Clear Sky Science · es
Avances y desafíos en el almacenamiento de datos en ácidos nucleicos no canónicos
Por qué importa almacenar datos en moléculas
Cada foto, mensaje y película que creamos debe residir en algún lugar, y hoy ese “algún lugar” son en su mayoría enormes almacenes de discos duros que consumen mucha electricidad y se desgastan en unas décadas. Este artículo explora un enfoque muy distinto: usar moléculas genéticas diseñadas como cintas de datos diminutas. Al modificar los bloques constructores familiares del ADN y ARN, los científicos buscan crear un almacenamiento de información más denso, resistente y seguro que cualquier chip de silicio o disco magnético.
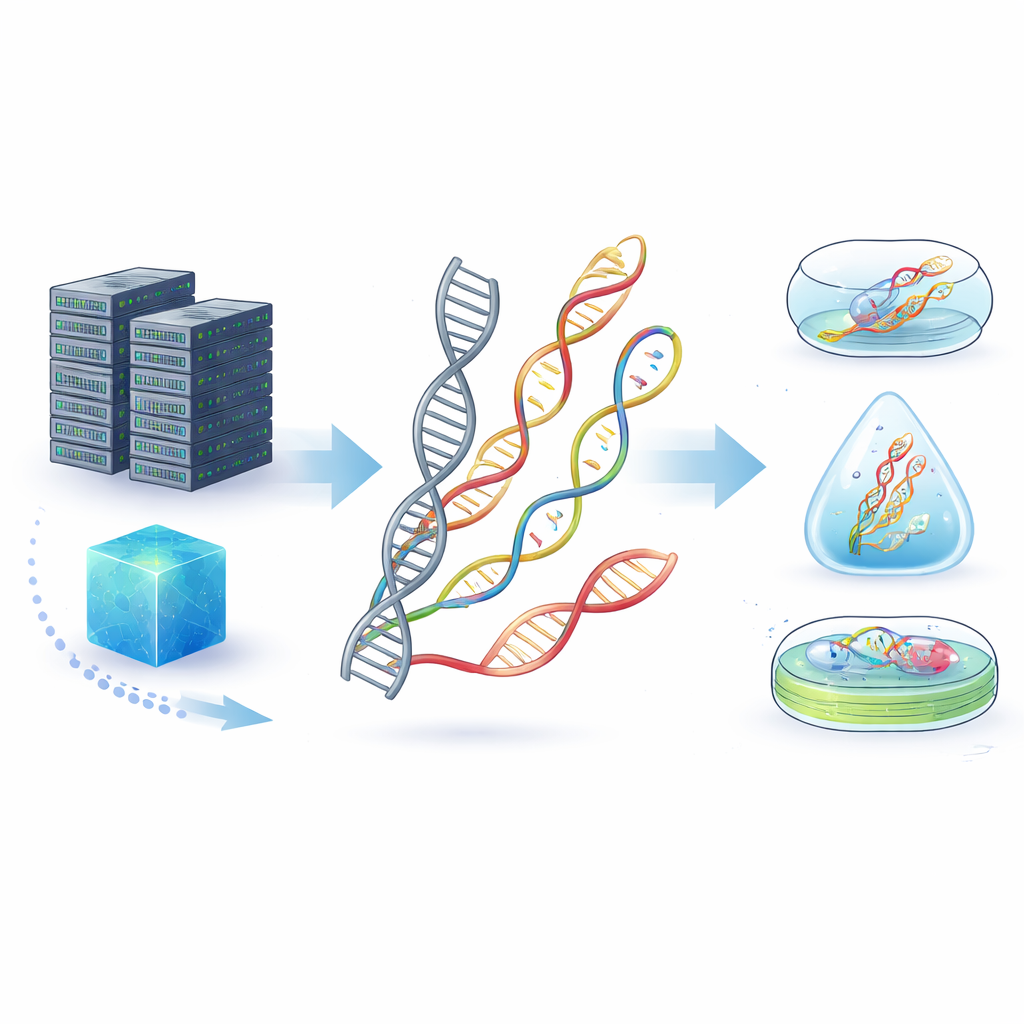
Del ADN frágil a nuevas moléculas resistentes
El ADN natural ya es un medio de almacenamiento impresionante, condensando enormes cantidades de información en un espacio microscópico y sobreviviendo durante decenas de miles de años en fósiles. Pero en condiciones cotidianas—calor, humedad, químicos dispersos o enzimas que degradan el ADN—puede descomponerse rápidamente. Los autores presentan los “ácidos nucleicos no canónicos” (ncNAs): moléculas similares al ADN y ARN cuyas bases, azúcares o esqueletos han sido químicamente alterados, o incluso reflejados, para conferirles nuevas propiedades. Estos cambios pueden hacer que las moléculas sean más difíciles de atacar por enzimas, más resistentes a ácidos o álcalis y mejores para sobrevivir en entornos reales hostiles que el ADN ordinario.
