Clear Sky Science · es
XL-MSDigger: una solución versátil basada en aprendizaje profundo para espectrometría de masas con entrecruzamiento
Ver cómo se mantienen unidas las proteínas
Cada proceso en nuestro cuerpo depende no solo de que las proteínas adopten las formas correctas, sino también de que encuentren a los socios adecuados. Sin embargo, observar estas relaciones moleculares en acción es notoriamente difícil. Este estudio presenta XL-MSDigger, una plataforma de software que utiliza inteligencia artificial moderna para extraer señales mucho más claras de una técnica experimental ruidosa llamada espectrometría de masas con entrecruzamiento, ayudando a los científicos a mapear cómo se organizan las proteínas y con quién interactúan dentro de las células.
Desenredando un mundo molecular abarrotado
Para aprender cómo se construyen las proteínas y cómo se conectan, los investigadores suelen usar la espectrometría de masas con entrecruzamiento. En este enfoque, pequeños "puentes" químicos unen partes cercanas de las proteínas. Las piezas enlazadas se rompen en fragmentos y se pesan en un espectrómetro de masas. En principio, el patrón de fragmentos revela qué partes de las proteínas estaban próximas en el espacio, como identificar qué páginas de un libro estaban sujetas entre sí. En la práctica, sin embargo, los datos resultantes son extremadamente complejos. Las herramientas informáticas existentes se fijan principalmente en la información básica de masa y tienen dificultades con el enorme número de combinaciones posibles, lo que conduce a conexiones perdidas y coincidencias espurias.
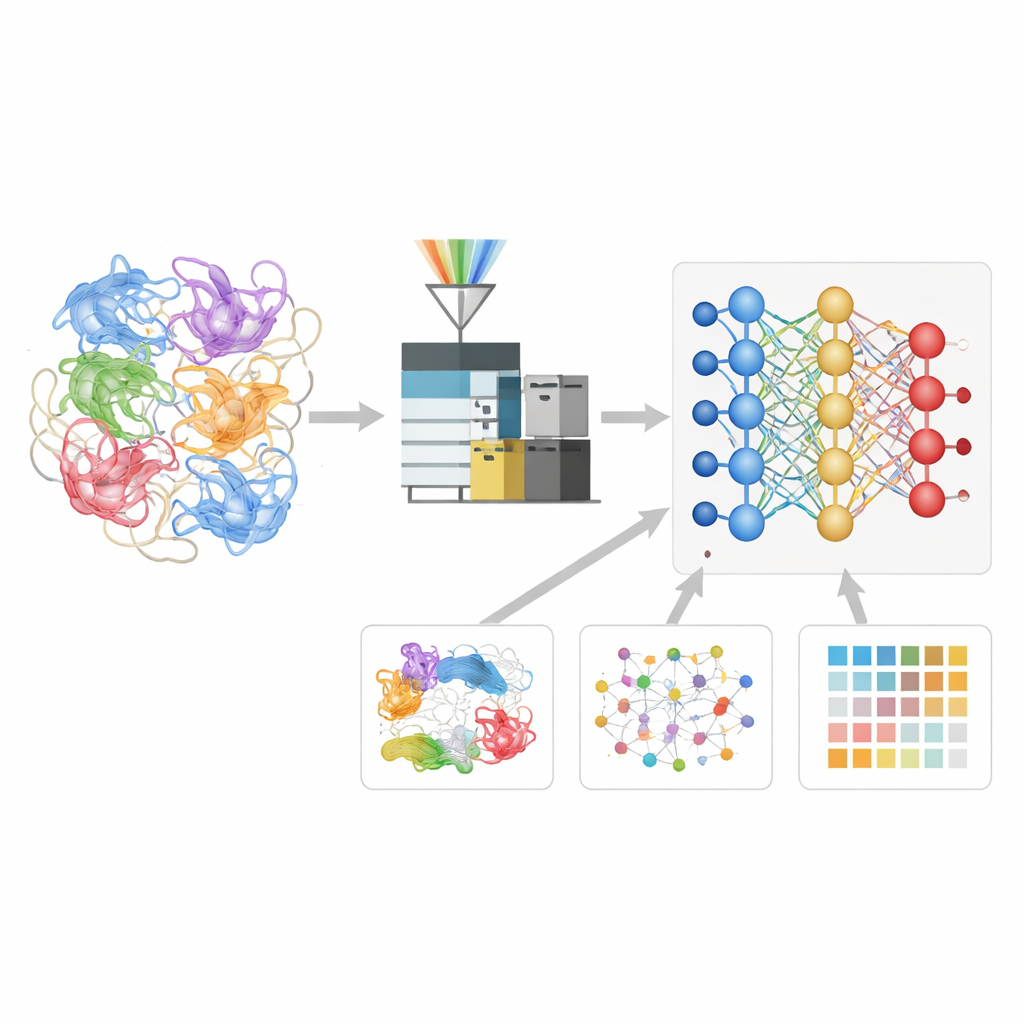
Enseñar a una red neuronal el lenguaje de los fragmentos proteicos
Los autores construyeron un modelo de aprendizaje profundo llamado Deep4D-XL para interpretar mejor estos experimentos de entrecruzamiento. Primero crearon un gran conjunto de referencia entrecruzando proteínas de células humanas, fragmentándolas en péptidos y registrando no solo sus masas, sino también cuánto tardaban en viajar por el instrumento y cómo se comportaban en una cámara de movilidad