Clear Sky Science · es
Un conjunto de datos de fMRI a 7T con imágenes sintéticas para modelado fuera de distribución de la visión
Por qué esto importa para entender la visión y la IA
Nuestros ojos captan una enorme variedad de imágenes cada día, desde bosques y rostros hasta señales de tráfico y ruido en la pantalla. Sin embargo, la mayoría de los estudios sobre el cerebro y la inteligencia artificial se basan en una porción estrecha de ese mundo visual: fotografías de escenas naturales. Este artículo presenta un nuevo tipo de conjunto de datos cerebrales que rompe deliberadamente con esa zona de confort, usando imágenes sintéticas diseñadas con cuidado para poner a prueba tanto nuestras teorías sobre la visión humana como los modelos de IA inspirados en ella.
Construyendo un nuevo banco de pruebas visual
Los autores amplían el influyente Natural Scenes Dataset (NSD), que registró actividad cerebral de ultra alta resolución con resonancia magnética a 7 teslas mientras las personas veían decenas de miles de fotografías. Ese conjunto de datos original ya ha impulsado algunos de los modelos más precisos de cómo la corteza visual responde a las imágenes. Pero dado que todas esas imágenes son fotografías relativamente ordinarias, resulta difícil saber si un modelo que funciona bien en el NSD captura principios generales de la visión o simplemente se ha especializado en ese tipo específico de imágenes. Para abordar esto, el equipo escaneó de nuevo a los mismos ocho voluntarios, esta vez mostrándoles 284 imágenes “sintéticas” que deliberadamente salen del mundo fotográfico habitual.
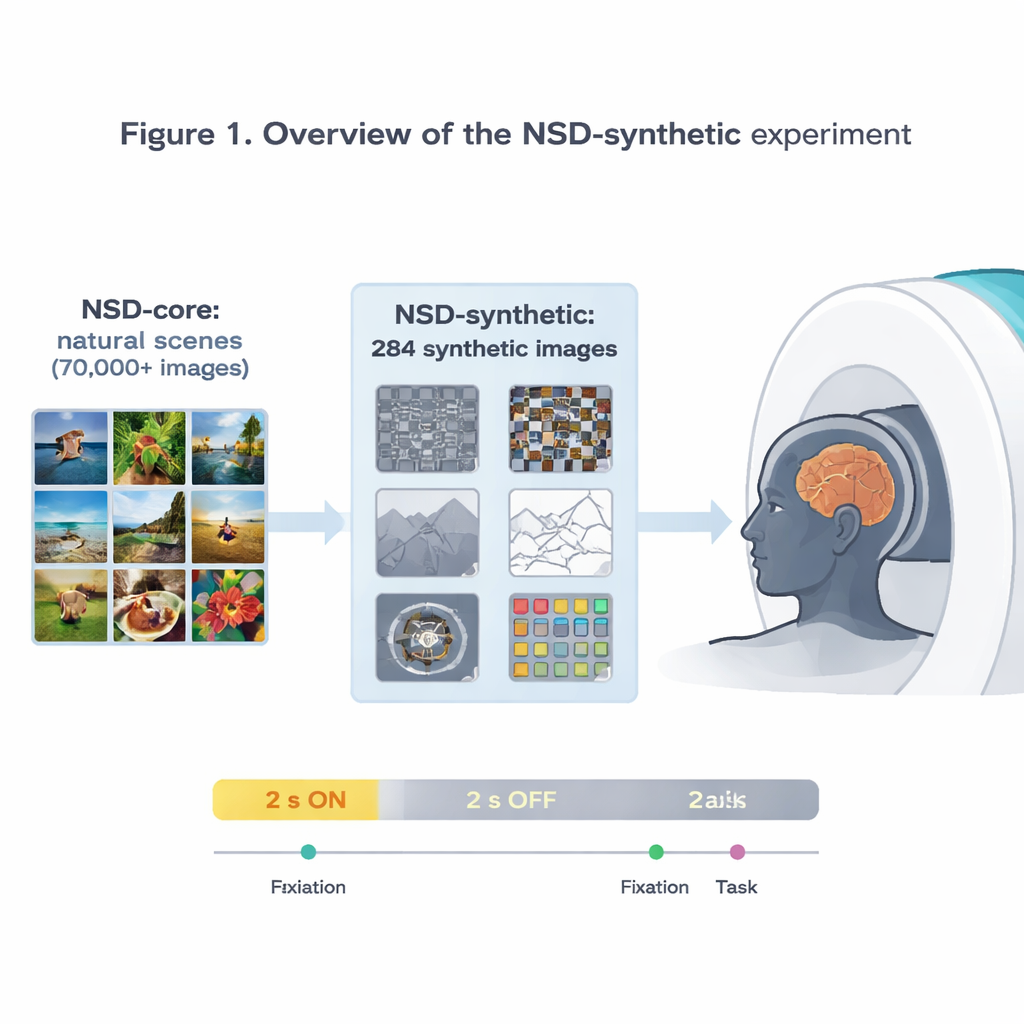
Imágenes extrañas, respuestas cerebrales fiables
Las imágenes sintéticas abarcan ocho familias: distintos tipos de ruido visual, escenas naturales simples y sus versiones alteradas (como invertidas o en dibujos lineales), escenas con contraste reducido o fase mezclada, palabras sueltas colocadas en varias posiciones, rejillas en espiral que exploran la sensibilidad a patrones finos y parches de ruido muy coloreados. Mientras las personas se concentraban en un diminuto punto parpadeante o realizaban una simple tarea de comparación de imágenes, los investigadores midieron la actividad