Añadir nuevas letras al alfabeto genético
Una de las ideas más potentes de la revisión es expandir el alfabeto genético más allá de las cuatro letras habituales A, T, G y C. Los químicos han creado pares de bases adicionales que encajan en hélices dobles pero no aparecen en la naturaleza. Con 8, 12 o más letras disponibles, cada posición a lo largo de la cadena puede codificar más bits de información, aumentando la capacidad de almacenamiento mucho más allá de lo que ofrece el ADN estándar. Algunas de estas nuevas bases están diseñadas para unirse mediante interacciones hidrofóbicas en lugar de los habituales enlaces de hidrógeno, demostrando que las reglas de apareamiento de la naturaleza pueden flexibilizarse sin perder la legibilidad de la información.
Reconstruir el esqueleto molecular
Aparte de cambiar las “letras”, los investigadores también rehacen el azúcar y la columna vertebral que sostienen una cadena genética. Sustituir el azúcar habitual por alternativas como threosa o hexitol, o reemplazar los enlaces fosfato cargados por otros neutros o que contienen azufre, puede alterar drásticamente el comportamiento de la cadena. Muchos de estos ncNAs muestran una estabilidad notable en condiciones de calor, acidez o presencia de enzimas donde el ADN natural se desintegraría rápidamente. Algunas versiones en imagen especular, como la L-ADN, son invisibles para las enzimas normales y las defensas inmunitarias, lo que las hace prometedoras para almacenamiento de datos ultra seguro y mensajes ocultos, aunque actualmente son difíciles y costosas de fabricar y leer.
Cómo se escriben, conservan y leen los datos
Transformar archivos digitales en forma molecular sigue un ciclo de cuatro pasos: codificación, escritura, preservación y lectura. Los bits se traducen primero en secuencias o estructuras, que luego se sintetizan como hebras de ncNA mediante métodos químicos o enzimas especialmente diseñadas. Estas hebras pueden almacenarse fuera de células vivas—encapsuladas en vidrio, sílice o polímeros—o dentro de células e incluso plantas modificadas, donde la maquinaria natural de reparación puede ayudar a mantenerlas. La lectura de los datos puede emplear máquinas de secuenciación convencionales, dispositivos avanzados de nanoporo que detectan cada unidad al pasar por un orificio diminuto, o microscopios que reconocen formas en nanostructuras plegadas. Dado que muchos ncNAs no pueden todavía secuenciarse directamente, a menudo se convierten de nuevo a ADN regular antes de leerlos, un paso que la investigación actual intenta agilizar y mejorar.
