Clear Sky Science · es
Mejorar la predicción con puntuaciones poligénicas para grupos infrarepresentados mediante aprendizaje por transferencia
Por qué tu puntuación de riesgo genética puede no funcionar para ti
Las «puntuaciones de riesgo» genéticas se utilizan cada vez más para estimar la probabilidad de que una persona desarrolle afecciones comunes como diabetes, enfermedad cardíaca o hipertensión. Pero la mayoría de estas puntuaciones se construyeron con datos de ADN de personas de ascendencia europea. Como resultado, a menudo predicen mal en personas de otros orígenes, lo que plantea dudas sobre su equidad y utilidad en la medicina real. Este estudio plantea una pregunta simple: ¿podemos reutilizar lo aprendido a partir de grandes conjuntos de datos europeos para construir puntuaciones genéticas mejores y más justas para grupos infrarepresentados—sin compartir los datos sin procesar de nadie?
De millones de marcadores de ADN a una sola puntuación de riesgo
Una puntuación poligénica es como una nota que suma los pequeños efectos de muchos marcadores genéticos repartidos por el genoma. Cada marcador recibe un peso que refleja la fuerza de su asociación con un rasgo, basado en grandes estudios genéticos. Cuando estos estudios involucran mayoritariamente a europeos, la puntuación resultante tiende a funcionar mejor en europeos. Las diferencias en las historias genéticas—qué tan frecuentes son ciertas variantes y cómo se heredan juntas—significan que los mismos pesos con frecuencia fallan en poblaciones afroamericanas, hispanas y otras. Reunir conjuntos de datos igualmente grandes para cada grupo es caro y lento, así que los autores recurrieron a una estrategia de aprendizaje automático llamada aprendizaje por transferencia: en lugar de empezar de cero en cada población, refinan un modelo existente entrenado en otro sitio.
Cómo aprovechar conocimientos sin compartir datos sin procesar
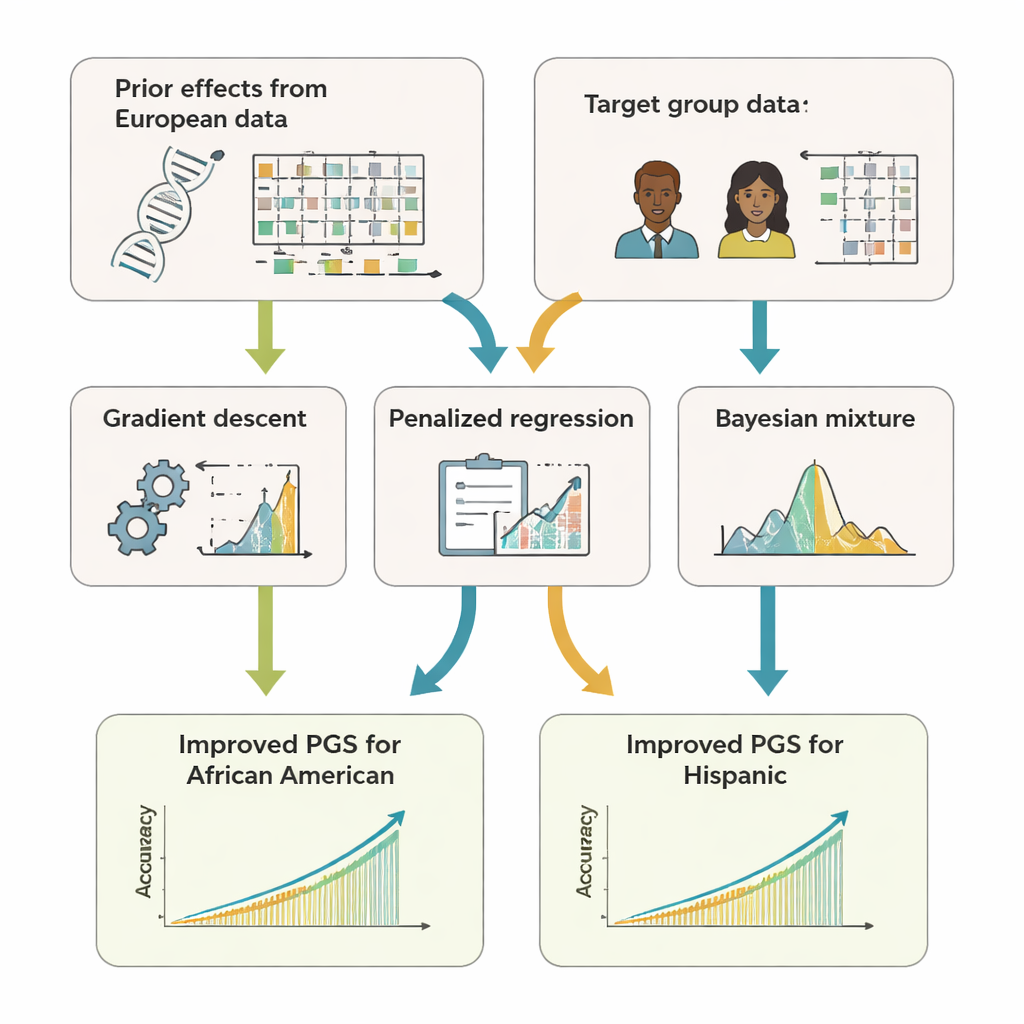
El equipo desarrolló GPTL, un paquete de software R de código abierto que implementa tres enfoques de aprendizaje por transferencia para puntuaciones genéticas. Los tres parten de estimaciones previas de los efectos del ADN obtenidas en un gran conjunto de datos de ascendencia europea y luego ajustan suavemente esas estimaciones usando datos del grupo objetivo, como afroamericanos u hispanos. Un método modifica los pesos europeos paso a paso mediante descenso de gradiente y se detiene temprano, antes de sobrescribirlos por completo. Un segundo método, la regresión penalizada, atrae activamente las nuevas estimaciones hacia los valores originales a menos que los datos del grupo objetivo aporten evidencia sólida en contra. El tercero, un modelo bayesiano de mezcla, permite que cada marcador de ADN elija entre varias fuentes de información—como múltiples grupos de ascendencia o incluso una opción de «sin efecto»—y las combina según lo bien que expliquen los datos del grupo objetivo.
Poniendo a prueba los métodos
