Clear Sky Science · es
Base de datos de nanopartículas lipídicas para modelado estructura-función y diseño orientado por datos para la entrega de ácidos nucleicos
Por qué importan unas diminutas burbujas de grasa para la medicina del futuro
Las nanopartículas lipídicas son burbujas microscópicas basadas en grasa que transportan de forma segura instrucciones genéticas —como las vacunas de ARNm— hacia nuestras células. Impulsaron el desarrollo de las vacunas contra la COVID-19, pero los investigadores aún no comprenden por completo cómo su composición química detallada regula su eficacia. Este artículo describe un nuevo recurso en línea, la Base de Datos de Nanopartículas Lipídicas (LNPDB), creado para reunir datos dispersos en un único lugar y que permita a los científicos diseñar de forma sistemática medicamentos de entrega genética mejores y más seguros.
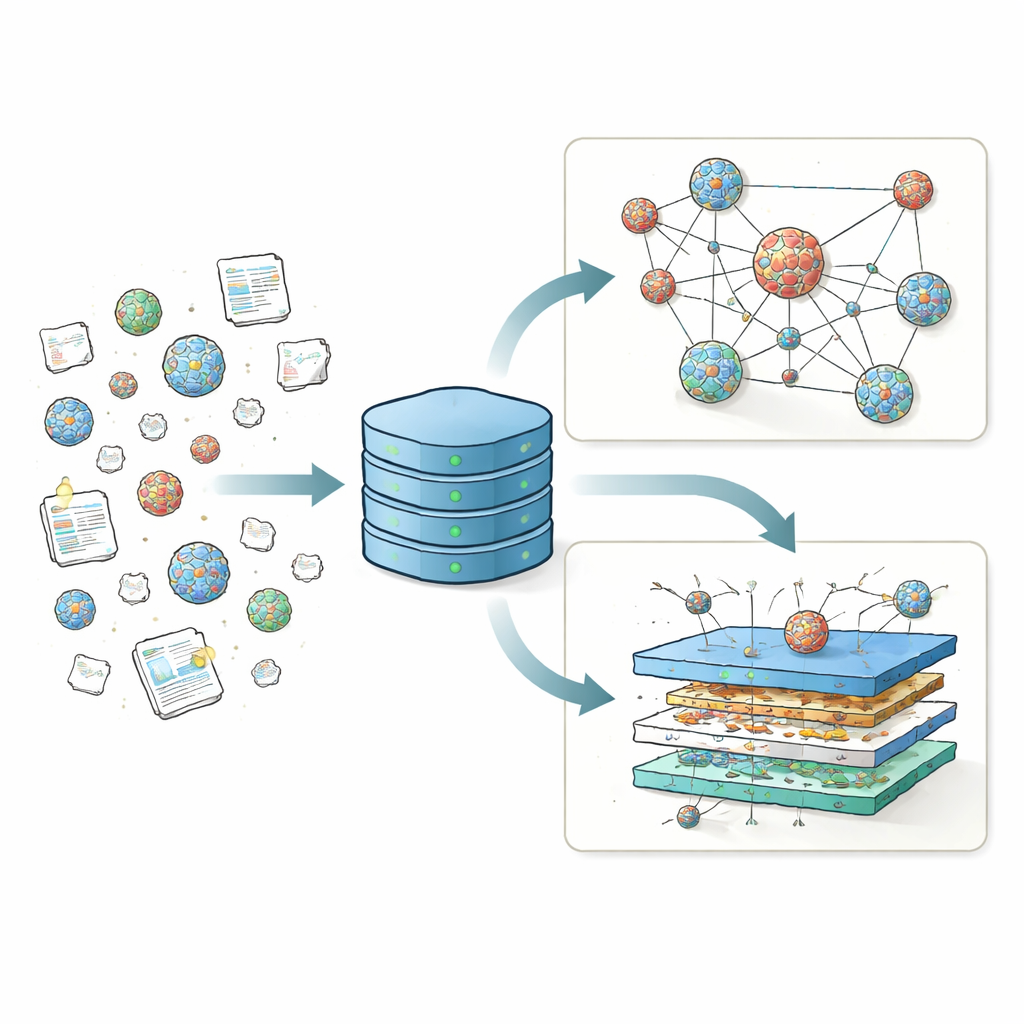
Reunir resultados dispersos en un único repositorio
Durante años, distintos laboratorios han probado miles de recetas de nanopartículas lipídicas (LNP), variando el lípido cargado principal, los lípidos auxiliares, el colesterol y los lípidos de recubrimiento protector para ver qué combinaciones transportan material genético con mayor eficacia. Pero esos resultados se publicaron en muchos formatos a lo largo de decenas de artículos, lo que dificultaba comparar estudios o identificar tendencias generales. A diferencia de la ciencia de las proteínas, que cuenta con un repositorio central —el Protein Data Bank— que impulsó herramientas como AlphaFold, el campo de las LNP no tenía un depósito unificado para sus datos de estructura y rendimiento. LNPDB cubre este hueco al recopilar información detallada de 19.528 formulaciones de LNP extraídas de 42 estudios y de un proveedor comercial, y al estandarizar cómo se codifican los ingredientes, las condiciones experimentales y los resultados de cada partícula.
