Clear Sky Science · es
Un basecaller con doble contexto para la secuenciación directa de ARN por nanoporo
Por qué importa descifrar las letras del ARN
Cada célula de tu cuerpo está constantemente leyendo y reescribiendo mensajes escritos en ARN, la copia funcional de nuestros genes. Las nuevas máquinas “nanoporo” pueden leer moléculas de ARN individuales de forma directa, con la promesa de revelar cómo se activan los genes, cómo se empalman los ARN y cómo las marcas químicas en el ARN influyen en la salud y la enfermedad. Pero hay una trampa: estos dispositivos miden en realidad pequeñas corrientes eléctricas, que luego deben traducirse —“basecalling”— a las familiares letras A, C, G y U. Si esa traducción falla, la historia biológica que inferimos puede quedar muy distorsionada. Este artículo presenta Coral, un nuevo sistema de inteligencia artificial que hace esa traducción mucho más precisa.
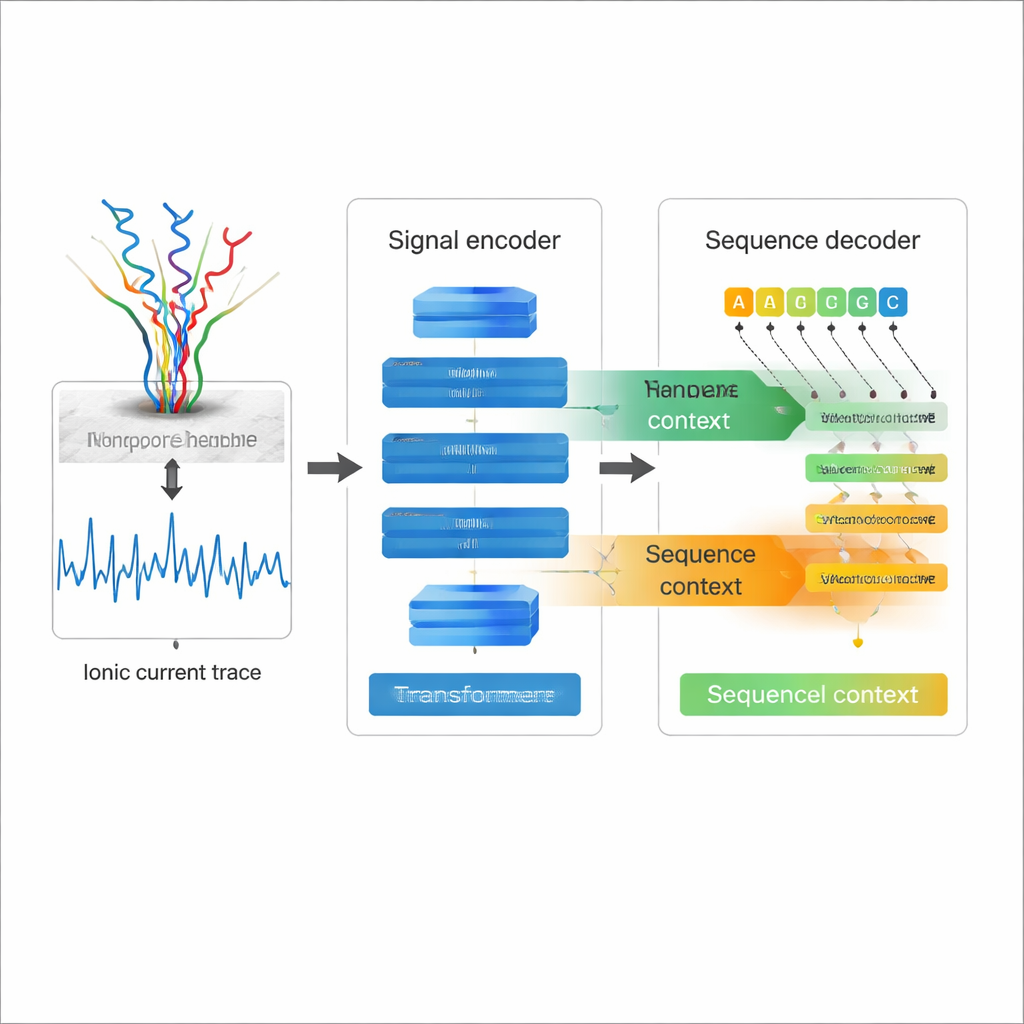
Leyendo electricidad en lugar de letras
La secuenciación directa de ARN por nanoporo funciona haciendo pasar una hebra única de ARN por un agujero molecular —un nanoporo— mientras se mide cómo cambia la corriente eléctrica a medida que cada nucleótido lo atraviesa. Esas trazas de corriente ondulantes contienen la información sobre la secuencia de ARN y sus modificaciones químicas. La secuenciación tradicional de ARN convierte el ARN en ADN y lo amplifica, pasos que pueden introducir sesgos y borrar muchas marcas químicas naturales. La secuenciación directa de ARN evita esos problemas, pero el precio ha sido una tasa de error relativamente alta a la hora de convertir las trazas de corriente en secuencias, especialmente para rasgos difíciles como bases repetidas y estructuras complejas de ARN. Un mejor basecalling es esencial si los científicos quieren confiar en los detalles finos de estas lecturas largas de ARN.
