Clear Sky Science · es
Descubriendo picos clave para la autenticación del aceite de oliva mediante espectroscopía Raman y quimioinformática
Por qué importa la historia del fraude del aceite de oliva
Cuando pagas más por una botella de aceite de oliva esperas el producto auténtico, no una mezcla diluida con aceites de semillas más baratos. Sin embargo, debido al alto valor del aceite de oliva y a la complejidad del comercio global, el fraude y el etiquetado incorrecto son problemas frecuentes. Este estudio presenta una forma rápida y no destructiva de detectar esos fraudes: se ilumina el aceite con un láser y se dejan que programas informáticos avanzados interpreten las huellas químicas ocultas. El enfoque busca proteger a consumidores, productores honestos y supervisores, facilitando la verificación de si lo que hay en la botella coincide con lo que indica la etiqueta.
Iluminar para leer las huellas digitales del aceite
Los investigadores emplearon una técnica llamada espectroscopía Raman, que consiste en dirigir un haz de luz concentrado sobre una muestra y medir cómo la luz se dispersa. Diferentes moléculas vibran de formas propias, dejando un patrón de picos en el espectro resultante, algo así como un código de barras. El aceite de oliva y adulterantes comunes como los aceites de girasol, colza y maíz tienen mezclas distintas de ácidos grasos y pigmentos naturales, por lo que sus espectros no son idénticos. Al estudiar estos patrones en aceites puros y en mezclas preparadas con precisión, el equipo pudo identificar un conjunto reducido de “picos clave” cuya forma e intensidad cambiaban de manera fiable según aumentara o disminuyera la proporción de aceite de oliva en la mezcla.
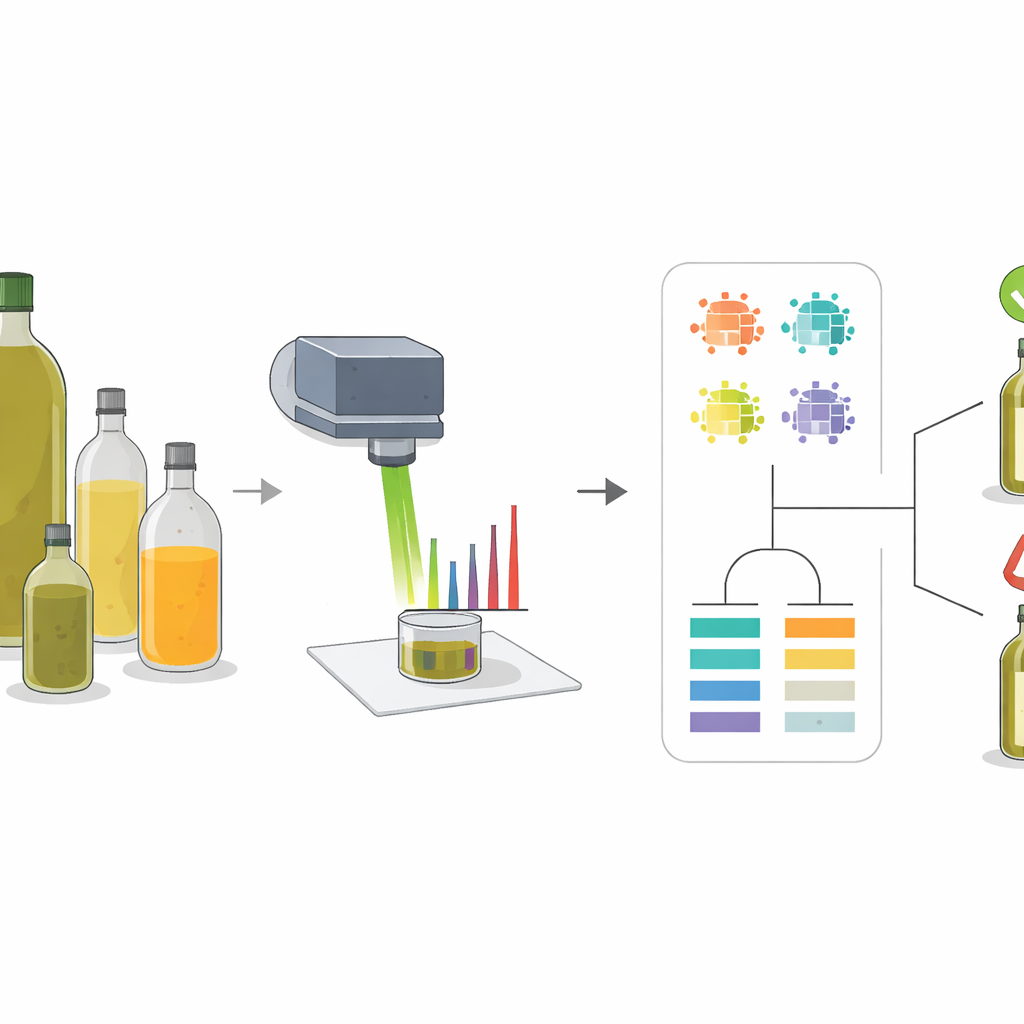
Encontrar las señales más reveladoras