Qué contiene la nueva base de datos
Cada entrada de LNP en LNPDB se describe según tres ejes principales: composición, experimento y simulación. Los campos de composición registran qué lípidos se usaron, cuántos átomos de nitrógeno contiene el lípido cargado principal y las proporciones exactas de mezcla entre los cuatro componentes básicos: lípido ionizable, lípido auxiliar, colesterol y un lípido con polietilenglicol (PEG). Los campos experimentales capturan qué tipo de carga genética se entregó —con mayor frecuencia ARNm que codifica una proteína reportera—, a dónde se dirigió (por ejemplo, células en placa, hígado, pulmón o músculo), cómo se prepararon las partículas y cómo se midió el éxito. Por último, los campos de simulación aportan archivos listos para usar que describen el comportamiento físico de cada molécula lipídica con suficiente detalle para ejecutar simulaciones computacionales a nivel atómico de membranas lipídicas. En conjunto, estos descriptores estandarizados convierten un mosaico de pruebas individuales en un panorama coherente que la comunidad puede buscar, filtrar y ampliar.
Enseñar a las computadoras a identificar mejores recetas de entrega
Un uso inmediato de LNPDB es mejorar modelos de aprendizaje automático que predicen qué formulaciones entregarán material genético con mayor eficacia. Los autores volvieron a entrenar su modelo de aprendizaje profundo existente, llamado LiON, con el conjunto de datos ampliado de LNPDB, más que duplicando el número de ejemplos que había visto antes. LiON aprende patrones que vinculan las estructuras químicas de los lípidos ionizables, la mezcla de componentes auxiliares y el contexto de ensayo con el rendimiento de cada formulación. Con los datos más abundantes, las predicciones de LiON concordaron mejor con los resultados experimentales en la mayoría de los conjuntos de prueba y superaron a un modelo competidor llamado AGILE en varios conjuntos de datos independientes. Esto sugiere que un conjunto de entrenamiento amplio, diverso y en crecimiento continuo es clave para construir herramientas de diseño de uso general para futuras medicinas basadas en LNP.
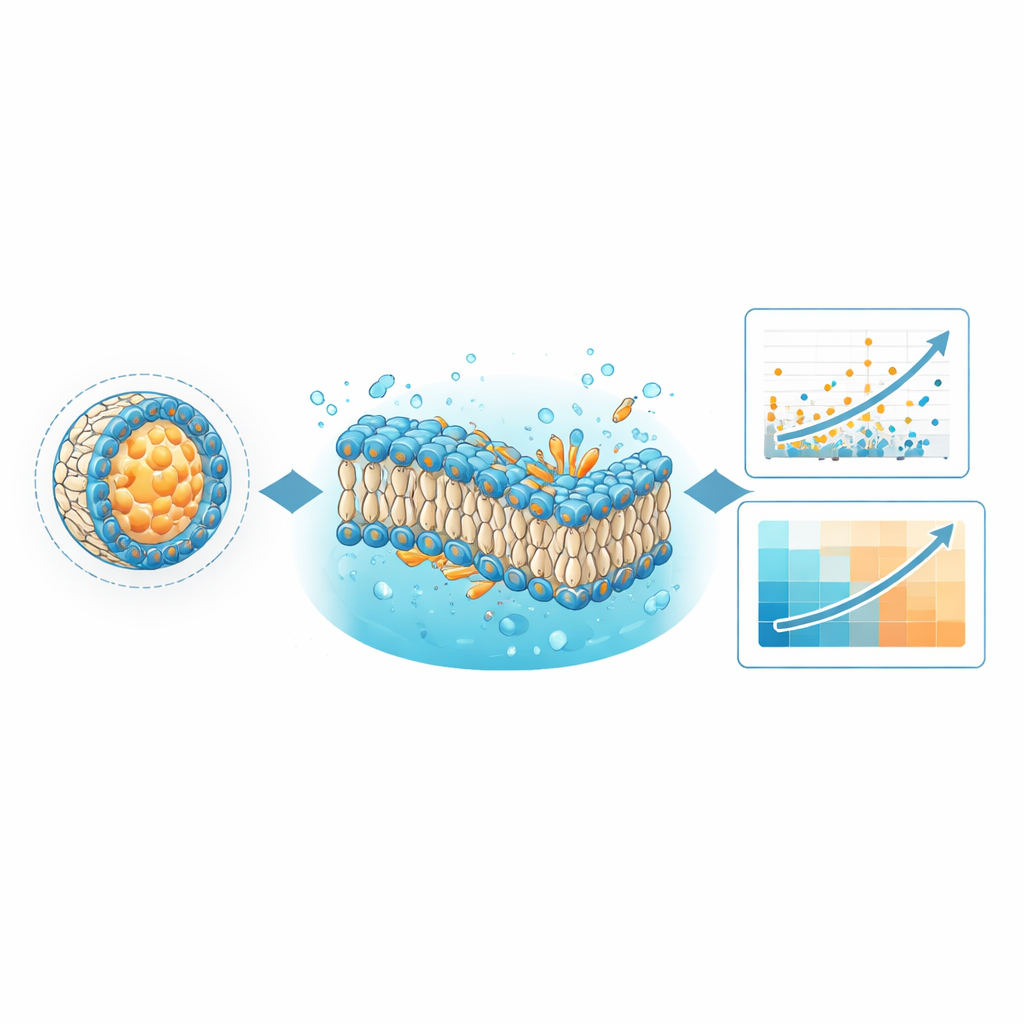
Observar membranas modelo para descubrir reglas ocultas
