Clear Sky Science · es
Anticipación y descubrimiento de metabolitos de mamíferos guiados por modelos de lenguaje químico
Química oculta dentro de nuestros cuerpos
Cada gota de sangre u orina contiene miles de pequeñas moléculas que reflejan lo que comemos, cómo vivimos y si nos estamos enfermando. Sin embargo, para la mayoría de estas moléculas, los científicos no conocen sus nombres ni su función. Este trabajo presenta DeepMet, un sistema de inteligencia artificial que «lee» el lenguaje de estas moléculas y predice cuáles faltan en nuestros mapas actuales de la química humana y animal. Al orientar los experimentos hacia los candidatos más prometedores, DeepMet ayuda a los investigadores a descubrir esta materia oscura química y a comprender mejor cómo funcionan nuestros cuerpos.
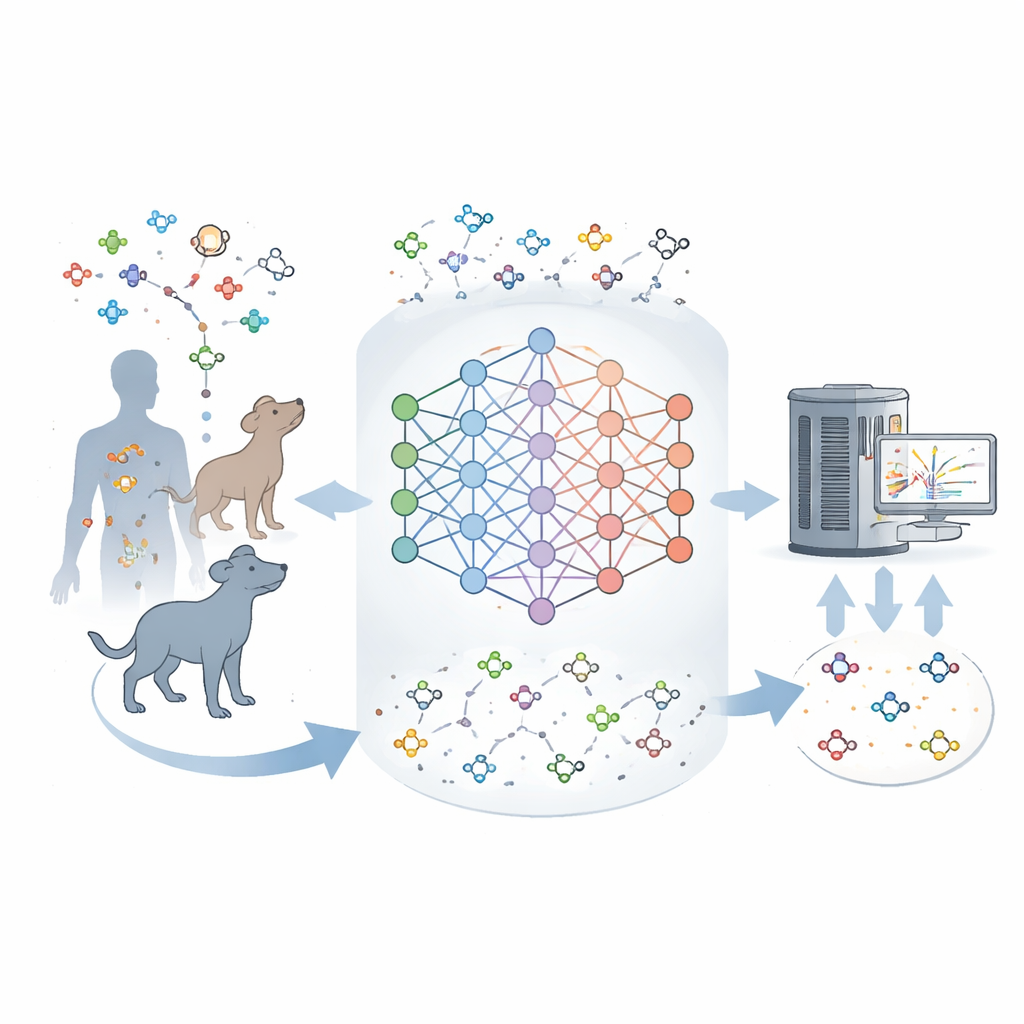
Por qué tantas moléculas siguen siendo desconocidas
Los instrumentos modernos pueden pesar y obtener huellas parciales de miles de moléculas en una muestra de tejido a la vez. Pero convertir esas huellas en estructuras exactas es difícil. Las bases de datos existentes listan muchos metabolitos conocidos, sin embargo la mayoría de las señales observadas en muestras reales no coinciden con nada en esos catálogos. Esta brecha sugiere que los mapas actuales del metabolismo están incompletos y que muchas moléculas naturales en mamíferos nunca se han descrito. Los autores se propusieron construir una herramienta que aprendiera de los metabolitos conocidos y luego imaginara los más plausibles que faltan, de forma similar a como los modelos de lenguaje predicen palabras probables en una frase.
