Clear Sky Science · es
Evaluación de tecnologías de atlas de ATAC‑seq unicelular mediante modelado secuencia‑a‑función
Leer el manual de instrucciones de la célula
Cada célula de tu cuerpo lee el mismo ADN, sin embargo las neuronas, las células musculares y las inmunitarias se comportan de forma muy distinta. Este artículo aborda un enigma central detrás de esa diversidad: cómo tramos cortos de ADN llamados potenciadores actúan como interruptores para encender y apagar genes en tipos celulares concretos. Los autores muestran que nuevas tecnologías de laboratorio, más baratas, pueden generar los enormes conjuntos de datos necesarios para entrenar modelos modernos de aprendizaje profundo que leen secuencias de ADN y predicen qué potenciadores están activos en qué células, acercándonos a descifrar realmente la “gramática” reguladora del genoma.
Crear mapas del ADN accesible en células individuales
Los potenciadores suelen ubicarse en tramos de ADN que están más abiertos y accesibles, lo que facilita la unión de proteínas reguladoras. Una técnica llamada ATAC‑seq unicelular mide qué partes del genoma están abiertas en miles o cientos de miles de células individuales a la vez, creando un “atlas” del ADN accesible a través de muchos tipos celulares. Estos atlas son un combustible ideal para modelos de aprendizaje profundo que toman la secuencia de ADN en bruto como entrada y aprenden a predecir con qué fuerza actúa cada región pequeña como potenciador en cada tipo celular. Hasta ahora, sin embargo, la mayoría de esos atlas han dependido de instrumentos comerciales costosos, lo que plantea la duda de si métodos de bajo coste y de código abierto pueden aportar datos de entrenamiento de igual valor para estos modelos.
Una alternativa de código abierto a las plataformas comerciales
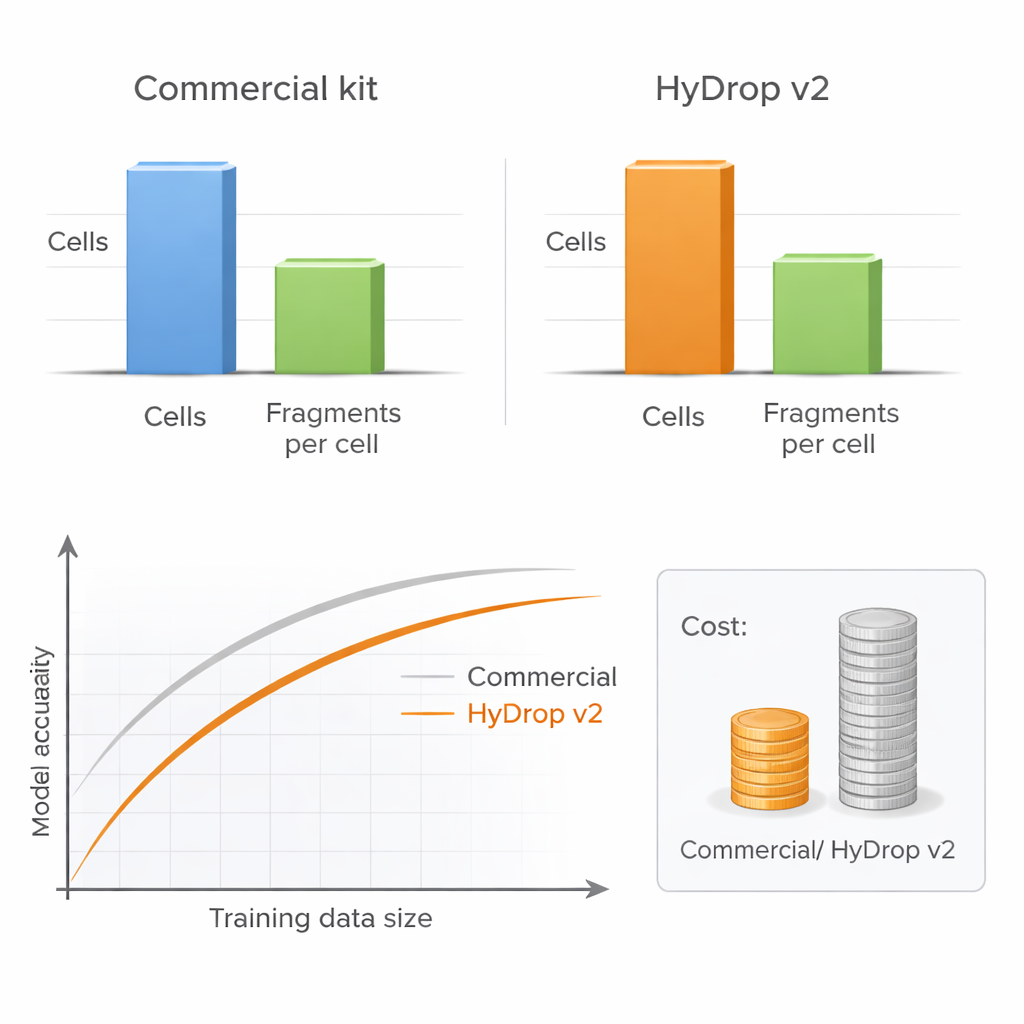
Los autores presentan HyDrop v2, un método droplet mejorado para ATAC‑seq unicelular que utiliza perlas de hidrogel personalizadas para etiquetar con códigos de barras células individuales. Comparan HyDrop v2 con un kit comercial ampliamente usado construyendo atlas grandes a partir de dos sistemas muy diferentes: la corteza motora adulta de ratón y embriones tardíos de mosca de la fruta. HyDrop v2 genera una calidad de datos comparable—recuperando los mismos tipos celulares principales y conjuntos muy similares de regiones de ADN accesible—a la vez que cuesta aproximadamente catorce veces menos por muestra de cerebro de ratón. De forma importante, los datos de experimentos con HyDrop v2 se integran sin problemas con los datos comerciales, lo que permite a los investigadores mezclar plataformas al construir atlas a gran escala.
