Clear Sky Science · es
Tres preguntas abiertas sobre la portabilidad de las puntuaciones poligénicas
Por qué predecir la salud a partir del ADN es más difícil de lo que parece
Los médicos e investigadores esperan cada vez más usar «puntuaciones poligénicas» basadas en el ADN para predecir el riesgo de condiciones comunes, como la diabetes, las enfermedades cardíacas o el asma. Pero estas puntuaciones suelen funcionar bien solamente en personas que se parecen a los voluntarios originales del estudio, normalmente de ascendencia europea. Este artículo plantea por qué estas predicciones no «viajan» de forma fiable a personas con antecedentes genéticos o circunstancias vitales distintos, y qué implica eso para usar las puntuaciones de riesgo genético de forma justa en la medicina.
Lo que prometen las puntuaciones poligénicas —y dónde se quedan cortas
Las puntuaciones poligénicas combinan los efectos diminutos de muchas variantes genéticas a lo largo del genoma en un único número destinado a predecir un rasgo, como la altura o la presión arterial. Se construyen a partir de enormes estudios de asociación del genoma completo (GWAS) que vinculan marcadores de ADN con rasgos en cientos de miles de voluntarios. Sin embargo, cuando esas puntuaciones se aplican a nuevos grupos de personas, su precisión varía de forma drástica. Habitualmente, la predicción empeora cuanto más difiere el nuevo grupo, genética o socialmente, de los participantes originales del GWAS. Esto se conoce como el problema de la portabilidad: una puntuación que funciona en un contexto puede engañar en otro, potencialmente profundizando las desigualdades en salud si se usa sin crítica.
Mirar más allá de la ascendencia: distancia en el mapa genético
Para explorar este problema, los autores utilizaron datos del UK Biobank, que incluyen información genética y de salud de más de 400.000 personas. Construyeron puntuaciones poligénicas para 15 rasgos altamente hereditarios, como la altura, el peso, recuentos de células sanguíneas y niveles de colesterol, basadas en un gran grupo formado principalmente por británicos blancos. Luego evaluaron qué tan bien esas puntuaciones predijeron los rasgos en 69.500 participantes adicionales, que abarcaban una amplia gama de antecedentes genéticos. En lugar de asignar a las personas a grandes categorías de ascendencia, el equipo ubicó a cada individuo a lo largo de una escala continua de «distancia genética»: qué tan lejos estaba el perfil de ADN de cada persona del promedio de los voluntarios del GWAS cuando se proyectaba en un mapa genético basado en componentes principales.
El poder predictivo se debilita —pero no de forma simple ni justa
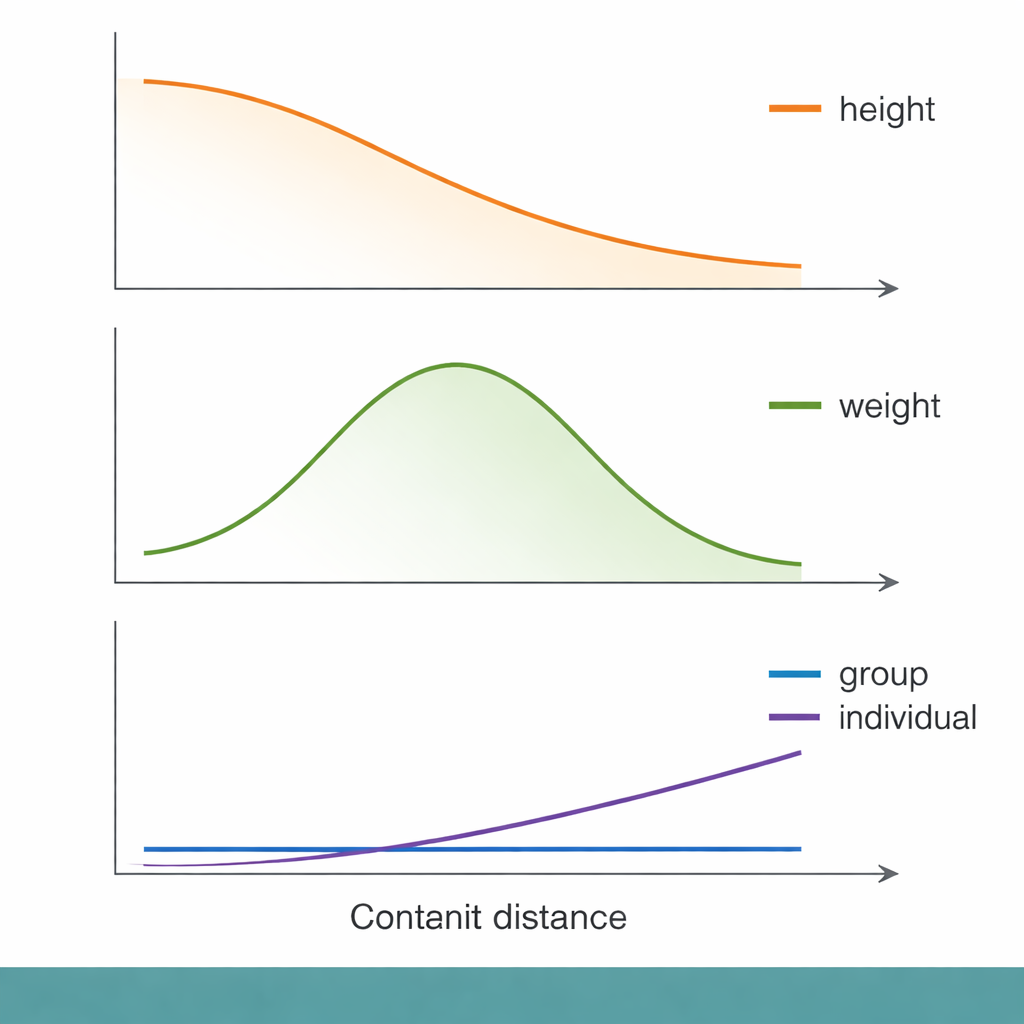
A lo largo de esta escala de distancia genética, surgieron algunos patrones conocidos. Para la altura, por ejemplo, la precisión de la predicción a nivel de grupo disminuyó de forma suave a medida que las personas se alejaban genéticamente del grupo del GWAS. Sin embargo, cuando los investigadores se fijaron a nivel individual, la distancia genética explicó solo una fracción diminuta de por qué se predecían mejor o peor sus rasgos. Medidas socioeconómicas, como el Índice de Privación de Townsend (un indicador a nivel de barrio de desventaja material), rindieron aproximadamente igual —o ligeramente mejor— para explicar quién recibía predicciones pobres. En otras palabras, las personas con menos estatus socioeconómico tendían a obtener predicciones genéticas menos precisas, incluso dentro de la misma banda de distancia genética, lo que subraya que el contexto social puede importar tanto como el ADN para determinar si una puntuación es útil.
