Clear Sky Science · es
Mecanismos computacionales de una sola neurona para la codificación visual de objetos en el lóbulo temporal humano
Cómo el cerebro reconoce aquello que miramos
Cada vez que miras una calle concurrida, tu cerebro te indica al instante qué formas son personas, cuáles son coches y cuáles son señales, incluso si están parcialmente ocultas o mal iluminadas. Este artículo plantea una pregunta aparentemente sencilla: ¿cómo transforma el cerebro humano el torrente de detalles visuales crudos que llegan a los ojos en ideas estables como “perro” o “taza” que podemos reconocer, recordar y nombrar?
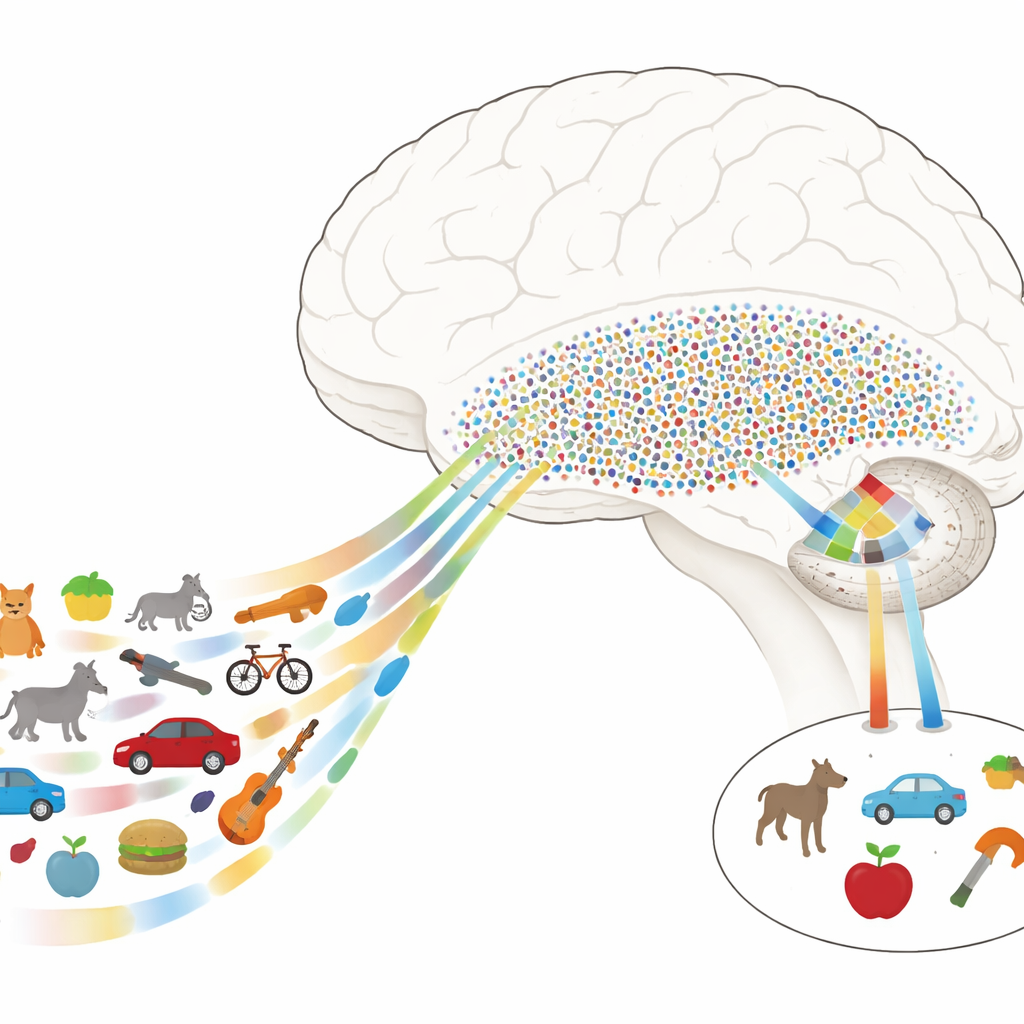
De imágenes detalladas a objetos con significado
Los científicos saben que el reconocimiento de objetos depende en gran medida de una cadena de regiones en la parte inferior del cerebro llamada vía visual ventral. Las etapas iniciales tratan rasgos simples como bordes y texturas, mientras que las etapas posteriores se ocupan más de objetos completos y su significado. En humanos, un tramo clave de esta vía es la corteza temporal ventral (CTV), y justo aguas abajo se encuentra el lóbulo temporal medial (LTM), crucial para la memoria. El enigma ha sido cómo pasa el cerebro de las descripciones detalladas y tipo imagen de la CTV a los códigos escasos y tipo concepto del LTM que permiten que unas pocas neuronas representen muchas vistas diferentes de un mismo objeto.