Enseñar a una máquina la gramática del metabolismo
El equipo entrenó una red neuronal llamada DeepMet con aproximadamente 2.000 metabolitos humanos bien establecidos, codificando cada uno como una cadena corta que describe su estructura. Tras un entrenamiento inicial con moléculas similares a fármacos para aprender reglas químicas generales, DeepMet se ajustó finamente con este conjunto de metabolitos. Al solicitarle que generara nuevas estructuras, el modelo produjo moléculas que ocupaban las mismas regiones del espacio químico que los metabolitos reales e incluso reprodujeron muchos tipos conocidos de reacciones enzimáticas, a pesar de que nunca se le enseñaron esas reglas de forma explícita. En otras palabras, DeepMet pareció interiorizar la gramática no escrita que enlaza bloques básicos como azúcares y aminoácidos en pequeñas moléculas biológicamente realistas.
Predecir qué nuevas moléculas probablemente existen
Los investigadores muestrearon luego mil millones de moléculas candidatas desde DeepMet y contaron con qué frecuencia aparecía cada estructura única. Las estructuras que se repetían con frecuencia tendían a parecerse más a metabolitos conocidos, compartir núcleos químicos comunes con ellos y ajustarse a transformaciones enzimáticas plausibles. Para probar si estos candidatos de alta frecuencia correspondían a moléculas reales, el equipo comparó las predicciones de DeepMet con los metabolitos que se añadieron a la Human Metabolome Database después de que se cerraran los datos de entrenamiento del modelo. DeepMet ya había generado la mayoría de esos descubrimientos posteriores y clasificó muchos de ellos entre sus candidatos más probables. De entre los miles de estructuras de alto rango ausentes en las bases de datos, los autores compraron o sintetizaron 80 y comprobaron muestras humanas reales mediante espectrometría de masas. Confirmaron la presencia de varios metabolitos previamente no reconocidos, algunos de los cuales habían sido pasados por alto pese a aparecer en la literatura existente.
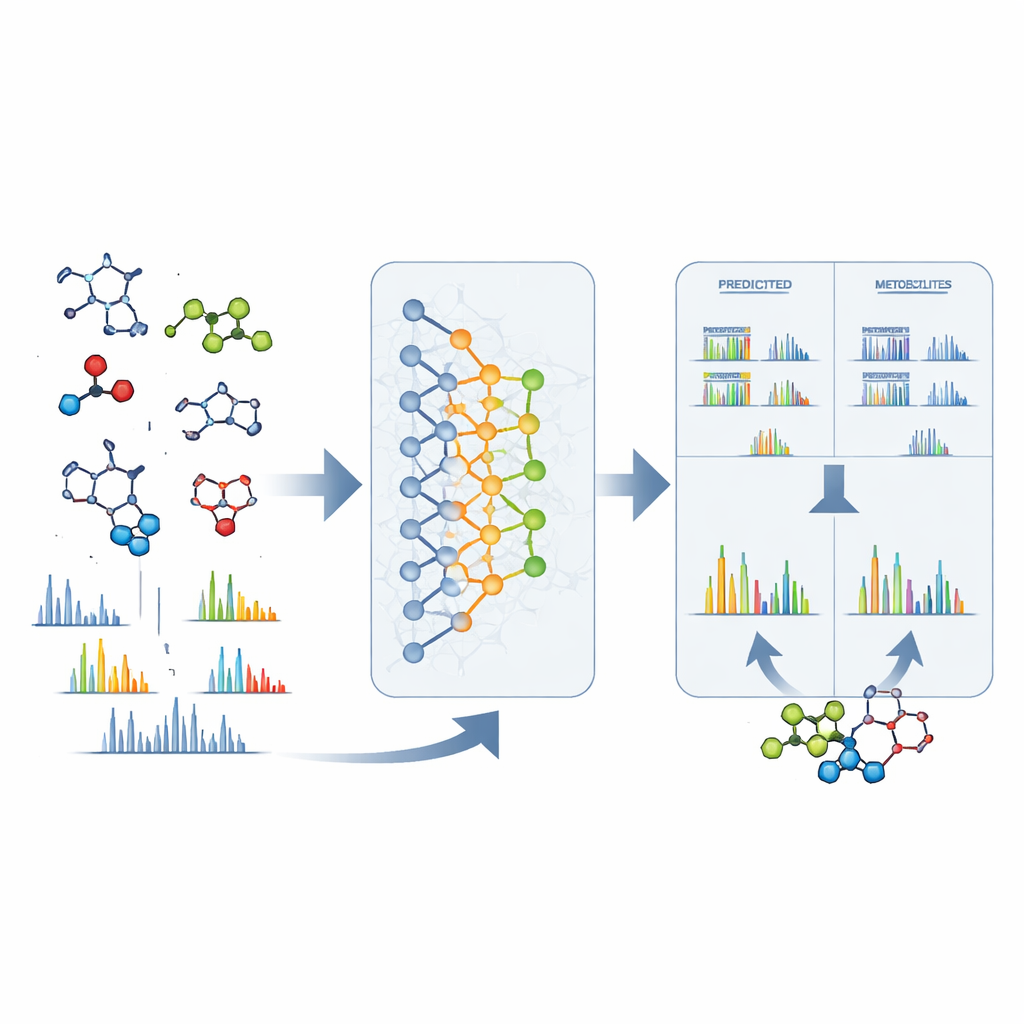
De señales crudas a estructuras concretas