Diferentes rasgos, distintas historias, distintas respuestas
No todos los rasgos se comportaron igual. Para el peso corporal y la grasa corporal, la precisión predictiva alcanzó en realidad un pico en distancias genéticas intermedias antes de disminuir, rompiendo el patrón simple de «más lejos significa peor». Los rasgos relacionados con el sistema inmunitario, como los recuentos de glóbulos blancos y linfocitos, mostraron comportamientos especialmente desconcertantes. Para algunos de estos rasgos, la precisión de la predicción a nivel de grupo cayó a casi cero incluso para personas que no estaban genéticamente muy distantes de la muestra del GWAS. Los autores sugieren que los rasgos inmunitarios pueden estar moldeados por presiones evolutivas que cambian rápidamente —como infecciones pasadas— que alteran qué variantes de ADN importan en distintas poblaciones. En estos casos, la propia arquitectura genética puede haber cambiado lo suficiente como para que una puntuación basada en un grupo sea casi inútil en otro.
Cómo medimos el rendimiento puede invertir la interpretación
El panorama se complica aún más cuando cambiamos la forma de medir una «buena predicción». Gran parte del trabajo previo se ha apoyado en una única estadística llamada R², que captura cuánta variación de un rasgo explica una puntuación en un grupo. Los autores muestran que otras métricas pueden contar una historia diferente, especialmente para enfermedades. En el asma, tanto la precisión (cuántos de los casos predichos son casos reales) como la sensibilidad (qué proporción de los casos reales se detectan) disminuyeron con la distancia genética de maneras parecidas. Pero para la diabetes tipo 2, la precisión se mantuvo bastante constante mientras que la sensibilidad aumentó con la distancia —lo que significa que la puntuación encontró una fracción mayor de casos reales en grupos más distantes, aunque se hubiera construido en un grupo más cercano. Dependiendo de si una clínica valora más captar a todos los pacientes de alto riesgo o evitar falsos positivos, se podrían sacar conclusiones opuestas sobre la portabilidad de la puntuación.
Qué significa esto para usar puntuaciones de ADN en la vida real
En conjunto, el estudio sostiene que no podemos juzgar la utilidad de las puntuaciones poligénicas fijándonos solo en etiquetas amplias de ascendencia o en un único número de precisión. La calidad de la predicción individual depende de una mezcla de factores: patrones sutiles de similitud genética, la historia evolutiva de cada rasgo, los entornos y condiciones sociales en los que vive la gente, y la manera concreta en que se elige la puntuación y su métrica de rendimiento. Para que las puntuaciones poligénicas se apliquen de forma justa y eficaz en medicina, los investigadores necesitarán mejores modos de capturar la estructura genética fina, modelar las influencias sociales y ambientales y ajustar las métricas de evaluación a decisiones del mundo real. Hasta entonces, las puntuaciones de riesgo genético deberían usarse con cautela, prestando atención tanto a las personas y contextos en los que funcionan mal como a aquellos en los que brillan.
Cita: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Palabras clave: puntuaciones poligénicas, predicción genética, desigualdades en salud, ascendencia genética, medicina de precisión