Clear Sky Science · es
Un diamante de ADN formula un modelo descomponible de constelación de letras compuestas para el almacenamiento de datos en ADN
Por qué los datos del futuro podrían vivir en el ADN
Nuestros teléfonos, empresas e instrumentos científicos generan datos mucho más rápido de lo que pueden crecer los discos duros y las cintas magnéticas. El ADN —la misma molécula que porta la información genética en los seres vivos— también puede usarse para almacenar archivos digitales de forma extremadamente compacta y duradera. Este artículo presenta una nueva manera de empaquetar aún más información en hebras sintéticas de ADN sin perder practicidad ni fiabilidad a la hora de leerla, lo que podría abaratar y escalar el almacenamiento en ADN.
De cuatro letras de ADN a mezclas más ricas
El almacenamiento tradicional en ADN usa las cuatro bases naturales —A, T, G y C— para representar bits digitales, de forma análoga a los ceros y unos en un disco. En ese esquema, cada posición en una hebra de ADN puede llevar como máximo dos bits de información, porque está limitada a una de cuatro opciones. Los autores se apoyan en una idea emergente: en lugar de colocar una sola base en cada posición, crean mezclas controladas de bases, llamadas letras compuestas. Por ejemplo, una posición podría estar formada por una mezcla 50:50 de A y T, o por una mezcla 25:25:25:25 de las cuatro bases. Cuando se sintetizan muchas copias de cada hebra, la secuenciación de esas mezclas revela las proporciones de bases y, a su vez, un símbolo digital que puede representar más de dos bits.
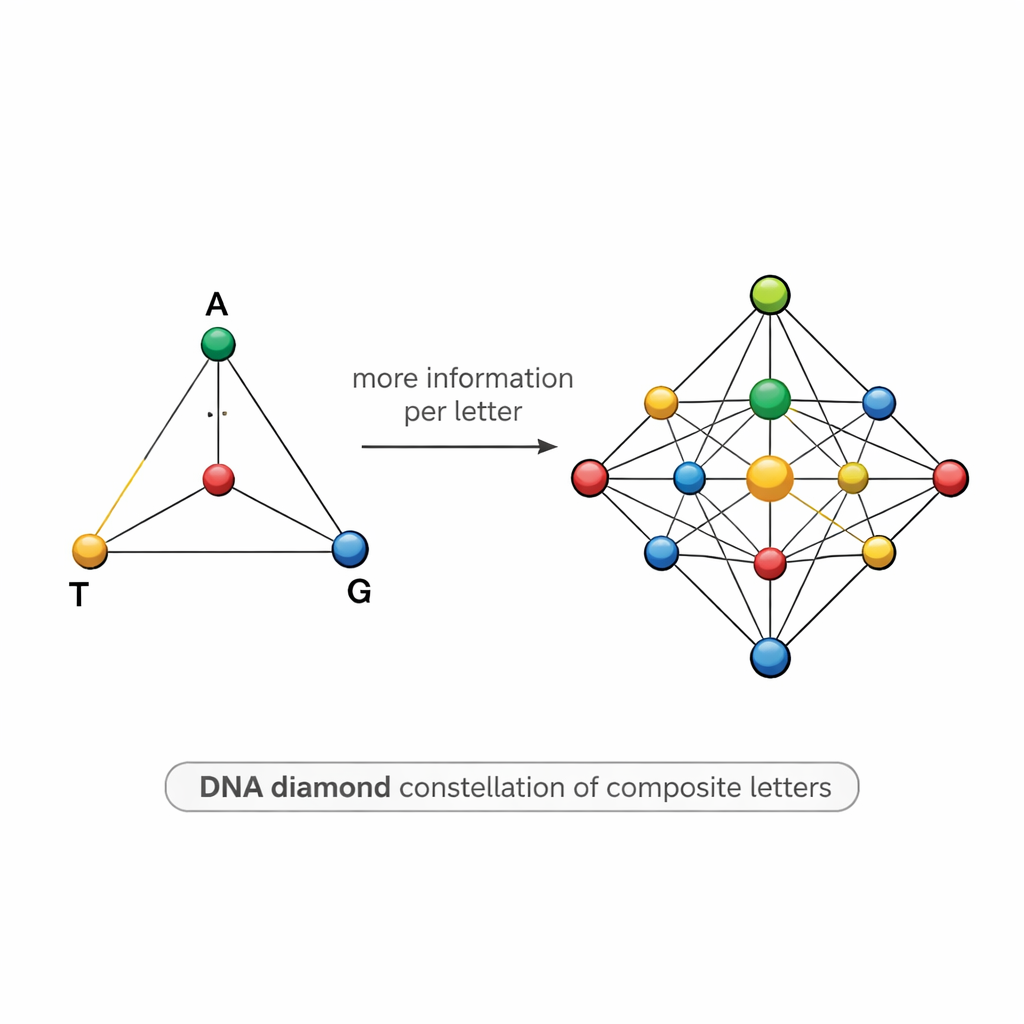
Un mapa en forma de diamante de símbolos de ADN