iónica. Cada par entrecruzado se codificó para el modelo, que emplea un diseño gemelo tipo "Siamese" para leer ambos péptidos asociados y un paso de atención cruzada para combinar su información. A partir de esto, la red aprende a predecir tres propiedades clave de cualquier péptido entrecruzado nuevo: cuándo debería aparecer en el experimento, cómo debería desplazarse y cómo debería ser su patrón de fragmentación.
Convertir predicciones en señales más limpias
XL-MSDigger envuelve este motor de predicción en flujos de análisis para dos estilos principales de adquisición de datos. En el estilo tradicional y dirigido, el instrumento registra selectivamente fragmentos de iones que elige en tiempo real. XL-MSDigger toma las coincidencias iniciales de programas de búsqueda establecidos y las reevalúa usando el comportamiento predicho por el modelo para cada candidato. Una segunda red neuronal compara predicción y experimento a lo largo de varias dimensiones y asigna puntuaciones mejoradas. Este reescalado casi duplica el número de enlaces detectados con confianza entre diferentes proteínas en muestras de levadura y humana, manteniendo bajas las tasas de error y revelando muchas más interacciones proteína–proteína que antes.
Dar sentido a avalanchas de datos sin sesgo
Una forma más reciente de operar estos instrumentos, llamada adquisición independiente de datos, registra fragmentos de casi todo en una muestra, mejorando la cobertura pero generando datos abrumadores. Hasta ahora, no había una buena forma de estimar cuántos de los entrecruzamientos resultantes eran realmente reales. XL-MSDigger utiliza Deep4D-XL para construir una biblioteca "señuelo" cuidadosamente emparejada de entrecruzamientos falsos y luego analiza entradas reales y señuelo juntas. Al ver con qué frecuencia los señuelos se cuelan, el software puede estimar la tasa de descubrimiento falso y entrenar otra red neuronal para separar coincidencias verdaderas de las falsas. Este reescalado aumenta aproximadamente cinco veces el número de señales entrecruzadas confiables y produce una separación clara entre patrones reales y señuelo.