Un mapa neuronal del espacio de objetos
Los autores registraron la actividad eléctrica directamente en cerebros de pacientes con epilepsia que ya tenían electrodos implantados por razones médicas. Mientras los pacientes realizaban una tarea sencilla, veían cientos de imágenes naturales extraídas de muchas categorías —animales, herramientas, alimentos, vehículos, plantas y más. En la CTV, los investigadores hallaron que las respuestas podían describirse como combinaciones de unas pocas direcciones de rasgo clave, u “ejes”, por ejemplo qué tan natural frente a artificial parece algo, o si es animado frente a inanimado. Al combinar matemáticamente estos ejes, construyeron un “espacio de rasgos neuronal” en el que cada imagen ocupa una ubicación, y los objetos similares se agrupan aunque difieran en detalles de bajo nivel.
De rejillas densas de rasgos a centros conceptuales escasos
En este espacio de rasgos neuronal, la CTV actúa como una rejilla densa: muchos sitios participan en la representación de cada objeto, codificando diferencias visuales finas. En contraste, las neuronas registradas individualmente en el LTM se comportaron de forma muy distinta. En lugar de seguir rasgos individuales, muchas de estas células responden con fuerza solo a objetos que caen dentro de regiones concretas del espacio de rasgos de la CTV. Cada una de esas neuronas tenía efectivamente un “campo receptivo” no en el espacio físico, sino en este mapa abstracto de propiedades de objetos. Los objetos que caían dentro de la región preferida de una neurona compartían a menudo rasgos perceptuales (por ejemplo, formas redondeadas o colores verdosos) y significados de nivel superior (como ser seres vivos o herramientas), lo que llevaba a que esa neurona disparara de forma escasa pero selectiva.
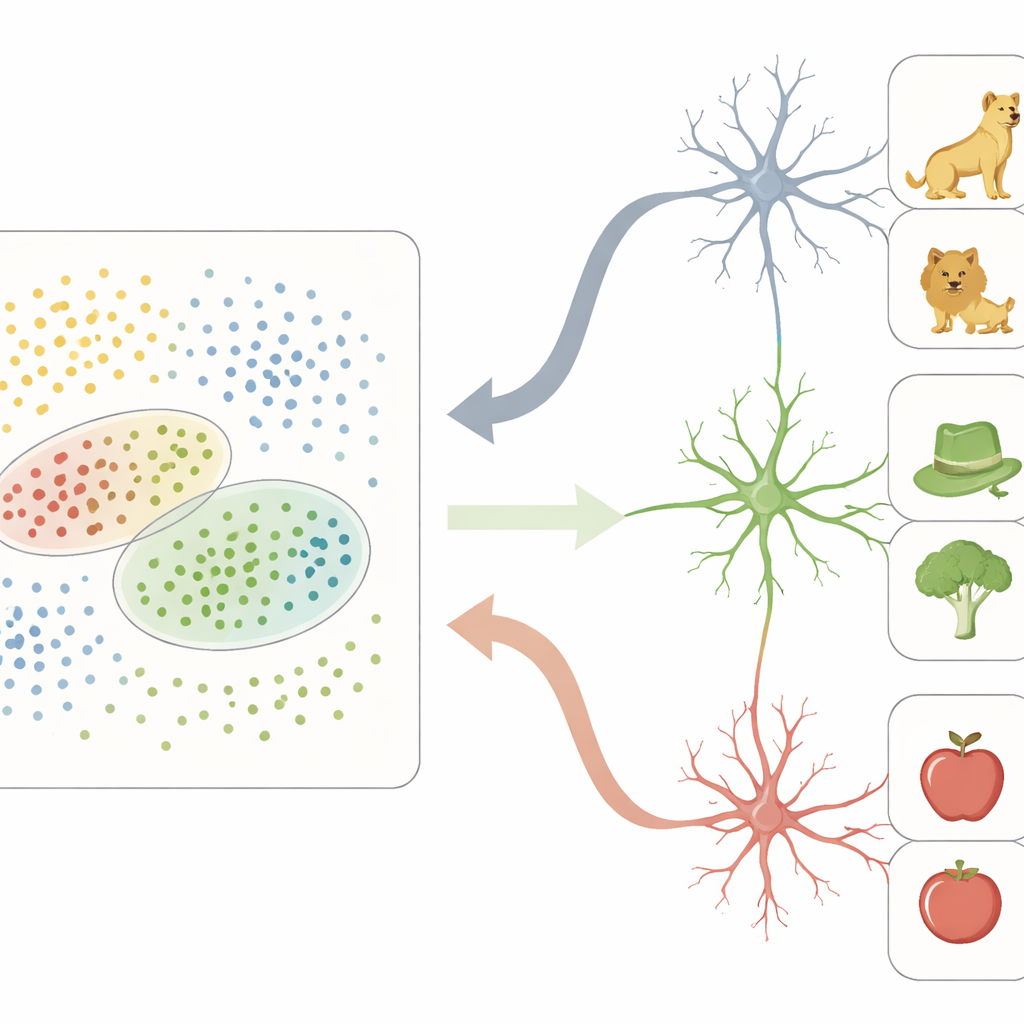
Conectando visión y memoria
