Clear Sky Science · es
Aceleradores neuronales nanofotónicos diseñados por inversión para computación óptica ultracompacta
Por qué importa reducir el tamaño de los ordenadores hechos de luz
La inteligencia artificial moderna se ejecuta en vastos sistemas electrónicos que consumen enormes cantidades de energía y generan calor. Este estudio explora una vía muy distinta: usar patrones diminutos de luz en un chip, en lugar de corrientes de electrones, para realizar partes del cálculo de redes neuronales. Los autores demuestran que al “esculpir” la luz a escala nanométrica pueden construir aceleradores ópticos ultracompactos que reconocen dígitos manuscritos e imágenes médicas empleando mucho menos espacio y, en principio, mucha menos energía que la electrónica actual.
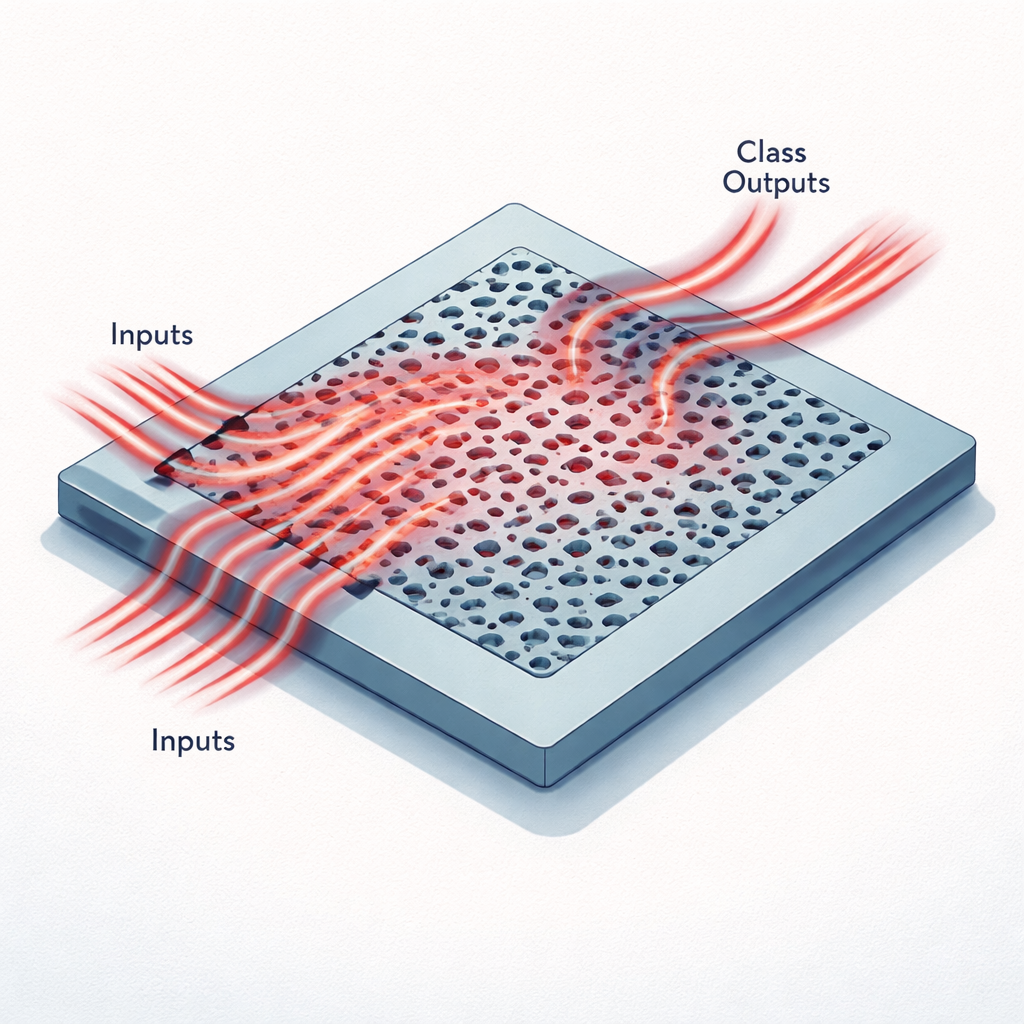
Chips diminutos que piensan con luz
En lugar de cables y transistores, estos aceleradores usan una lámina plana de silicio con patrones de agujeros y canales menores que la longitud de onda de la luz infrarroja. Los datos de una imagen se comprimen primero en un pequeño conjunto de números, que luego se codifican como la intensidad de la luz que entra por varias guías de onda estrechas a una longitud de onda de telecomunicaciones. Al propagarse hacia la región patrónizada, esa luz se dispersa, interfiere consigo misma y se redirige hacia un puñado de guías de salida. Cada salida corresponde a una clase posible, como uno de los diez dígitos del conjunto MNIST o una de las seis categorías de un conjunto de imágenes médicas llamado MedNIST. El patrón de potencia óptica en las salidas desempeña el mismo papel que la capa final de una red neuronal digital.