En lugar de basarse en una sola medición, el equipo extrajo varios descriptores de cada pico importante: su altura (intensidad), el área que abarcaba, su anchura a media altura y cómo su área se comparaba con la de otros picos. A continuación usaron agrupamiento y mapas de correlación para ver cómo estos descriptores diferenciaban los aceites y cómo variaban cuando aumentaba el contenido de aceite de oliva. Los picos asociados a compuestos de color como el beta-caroteno y a ciertos tipos de grasas insaturadas resultaron especialmente informativos. Por ejemplo, algunos picos se reforzaban al subir el porcentaje de aceite de oliva, mientras que otros se aten uaban porque estaban ligados al ácido linoleico, más abundante en el aceite de girasol. Esta visión multicaracterística capturó diferencias sutiles que se perderían si solo se considerara un valor único de intensidad.
Dejar que los algoritmos separen lo genuino de lo adulterado
Para convertir estas huellas espectrales en decisiones prácticas, los autores entrenaron varios modelos de aprendizaje automático. Primero pidieron a los modelos que clasificaran diez tipos de aceite, incluidos cuatro aceites puros y seis tipos de mezclas binarias y ternarias. Los métodos basados en árboles —bosques aleatorios y árboles potenciados por gradiente— fueron los que mejor funcionaron, asignando correctamente casi todas las muestras a la categoría adecuada cuando se les proporcionaba el conjunto completo de características de los picos. Luego aplicaron el mismo tipo de modelos a una tarea numérica: predecir el porcentaje real de aceite de oliva en mezclas de dos y tres aceites. De nuevo, los enfoques basados en árboles superaron a métodos más tradicionales, siguiendo con precisión el contenido de oliva incluso cuando las señales de diferentes aceites se solapaban fuertemente en los espectros.