Un traductor más inteligente que usa dos tipos de contexto
La mayoría de los basecallers de nanoporo existentes tratan la señal eléctrica como la fuente principal de información y decodifican cada posición casi de forma independiente, lo que limita cuánto pueden aprovechar la estructura de la propia secuencia de ARN. Coral adopta un enfoque diferente. Emplea una arquitectura codificador‑decodificador basada en Transformer, análoga en espíritu a los modelos de lenguaje modernos. Primero, una red codificadora formada por convoluciones y capas de auto‑atención digiere la señal eléctrica cruda en una descripción compacta de cómo cambia la señal a lo largo del tiempo. Luego, un decodificador predice cada nueva base de ARN paso a paso, mirando simultáneamente hacia atrás las bases ya escritas y de lado hacia la señal codificada. Dos tipos de atención —dentro de la secuencia de ARN en crecimiento y entre la secuencia y la señal— permiten que Coral valore tanto el contexto eléctrico como el de la secuencia al decidir qué letra viene a continuación.
Secuencias más nítidas y menos moléculas perdidas
Los autores evaluaron Coral frente a varios basecallers líderes, incluidas las herramientas comerciales de Oxford Nanopore, sobre ARN humano y de otros organismos y con varias químicas de nanoporo. En seis especies y con kits de secuenciación de ARN más antiguos, Coral alcanzó una precisión típica de lectura mediana alrededor del 97%, claramente superior a la de los métodos competidores. Con el kit de ARN más reciente, su precisión superó el 99%. Coral produjo menos desajustes, inserciones y deleciones, y generó lecturas más largas y mejor alineadas con menos secuencias que no pudieron mapearse en absoluto. Fue especialmente bueno manejando pequeñas repeticiones de bases —muy comunes en datos reales— que son una fuente frecuente de errores para otras herramientas. Al capturar de forma más fiable tramos más largos de secuencia correcta, Coral también se destacó en la predicción de patrones cortos de secuencia (k‑mers) y se mantuvo robusto incluso cuando pasos de decodificación anteriores contenían pequeños fallos.
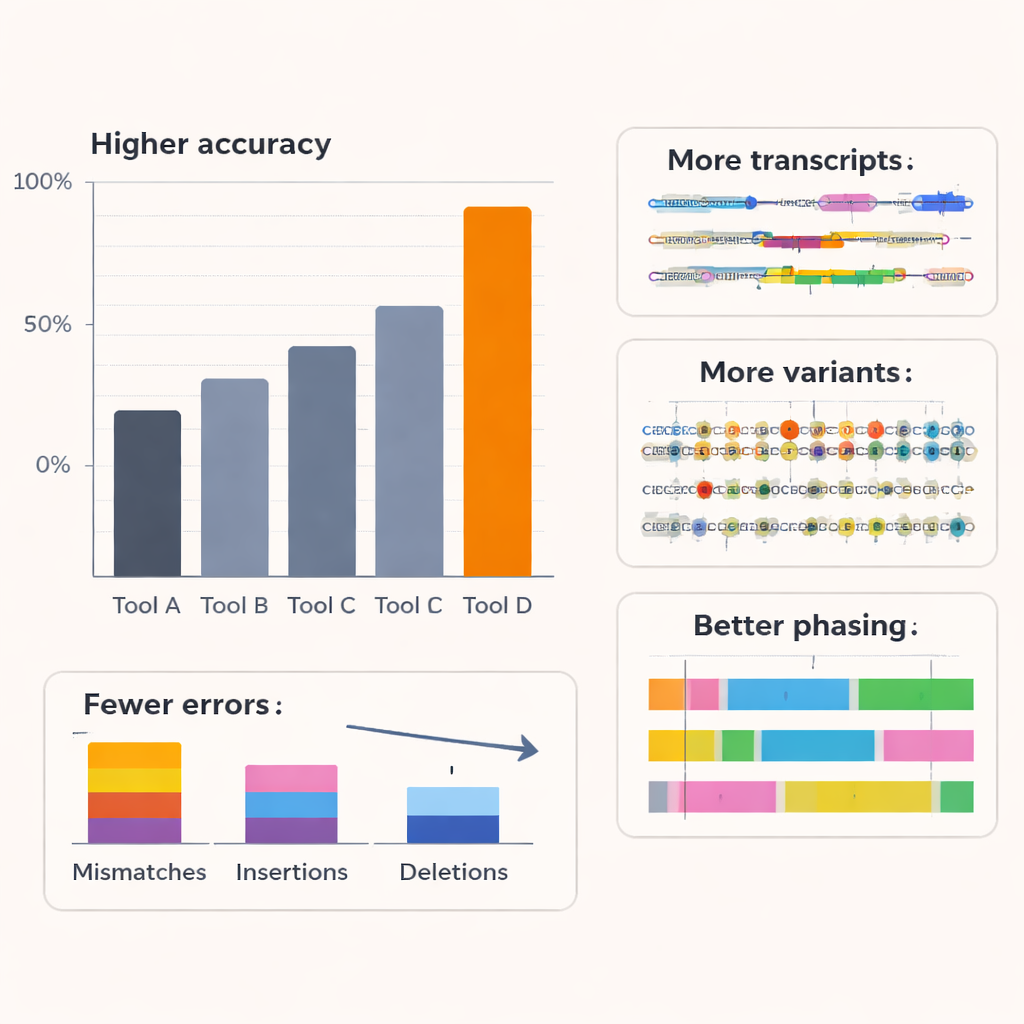
Viendo más detalles ocultos del transcriptoma
Mejorar el basecalling solo tiene valor si conduce a una biología mejor. Para probarlo, el equipo examinó cómo la salida de Coral afectaba a los análisis posteriores en líneas celulares humanas. Usando una herramienta especializada para reconstruir isoformas completas de ARN —las distintas versiones empalmadas de cada gen— encontraron que las lecturas de Coral mostraban más estructuras de transcritos ya conocidas y muchas isoformas adicionales de baja abundancia que otros basecallers no detectaron. Muchos de los transcritos específicos de Coral estaban respaldados por datos independientes de lecturas cortas, lo que indica que son reales y no artefactos. Coral