La base de datos también está diseñada para un tipo de cálculo muy distinto: simulaciones de dinámica molecular basadas en la física. Usando los archivos de simulación que se incluyen en LNPDB, el equipo construyó membranas simplificadas que representan formulaciones seleccionadas de LNP y observó su comportamiento a lo largo de microsegundos de tiempo simulado. Se plantearon dos preguntas: ¿se mantienen intactas las bicapas lipídicas modeladas? y ¿qué forma global adoptan los lípidos clave dentro de la membrana? Las simulaciones revelaron que las formulaciones cuyas membranas permanecían estables tenían más probabilidad de tener éxito experimentalmente. También cuantificaron una característica llamada “parámetro de empaquetamiento crítico”, que refleja si un lípido tiene una forma más cónica o cónica invertida en la membrana. En varias bibliotecas probadas, los lípidos cuya forma favorecía una curvatura negativa —que se piensa ayuda a las partículas a fusionarse con y perturbar membranas endosómicas— mostraron una mayor eficacia de entrega, a veces correlacionando con el rendimiento mejor que el propio modelo de aprendizaje profundo.
Una nueva base para una nanomedicina más inteligente
Para un lector no especialista, el mensaje central es que este trabajo construye un “mapa” compartido y en crecimiento de cómo los ingredientes y la estructura de esas diminutas burbujas de grasa se relacionan con su capacidad para entregar terapias genéticas. Al reunir decenas de miles de experimentos pasados, facilitar potentes modelos predictivos y proporcionar herramientas para simular el comportamiento de las partículas a nivel molecular, LNPDB sienta las bases para un diseño más racional en lugar de pruebas y errores. Con el tiempo, este enfoque orientado por datos podría acelerar la creación de vacunas más eficaces, tratamientos de edición genética y otras terapias basadas en ácidos nucleicos, además de ayudar a los investigadores a entender por qué ciertas recetas de nanopartículas funcionan y otras no.
Cita: Collins, E., Ji, J., Kim, SG. et al. Lipid Nanoparticle Database towards structure-function modeling and data-driven design for nucleic acid delivery. Nat Commun 17, 2464 (2026). https://doi.org/10.1038/s41467-026-68818-1
Palabras clave: nanopartículas lipídicas, entrega de ARNm, nanomedicina, aprendizaje automático, dinámica molecular