Diseñar tales mezclas es delicado. Si dos símbolos son demasiado parecidos —por ejemplo, uno es 50% A y 50% T y otro es 55% A y 45% T— el ruido de la secuenciación puede difuminarlos, provocando errores y obligando a secuenciar muchas más copias de las deseadas. Para afrontarlo, el equipo propone un modelo estructurado llamado “diamante de ADN”: un conjunto de 15 letras compuestas dispuestas como puntos en un tetraedro cuyos vértices son A, T, G y C. El conjunto incluye las bases puras en las esquinas, mezclas iguales de dos bases a lo largo de las aristas, mezclas de tres bases en cada cara y una mezcla perfectamente uniforme de las cuatro bases en el centro. Esta constelación cuidadosamente escogida eleva la información teórica por posición a alrededor de 3,9 bits, manteniendo a la vez los símbolos lo bastante distintos para poder discriminarlos en la práctica.
Decodificación más inteligente con entropía e indexado
Leer los datos desde el ADN implica inferir qué letra compuesta se pretendía en cada posición a partir de medidas ruidosas de las frecuencias de bases. Los autores toman prestada una estrategia de las telecomunicaciones llamada particionado de conjuntos. Primero, evalúan cuán “mezclada” parece una posición, usando una cantidad denominada entropía que es baja para bases puras y más alta para mezclas complejas. Esto asigna rápidamente cada posición a uno de cuatro grupos: bases puras, mezclas de dos bases, mezclas de tres bases o la mezcla de cuatro bases. Luego, dentro del grupo escogido, un cálculo de verosimilitud más preciso selecciona la letra más probable. Este enfoque en dos etapas reduce la confusión entre símbolos y acorta el tiempo de cómputo frente a métodos anteriores. Para evitar además que las hebras se confundan entre sí, cada fragmento de ADN lleva secuencias de índice protegidas contra errores en ambos extremos, y las lecturas de longitud incorrecta —a menudo causadas por inserciones o deleciones— se filtran antes de la decodificación.