Para demostrar que esto no es solo un truco matemático, el equipo examinó cómo interactúan estas áreas cerebrales en tiempo real. Encontraron que los sitios de la CTV que transmitían señales fuertes de ejes de rasgo estaban especialmente sincronizados con sitios sensibles a categorías en el LTM, particularmente en determinadas ondas rítmicas del cerebro. La información tendía a fluir de la CTV al LTM en frecuencias más bajas asociadas al procesamiento feedforward, mientras que la retroalimentación del LTM a la CTV se modulaba en frecuencias algo más altas. De forma crucial, cuando una neurona del LTM estaba sintonizada con una región específica del espacio de rasgos, sus disparos se alineaban con ritmos rápidos en la CTV, y este acoplamiento era más fuerte para las imágenes concretas que esa neurona codificaba. Un segundo conjunto de experimentos con otra colección de imágenes confirmó que tanto el mapa de rasgos de la CTV como la sintonía regional del LTM eran estables entre conjuntos de estímulos.
Por qué esto importa para ver y recordar en la vida cotidiana
En conjunto, estos resultados apoyan una historia computacional concreta: la CTV despliega objetos visuales a lo largo de ejes de rasgo significativos, formando un paisaje continuo y rico, y el LTM coloca pequeños “marcadores” selectivos en regiones de ese paisaje. Esta transformación convierte un código pictórico, detallado y distribuido en un código conceptual escaso que resulta más fácil de almacenar, recuperar y combinar con otros recuerdos. Para un público no especialista, la conclusión es que reconocer a un perro en una noche lluviosa no es una simple búsqueda directa, sino el resultado de un proceso por capas y cooperativo en el que una parte del cerebro construye un mapa estructurado de apariencias y otra parte aprende a marcar y leer regiones de ese mapa como ideas distintas y duraderas.
Cita: Cao, R., Zhang, J., Zheng, J. et al. Computational single-neuron mechanisms of visual object coding in the human temporal lobe. Nat Commun 17, 2234 (2026). https://doi.org/10.1038/s41467-026-68954-8
Palabras clave: reconocimiento de objetos, corteza temporal ventral, lóbulo temporal medial, codificación neural, memoria visual