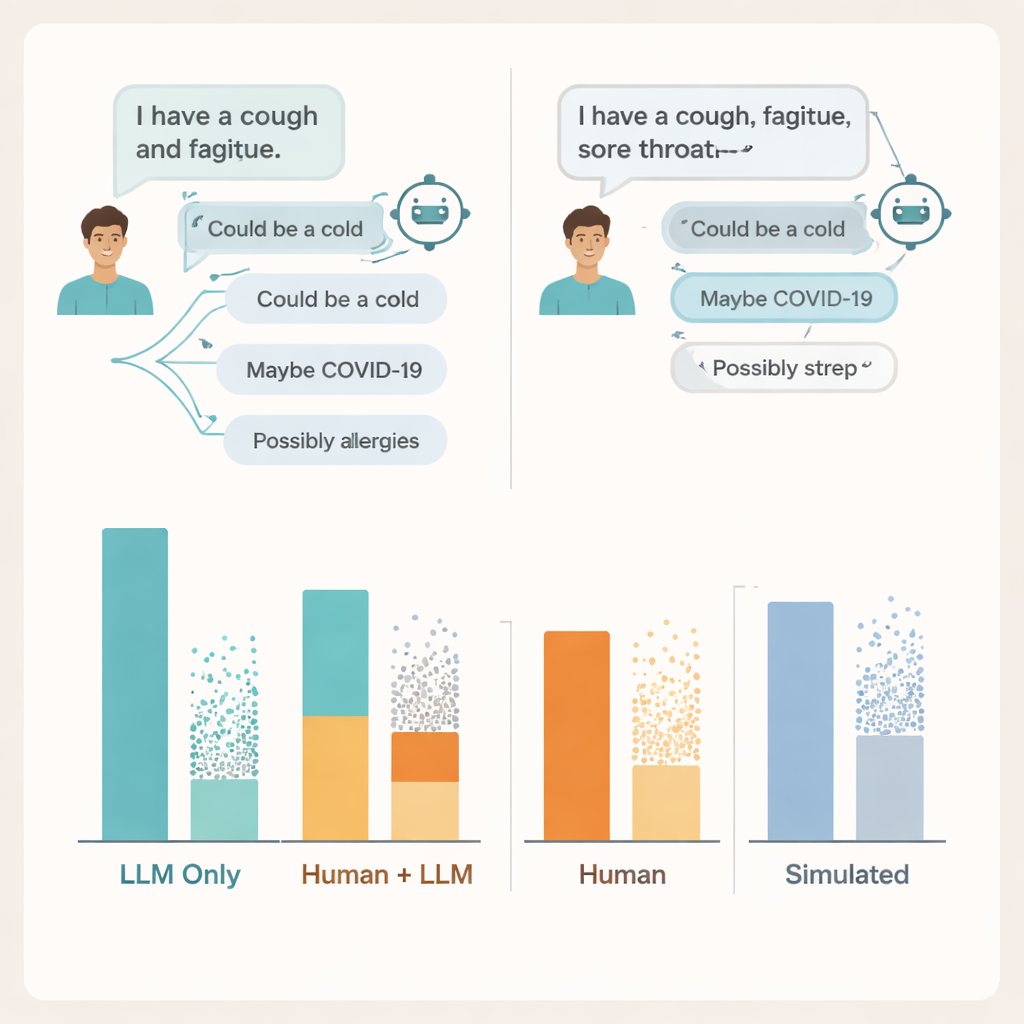
Dónde se rompe la conversación
Para entender por qué, los investigadores examinaron las transcripciones reales de los chats. Encontraron problemas en ambos lados de la conversación. Muchos usuarios no compartieron suficientes detalles sobre sus síntomas para que la IA diera un consejo sólido —del mismo modo que a veces los pacientes omiten información clave al hablar con un médico. Los modelos a menudo mencionaban al menos una condición relevante, pero también añadían varias posibilidades incorrectas o irrelevantes, y los usuarios tuvieron dificultades para discernir qué sugerencias eran importantes. En algunos casos, descripciones de síntomas casi idénticas llevaron a consejos muy distintos del mismo modelo, lo que dificultaba que la gente formara una idea clara de cuándo confiar en lo que veían en pantalla.
Por qué las pruebas estándar no detectan los riesgos reales
El equipo también comparó estos resultados con dos formas populares de evaluar IAs médicas: preguntas tipo examen de opción múltiple y chats totalmente simulados de “pacientes” ejecutados entre dos modelos. En ambas pruebas, los sistemas volvieron a parecer sólidos, alcanzando o superando las puntuaciones típicas de aprobación en preguntas al estilo examen y rindiendo mejor con pacientes simulados que con reales. Sin embargo, las altas puntuaciones en exámenes y las conversaciones simuladas pulidas no se correspondieron con el rendimiento de las personas reales al usar las mismas herramientas. Los autores sostienen que los criterios de referencia que miden el conocimiento aislado no capturan la naturaleza desordenada y frágil de las interacciones reales entre humanos e IA.
Qué significa esto para pacientes y sistemas de salud
Por ahora, concluye el estudio, los modelos de lenguaje de propósito general actuales no están listos para actuar como asesores de primera línea no supervisados para el público. Claramente contienen una gran cantidad de conocimiento médico, pero ese conocimiento no se traduce automáticamente en decisiones más seguras cuando personas ansiosas escriben preguntas parciales o confusas en casa. Hacer que la IA sea realmente útil en entornos de alto riesgo como la atención sanitaria exigirá más que mejores notas de examen: requerirá un diseño cuidadoso, pruebas con usuarios reales diversos y controles más estrictos sobre cómo se recopila, explica y confía la información en el ida y vuelta de la conversación.
Cita: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Palabras clave: chatbots médicos, autodiagnóstico, IA en salud, toma de decisiones del paciente, modelos de lenguaje amplio