cerebral cada 1,6 segundos. Muestran que estos estímulos de aspecto extraño siguen produciendo señales fuertes y fiables, especialmente en las áreas visuales tempranas que responden a características básicas como bordes, contraste y color. Los patrones de actividad en la corteza coinciden con preferencias bien conocidas de regiones especializadas, como un área selectiva para palabras que responde más a palabras colocadas en el centro y un área selectiva para escenas que responde más a imágenes de entornos.
Demostrar que los datos son realmente “fuera de distribución”
Para que este nuevo conjunto de datos desafíe a los modelos, sus respuestas cerebrales deben ser genuinamente diferentes de las evocadas por fotografías naturales. Los autores comprimen los patrones de actividad tanto del NSD original como de la sesión sintética en un mapa bidimensional que refleja cuán similares son las respuestas entre imágenes. En ese espacio, las respuestas a las imágenes sintéticas se agrupan separadamente de las respuestas a fotos naturales, incluso al tener en cuenta las diferencias entre sesiones de exploración. Además, las imágenes sintéticas se agrupan naturalmente según su tipo visual—ruido con ruido, rejillas con rejillas, etc.—mostrando que el cerebro organiza estos estímulos de acuerdo con su estructura subyacente y no solo por su apariencia superficial.
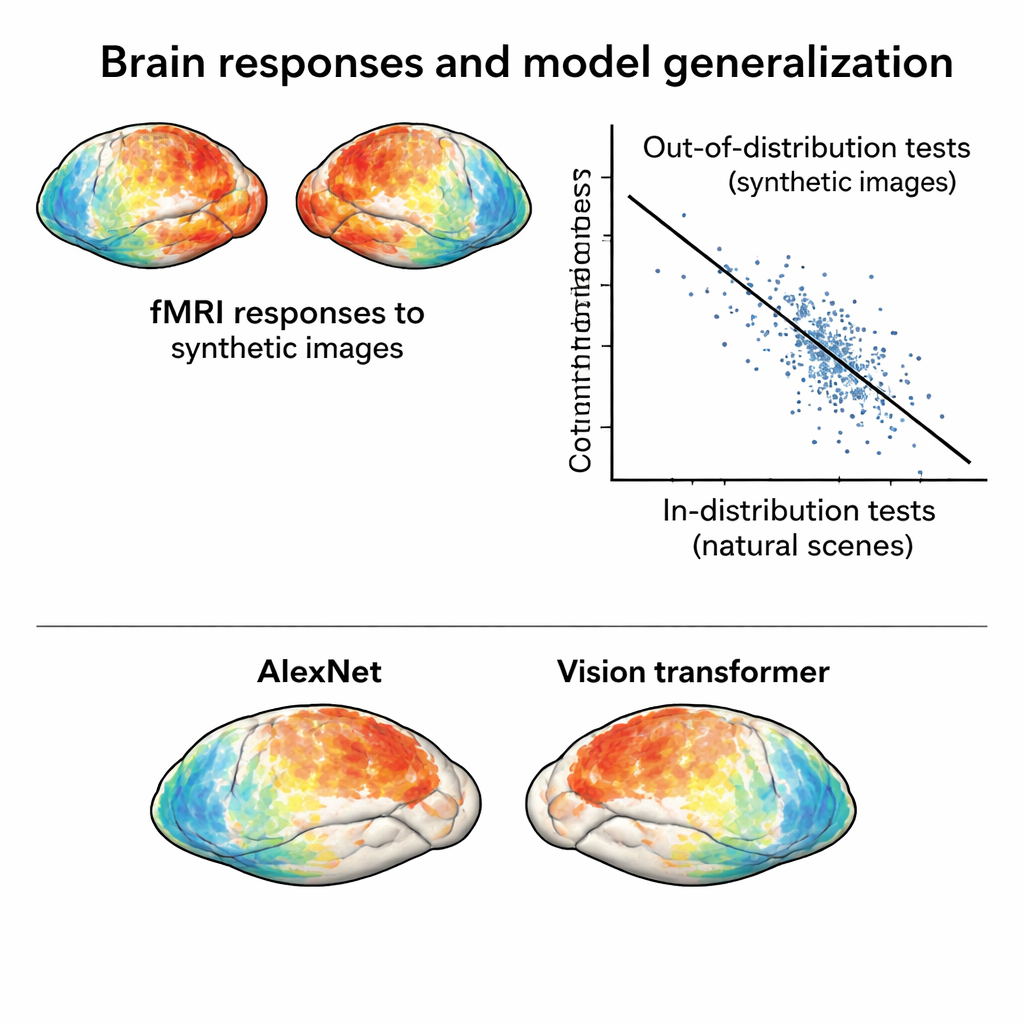
Ponerse más exigente con los modelos cerebrales y de IA
Con este nuevo conjunto “fuera de distribución” en mano, el equipo entrena modelos de codificación estándar: herramientas matemáticas que predicen respuestas cerebrales a partir de características de imagen extraídas por redes neuronales profundas. Los modelos entrenados únicamente con las fotos naturales funcionan bien cuando se prueban con fotos similares, pero su precisión cae notablemente al predecir respuestas a las imágenes sintéticas. Esa caída no se debe a datos ruidosos—las respuestas sintéticas son en realidad muy limpias—sino a fallos reales del modelo. De forma crucial, comparar distintas arquitecturas de redes neuronales bajo estas condiciones más duras revela contrastes que apenas aparecen en pruebas dentro de distribución. Por ejemplo, un transformador de visión moderno y una red auto‑supervisada superan a las redes convolucionales clásicas frente a imágenes sintéticas, lo que sugiere que la forma en que se entrena un modelo marca fuertemente su robustez.