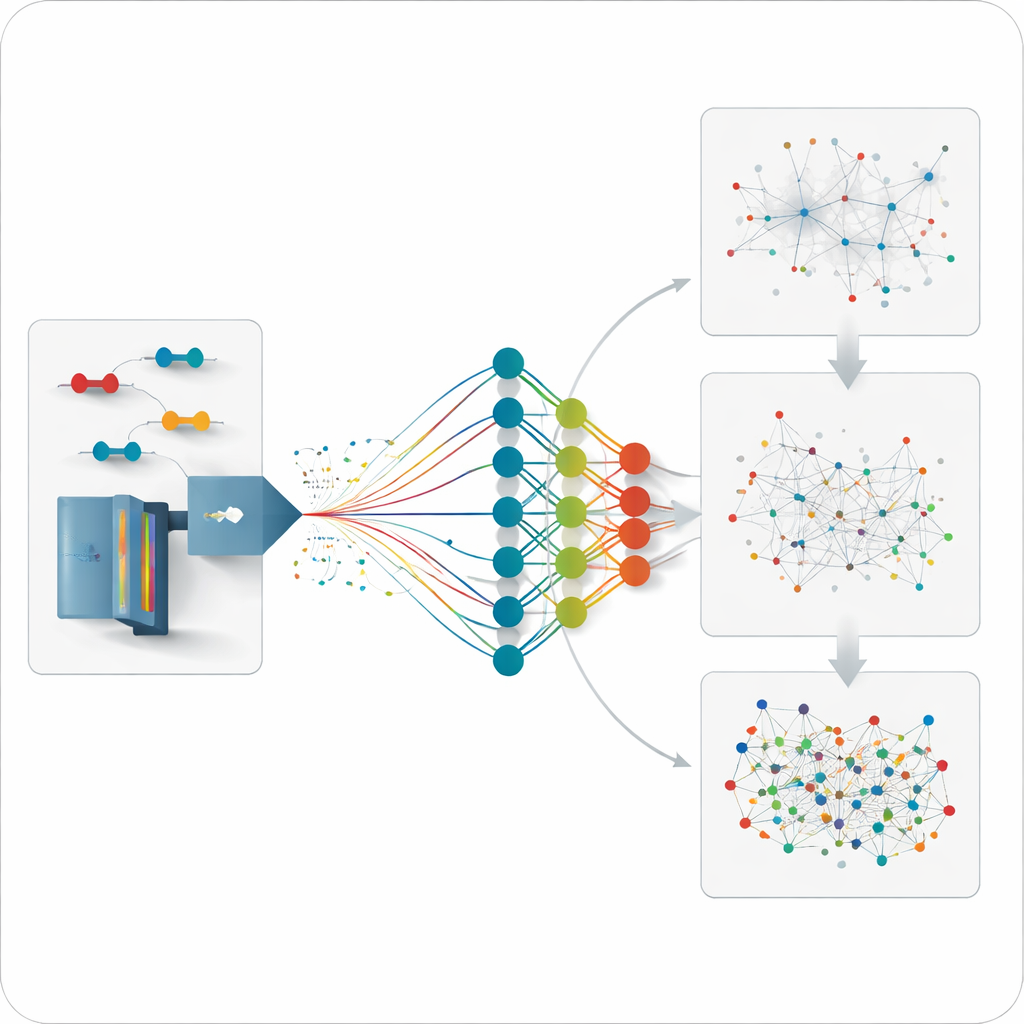
Predecir lo que aún no se ha medido
Dado que el modelo puede prever cómo debería comportarse cualquier péptido entrecruzado plausible, el equipo puede dar un paso más y analizar datos de enlaces que nunca se midieron directamente antes. Generan bibliotecas predichas de tamaño moderado centradas en proteínas seleccionadas o redes de interacción y luego buscan en los datos no sesgados contra estas bibliotecas. Esta estrategia descubre enlaces adicionales dentro de proteínas individuales y entre socios de chaperonas importantes, con distancias que concuerdan bien con estructuras tridimensionales conocidas. También recupera interacciones que fueron pasadas por alto por las bibliotecas experimentales tradicionales, más limitadas, especialmente para conexiones de baja abundancia.
Abrir una ventana más clara a las asociaciones proteicas
Para no especialistas, el mensaje clave es que XL-MSDigger actúa como un reconocedor de patrones altamente entrenado superpuesto a un método experimental ya potente. Al aprender cómo deberían verse las señales genuinas de entrecruzamiento en varias dimensiones a la vez, puede cribar conjuntos de datos vastos y desordenados, descartar impostores probables y rescatar conexiones proteicas reales pero previamente ocultas. Aunque las aplicaciones completas a nivel de proteoma requerirán aún gran potencia de cálculo, este trabajo muestra que combinar experimentos de entrecruzamiento con aprendizaje profundo puede afinar considerablemente nuestra visión de cómo se organizan las proteínas y con quién se encuentran dentro de la célula.
Cita: Chen, M., Hao, Y., Huang, X. et al. XL-MSDigger: a deep learning-based, versatile solution for cross-linking mass spectrometry. Nat Commun 17, 2554 (2026). https://doi.org/10.1038/s41467-026-69489-8
Palabras clave: interacciones proteicas, espectrometría de masas con entrecruzamiento, aprendizaje profundo, proteómica, adquisición independiente de datos