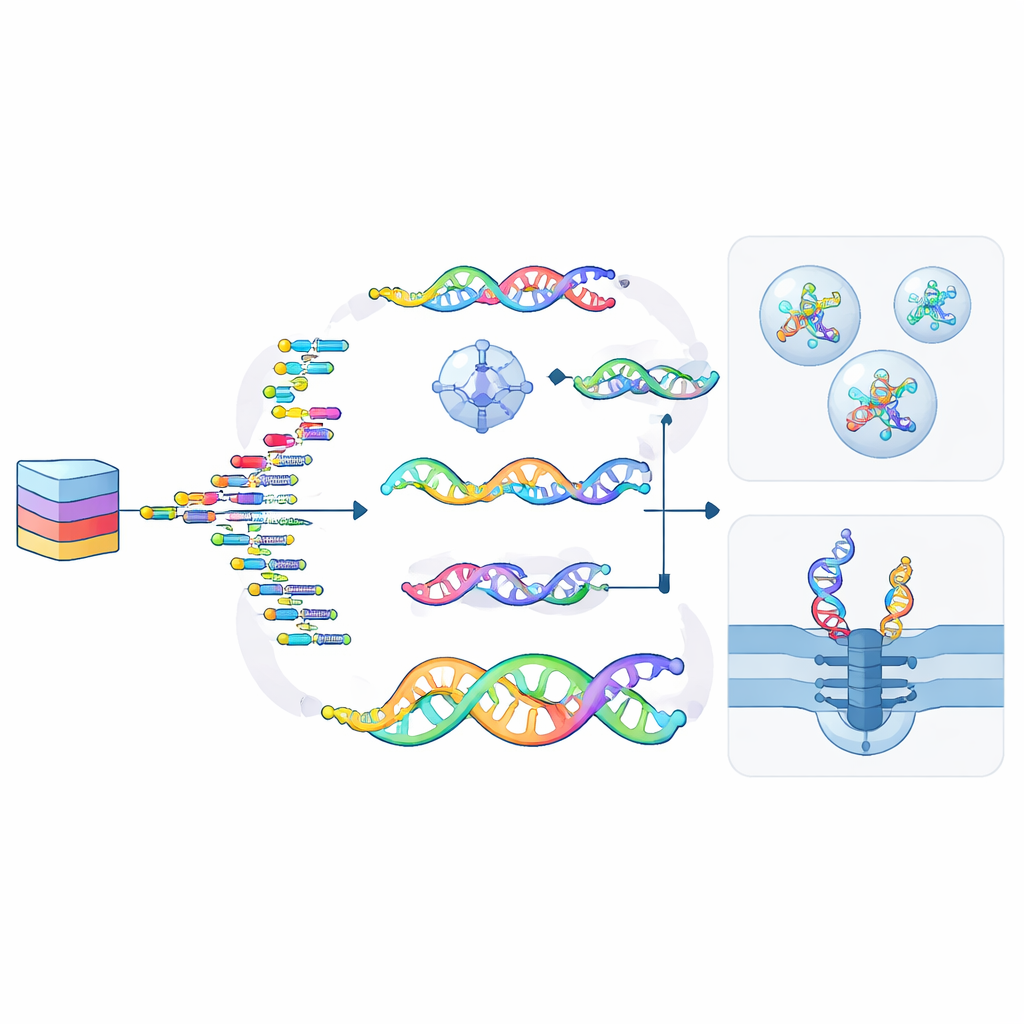
Nuevas posibilidades: computación, seguridad y escritura en paralelo
El artículo subraya cómo los ncNAs hacen más que almacenar datos: también pueden procesarlos. Ya existen circuitos lógicos y redes neuronales basados en ADN, y añadir alfabetos químicamente distintos facilita ejecutar muchas operaciones en paralelo sin interferencias indeseadas. Ciertas modificaciones actúan como tinta invisible, permitiendo ocultar información dentro de hebras o estructuras que solo enzimas o condiciones especiales pueden revelar. Otras, como aductos químicos reversibles o patrones de grupos metilo, se comportan como tipos móviles en una imprenta: pueden imprimir datos sobre hebras existentes en paralelo, borrarlos y reescribirlos sin reconstruir toda la molécula desde cero.
Desafíos por delante y qué significaría el éxito
A pesar de la promesa, los autores enfatizan que el almacenamiento en ácidos nucleicos no canónicos aún está en una etapa temprana. Fabricar hebras largas y sin errores es costoso y técnicamente exigente, y muchas de las químicas más atractivas aún no son compatibles con tecnologías de lectura rápidas y asequibles. También existen preguntas importantes de seguridad y ética sobre introducir moléculas parcialmente no naturales y altamente estables en sistemas vivos. Aun así, la revisión describe una hoja de ruta en la que una síntesis más rápida, encapsulaciones más inteligentes y lectores de nanoporo potenciados por inteligencia artificial podrían hacer práctico el almacenamiento basado en ncNA en las próximas décadas. Si eso ocurre, quizá un día respalderemos nuestra civilización digital no en discos giratorios, sino en hebras diminutas y robustas de moléculas diseñadas.
Cita: Wang, Y., Pei, Y., Tang, L. et al. Advances and challenges in non-canonical nucleic acids data storage. Nat Commun 17, 2354 (2026). https://doi.org/10.1038/s41467-026-68708-6
Palabras clave: Almacenamiento de datos en ADN, ácidos nucleicos no canónicos, memoria molecular, pares de bases no naturales, secuenciación por nanoporo