Dejar que los algoritmos dibujen el plano óptico
Diseñar una estructura así a mano sería casi imposible, porque cada diminuto “vóxel” de material puede cambiar cómo se propaga la luz. Los investigadores usan en su lugar un enfoque de diseño inverso: parten de un patrón aleatorio de silicio y vidrio, simulan cómo se propaga la luz en tres dimensiones y luego ajustan el patrón para reducir una función de pérdida que mide los errores de clasificación. Aprovechan la linealidad de las ecuaciones de Maxwell—las leyes que gobiernan la luz—para hacer este entrenamiento eficiente. En vez de simular cada imagen de entrenamiento por separado, simulan cada canal de entrada una sola vez y luego reconstruyen los campos para todas las imágenes como combinaciones lineales de esos campos precomputados. Una técnica matemática llamada método adjunto proporciona entonces gradientes exactos que indican al algoritmo cómo ajustar cada vóxel para mejorar el rendimiento.

Clasificadores de imagen compactos en un grano de arena
Con esta estrategia, el equipo diseñó dos aceleradores neuronales nanofotónicos en una plataforma estándar de silicio sobre aislante. Uno, de apenas 20 por 20 micrómetros, clasifica dígitos manuscritos del conjunto MNIST; el otro, de 30 por 20 micrómetros, clasifica imágenes médicas de MedNIST. En simulaciones, estos diminutos dispositivos alcanzaron precisiones del 97,8% y 99,1%, respectivamente. Versiones fabricadas de los mismos diseños, probadas con láseres y detectores reales, obtuvieron un 89% de precisión para MNIST y un 90% para MedNIST—cifras notables dado el tamaño minúsculo de los chips. Las estructuras ópticas integran aproximadamente entre 160.000 y 240.000 parámetros entrenables en áreas menores que un grano de polvo, lo que equivale a unos 400 millones de parámetros por milímetro cuadrado.
Diseñados para velocidad, eficiencia y escalabilidad
Dado que los dispositivos son pasivos—no tienen partes móviles ni elementos reprogramables durante la inferencia—no requieren ajuste continuo una vez fabricados. Los “pesos” de la red neuronal están integrados físicamente en la geometría de la nanostructura, por lo que el cálculo ocurre a la velocidad de la luz con procesamiento esencialmente en memoria: la luz entra con los datos codificados y sale ya mezclada en puntuaciones de clases. El método de entrenamiento también está pensado para escalar. Cada paso de optimización requiere solo un número fijo de simulaciones de física completa determinado por el número de entradas y salidas, no por el tamaño del conjunto de datos, y estas simulaciones pueden distribuirse entre múltiples unidades de procesamiento gráfico. Los autores además esbozan cómo múltiples núcleos ópticos de este tipo podrían apilarse con fotodetectores entre ellos, similar a las capas en una red neuronal profunda, y cómo la multiplexación en longitud de onda o en tiempo podría aumentar el rendimiento.
Lo que esto significa para el hardware de IA del futuro
En términos sencillos, este trabajo demuestra que es posible “hacer crecer” piezas a medida de vidrio y silicio que se comportan como capas especializadas de redes neuronales, todo dentro de un área lo bastante pequeña como para albergar cientos o miles de ellas en un único chip. Si bien los ordenadores completamente ópticos aún están en el horizonte, estos aceleradores nanofotónicos diseñados por inversión podrían descargar algunas de las partes de mayor consumo energético de las cargas de trabajo de IA desde los procesadores electrónicos. Si se combinan con moduladores rápidos, detectores y un diseño de sistema inteligente, apuntan hacia hardware compacto y de bajo consumo donde la luz, más que la electricidad por sí sola, realiza gran parte del trabajo pesado en el aprendizaje automático.
Cita: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Palabras clave: redes neuronales fotónicas, nanofotónica, computación óptica, aceleradores de hardware, diseño inverso