Para evaluar el rendimiento de estos enfoques, los autores usaron tanto simulaciones por ordenador como datos reales de cientos de miles de voluntarios del UK Biobank y del programa de investigación All of Us de EE. UU. Se centraron en participantes afroamericanos e hispanos como grupos objetivo y usaron datos de ascendencia europea como fuente principal de información previa. En 11 rasgos—incluyendo estatura, índice de masa corporal, lípidos sanguíneos, presión arterial y marcadores renales—las puntuaciones con aprendizaje por transferencia predijeron de forma consistente mejor que las puntuaciones construidas solo dentro del grupo objetivo o las reutilizadas directamente de europeos. A menudo, su exactitud igualó o incluso superó ligeramente a la de métodos «multi-ascendencia» más complejos que requieren combinar datos sin procesar de varias poblaciones. De forma crucial, los métodos de GPTL solo necesitan estadísticas sumarias—números agregados sobre los efectos genéticos—por lo que las instituciones pueden colaborar sin exponer registros genéticos a nivel individual.
Cuando más ADN no siempre es mejor
Los investigadores también examinaron cómo elegir mejor qué marcadores genéticos incluir. Contrariamente a la creencia común de que usar todos los marcadores disponibles siempre ayuda, encontraron que para los grupos afroamericanos y, especialmente, hispanos, incluir millones de señales muy débiles podría perjudicar el rendimiento, en particular al usar representaciones muy simplificadas de las correlaciones genéticas. Centrar la atención en marcadores mejor respaldados y usar información más rica sobre cómo se heredan las variantes a menudo produjo puntuaciones más precisas. El estudio también mostró que añadir información previa de múltiples grupos de ascendencia y modelar cuidadosamente las diferencias entre poblaciones mejoró aún más las predicciones.
Qué implica esto para una predicción de riesgo genética más justa
Para las poblaciones no europeas, las puntuaciones genéticas disponibles hoy en día pueden rendir mucho peor, lo que podría ampliar las desigualdades en salud. Este trabajo demuestra que el aprendizaje por transferencia—refinar con criterio las puntuaciones basadas en europeos usando conjuntos de datos modestos de grupos infrarepresentados—puede cerrar gran parte de esa brecha. En la práctica, esto significa que los sistemas de salud y los investigadores pueden construir herramientas genéticas más precisas y equitativas sin reunir datos sin procesar entre instituciones o ascendencias, lo que atenúa las preocupaciones de privacidad. Aunque ningún método será el mejor para todos los rasgos y poblaciones, el conjunto de herramientas GPTL muestra que una predicción genética más justa es técnicamente alcanzable si consideramos los modelos previos no como productos fijos, sino como puntos de partida que pueden adaptarse a todos.
Cita: Wu, H., Pérez-Rodríguez, P., Boehnke, M. et al. Improving polygenic score prediction for underrepresented groups through transfer learning. Nat Commun 17, 1973 (2026). https://doi.org/10.1038/s41467-026-68696-7
Palabras clave: puntuaciones de riesgo poligénico, aprendizaje por transferencia, predicción genética, desigualdades en salud, genética de poblaciones