DeepMet también es útil cuando ya se ha detectado un pico desconocido en un espectrómetro de masas. Dada solo la masa exacta de una molécula misteriosa, el modelo puede listar muchas estructuras que pesarían lo mismo y ordenarlas según cuán parecidas sean a metabolitos. En casi un tercio de los casos de prueba, la estructura correcta ocupó el primer puesto; en muchos más, apareció entre un puñado de candidatos mejor valorados y por lo general era muy similar en forma a la preferida por el modelo. Para afinar aún más, los autores combinaron DeepMet con software separado que predice cómo se fragmentaría cada candidato en un espectrómetro de masas. Comparar estos patrones predichos con espectros experimentales reales duplicó aproximadamente la precisión en la identificación. Buscar en grandes conjuntos de datos públicos con este enfoque combinado arrojó estructuras tentativas para muchas señales previamente anónimas y señaló metabolitos que difieren según enfermedades, dietas y estados del microbioma.
Iluminar la materia oscura química de la vida
Al combinar la intuición química aprendida a partir de datos con un potente emparejamiento de patrones contra espectros de masas, DeepMet ofrece una hoja de ruta para descubrir nuevos metabolitos de manera dirigida y práctica. Aún no puede revelar toda molécula desconocida: algunas estructuras están demasiado alejadas de las que ha visto y ciertos isómeros siguen siendo indistinguibles sin métodos especializados. Pero el estudio muestra que las herramientas al estilo de modelos de lenguaje no solo pueden inventar moléculas realistas, sino también anticipar compuestos reales que los biólogos confirmarán posteriormente en animales y humanos. Para un lector general, la conclusión es que la IA puede ahora ayudar a los químicos a descubrir sistemáticamente la química oculta en nuestros cuerpos, revelando potencialmente nuevos biomarcadores, rastreando vínculos dieta–microbio–huésped y transformando poco a poco la materia oscura metabólica de hoy en la biología bien cartografiada de mañana.
Cita: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Palabras clave: metabolómica, modelos de lenguaje químico, DeepMet, espectrometría de masas, materia oscura metabólica