también detectó más transcritos de referencia artificiales con concentraciones conocidas en un experimento de spike‑in y estimó su abundancia con mayor precisión. Más allá del descubrimiento de transcritos, Coral mejoró la detección de eventos de fusión de genes en una línea celular de cáncer de mama y aumentó el número y la fiabilidad de genes que muestran expresión alélica específica, donde una copia parental de un gen está más activa que la otra.
Variantes genéticas más claras y linajes familiares
Puesto que las lecturas largas de ARN pueden abarcar variantes genéticas distantes, son herramientas potentes para determinar qué variantes viajan juntas en la misma copia cromosómica —un proceso llamado fasing de haplotipos. Usando una muestra humana bien estudiada con un mapa de variantes de oro, los autores mostraron que las lecturas de mayor calidad de Coral condujeron a una detección más precisa de cambios de nucleótido único y a muchos menos errores de fasing: los errores de conmutación y las tasas globales de desajuste dentro de los bloques fasados se redujeron hasta en aproximadamente tres cuartas partes respecto a otros métodos, mientras que muchas más variantes pudieron fasarse en absoluto. Estudios de simulación variando la precisión de lectura subyacente confirmaron que una vez que el basecalling se acerca a alrededor del 95% de precisión, el rendimiento en descubrimiento de transcritos, expresión alélica específica y fasing mejora bruscamente y luego se estabiliza. Coral se sitúa en esta zona de alto beneficio, lo que sugiere que captura la mayor parte de la información biológica relevante presente en las señales ruidosas de nanoporo.
Qué significa esto para la investigación futura del ARN
Para los no especialistas, el mensaje clave es que Coral actúa como un traductor mucho más fiable entre el lenguaje eléctrico de los secuenciadores por nanoporo y el lenguaje genético del ARN. Al utilizar mejor el contexto tanto en la señal como en la secuencia en crecimiento, produce lecturas más nítidas que descubren más variantes de transcritos, detectan genes de fusión raros y siguen con mayor seguridad qué variantes provienen de cada progenitor. El software es de código abierto, de modo que los investigadores pueden adaptarlo a nuevos organismos, químicas o incluso para estudiar las marcas químicas en el ARN en sí. A medida que la tecnología de nanoporo continúa mejorando, herramientas como Coral ayudarán a convertir trazas de corriente bruta en mapas fiables y detallados del mundo del ARN dentro de las células.
Cita: Xie, S., Ding, L., Yu, Y. et al. A dual context-aware basecaller for nanopore direct RNA sequencing. Nat Commun 17, 1851 (2026). https://doi.org/10.1038/s41467-026-68566-2
Palabras clave: secuenciación de ARN por nanoporo, decodificación de bases, modelo Transformer, isoformas de transcritos, fasing de haplotipos