Entrenar modelos de aprendizaje profundo para leer la lógica de los potenciadores
Para probar si los datos más baratos son suficientes para modelado avanzado, el equipo entrena modelos de aprendizaje profundo secuencia‑a‑función con atlas comerciales o con atlas de HyDrop v2. Estos modelos aprenden directamente de la secuencia de ADN a predecir cuán accesible es cada región en cada tipo celular, y pueden destacar patrones cortos de secuencia que probablemente corresponden a sitios de unión para proteínas reguladoras específicas. En la corteza de ratón, los modelos entrenados con datos de HyDrop v2 igualan a los basados en datos comerciales en precisión global y en su capacidad para recuperar “interruptores” de potenciadores conocidos que previamente se validaron en animales vivos. En el embrión de mosca, ambas plataformas permiten modelos que pueden enfocar regiones de 2.000 pares de bases y localizar los segmentos centrales de ~500 pares de bases que realmente impulsan la actividad potenciadora específica de tejidos, como las regiones que controlan la expresión génica en neuroblastos o músculos.
Más células pueden superar mayor profundidad
Una cuestión práctica clave para cualquier laboratorio es si secuenciar cada célula muy en profundidad o perfilar más células a menor profundidad. Al variar de forma sistemática el número de células y el número de fragmentos de ADN por célula, los autores muestran que el rendimiento del modelo apenas se resiente cuando la profundidad de secuenciación se reduce a un nivel moderado, siempre que se incluyan suficientes células. En contraste, reducir el número de células perjudica claramente la precisión del modelo, especialmente al evaluar el rendimiento a través de muchos tipos celulares a la vez. Dado que HyDrop v2 es mucho más barato por célula, los investigadores pueden añadir con facilidad decenas de miles de células adicionales, recuperando o incluso superando el rendimiento de los modelos basados en plataformas comerciales a una fracción del coste.
Ver las huellas de proteínas en el ADN
El estudio examina también si las distintas plataformas de laboratorio introducen sesgos sutiles en cómo la enzima de ATAC‑seq corta el ADN, lo que podría inducir a error a los modelos que intentan inferir dónde se encuentran las proteínas en el genoma. Usando una herramienta neuronal separada que corrige las preferencias enzimáticas, los autores muestran que HyDrop v2 y los kits comerciales producen patrones de actividad enzimática casi idénticos en células de ratón y de mosca. Tras la corrección, ambos conjuntos de datos revelan “huellas” a escala fina donde las proteínas reguladoras y los nucleosomas parecen proteger el ADN de los cortes, y estas huellas coinciden con los patrones de secuencia destacados por los modelos secuencia‑a‑función. Este acuerdo sugiere que las plataformas de código abierto y comerciales son igualmente aptas para estudios detallados de cómo las proteínas interactúan con el ADN.
Por qué importa esto para descifrar el genoma
Para quienes no son especialistas, la conclusión es que ahora podemos construir mapas muy grandes y asequibles de cómo se usa el ADN en células individuales, y entrenar potentes modelos de aprendizaje profundo con esos mapas sin depender únicamente de hardware propietario costoso. HyDrop v2 ofrece datos que respaldan la predicción de potenciadores, la interpretación de patrones de secuencia y las huellas de unión de proteínas a la par con los métodos comerciales líderes, siempre que se perfilaren suficientes células. Esto abre la puerta a construir atlas a escala de organismos de elementos reguladores en salud y enfermedad, acelerando los esfuerzos por leer las instrucciones reguladoras del genoma y diseñar nuevos interruptores genéticos precisos para la investigación y futuras terapias.
Cita: Dickmänken, H., Wojno, M., Mahieu, L. et al. Evaluating single-cell ATAC-seq atlasing technologies using sequence-to-function modeling. Nat Commun 17, 1951 (2026). https://doi.org/10.1038/s41467-026-68742-4
Palabras clave: ATAC‑seq unicelular, potenciadores, modelos de aprendizaje profundo, regulación génica, genómica de código abierto