¿Hasta qué punto pueden alejarse los modelos de las imágenes familiares?
Los autores van más allá y tratan la “distancia” respecto a los datos de entrenamiento como un continuo, no como una etiqueta binaria. Miden cuánto se separa la respuesta cerebral de cada imagen de la nube de respuestas a escenas naturales. Cuanto más lejos está una imagen sintética en ese espacio, peor tienden a funcionar los modelos y menos precisión tienen para identificar qué imagen vio una persona basándose solo en la actividad cerebral. También muestran que incluso dentro del mundo de las fotografías ordinarias, conjuntos de prueba escogidos con habilidad pueden comportarse como “ligeramente fuera de distribución”: los modelos rinden mejor con imágenes extraídas del mismo clúster que su conjunto de entrenamiento, peor con escenas naturales lejanas y peor aún con los estímulos sintéticos. Este panorama escalonado convierte al nuevo conjunto de datos en una herramienta para sondear exactamente qué tipos de estructura visual los modelos actuales pasan por alto.
Qué significa esto para la investigación futura en cerebro e IA
Para los no especialistas, el mensaje clave es que un rendimiento alto en imágenes familiares no garantiza que un modelo de IA inspirado en el cerebro haya captado realmente cómo vemos. Al publicar NSD‑synthetic junto con el NSD original, los autores proporcionan una «pista de choque» pública para modelos de visión: una forma de ver dónde fallan cuando las imágenes se vuelven más abstractas, más coloridas o menos naturales. Dado que el conjunto de datos está disponible abiertamente y está integrado con un recurso ya existente y ampliamente usado, probablemente se convertirá en un referente estándar para probar y mejorar teorías de la visión humana y las redes artificiales que intentan imitarla.
Cita: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Palabras clave: corteza visual, conjunto de datos fMRI, imágenes sintéticas, fuera de distribución, redes neuronales profundas