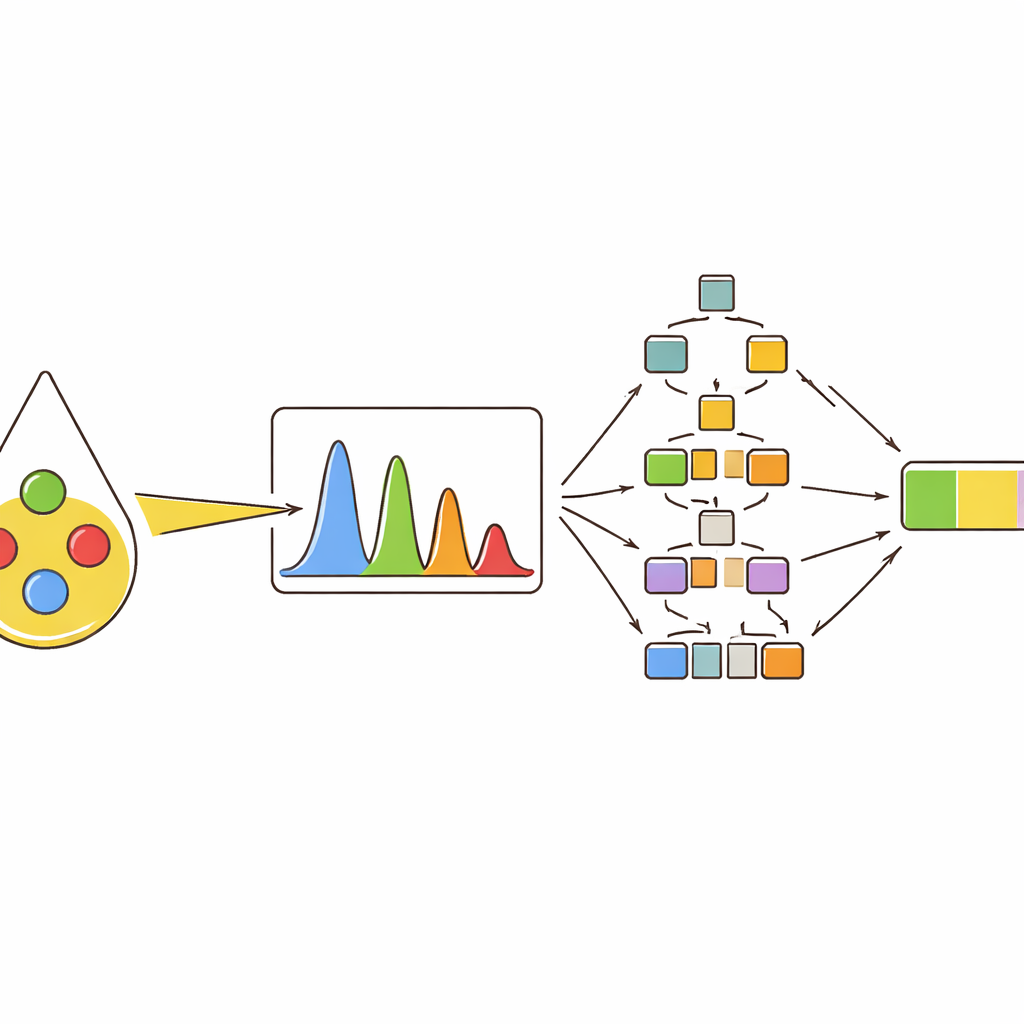
Abrir la caja negra de los modelos inteligentes
Muchas herramientas potentes de aprendizaje automático son difíciles de interpretar; pueden funcionar bien pero aportar poca información sobre por qué tomaron una decisión concreta. Para abordar esto, el estudio empleó un método de explicación que asigna a cada característica de entrada una contribución a la predicción final. Esto reveló que unos pocos picos específicos dominaban las decisiones de los modelos, inclinando consistentemente la predicción del contenido de oliva hacia arriba o hacia abajo según sus valores. Esos mismos picos aparecían como los más importantes en distintos tipos de mezclas y en pruebas con aceites comerciales de supermercado, que contenían solo una pequeña cantidad de aceite de oliva. Para esas muestras del mundo real, los mejores modelos estimaron el contenido de oliva muy cerca del valor real, lo que respalda tanto la precisión como la transparencia del enfoque.
Qué significa esto para la botella que tienes en casa
En términos prácticos, el trabajo muestra que un escaneo rápido basado en luz, interpretado por modelos informáticos bien diseñados y explicables, puede decir si un “aceite de oliva” es puro, está fuertemente diluido o se encuentra en algún punto intermedio. Al centrarse en unas pocas características espectrales robustas y combinarlas en algoritmos avanzados pero interpretables, los investigadores construyeron una herramienta que podría integrarse en controles rutinarios de calidad, potencialmente incluso en dispositivos portátiles. Aunque aún hace falta ensayar el método en más regiones, variedades y tipos de fraude, este marco apunta a un futuro en el que verificar la honestidad de alimentos de alto valor como el aceite de oliva sea más rápido, sencillo y fiable para todos.
Cita: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Palabras clave: autenticación del aceite de oliva, detección de fraude alimentario, espectroscopía Raman, aprendizaje automático, calidad de aceites comestibles