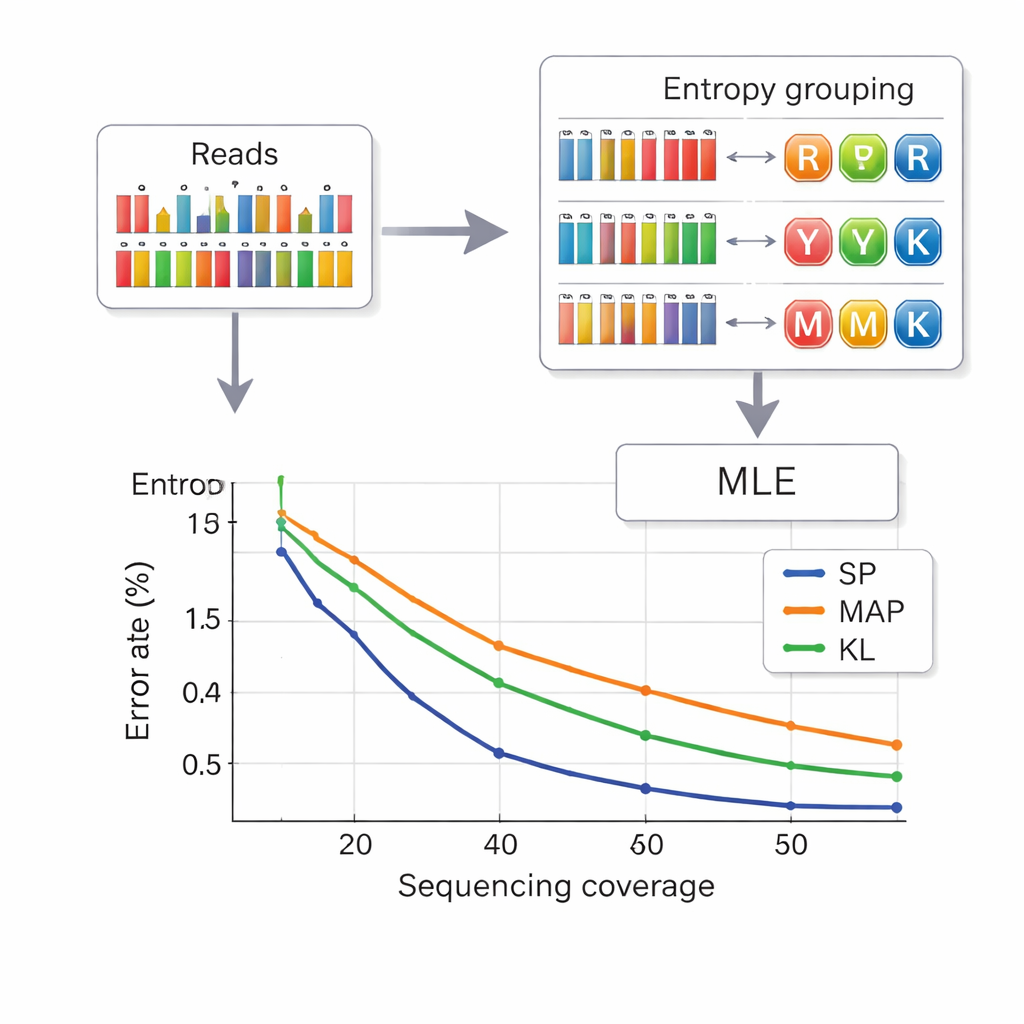
Empaquetando más datos con menos lecturas
Los investigadores probaron su sistema en piscinas de ADN de distinto tamaño, usando plataformas comerciales de síntesis. Con un alfabeto compuesto de ocho letras alcanzaron una densidad de carga útil de 2,5 bits por posición de ADN y pudieron recuperar archivos perfectamente con un promedio de 14 lecturas de secuenciación por hebra —mejor densidad que los esquemas de seis letras anteriores y con menos lecturas necesarias. Con el alfabeto completo de 15 letras del diamante de ADN, lograron 3,125 bits por posición para los datos principales y aun así recuperaron todo sin errores con una cobertura de 33 veces. Simulaciones y experimentos también mostraron que su método basado en entropía rinde casi tan bien como el enfoque de decodificación más preciso, aunque más lento, y claramente mejor que técnicas más antiguas, especialmente a profundidades de secuenciación bajas.
Qué significa esto para la memoria del futuro
Para un lector no especializado, el mensaje clave es que los autores han encontrado una manera de enseñar “trucos nuevos” al ADN sin inventar nueva química: mezclando inteligentemente las cuatro bases existentes y decodificándolas de forma más inteligente, pueden almacenar más bits por molécula controlando los costes. Su alfabeto en forma de diamante, combinado con indexado robusto y corrección de errores, demuestra que el almacenamiento de datos en ADN de alta capacidad es posible con un esfuerzo de secuenciación relativamente modesto. A medida que la síntesis y la secuenciación de ADN continúen abarátandose, estos diseños podrían ayudar a transformar al ADN de una curiosidad de laboratorio en un medio realista para archivar los recuerdos digitales del mundo.
Cita: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Palabras clave: almacenamiento de datos en ADN, letras compuestas, densidad de información, corrección de errores, archivado digital