Clear Sky Science · es
Redes neuronales físicas empleando entrenamiento consciente de la nitidez
Por qué esto importa para el futuro del hardware de IA
A medida que la inteligencia artificial se vuelve más potente, cada vez está más limitada no por algoritmos ingeniosos, sino por los chips que la ejecutan. Una vía prometedora es construir redes neuronales directamente en hardware físico usando luz, electrónica analógica u otros sistemas basados en ondas. Este artículo presenta una nueva forma de entrenar esas “redes neuronales físicas” para que mantengan la precisión incluso cuando el mundo real es desordenado: cuando los dispositivos están ligeramente mal construidos, hay derivaciones térmicas o componentes pierden alineación.
De cerebros digitales a máquinas físicas
La IA moderna suele ejecutarse en hardware digital como procesadores gráficos, donde el entrenamiento depende del algoritmo de retropropagación para ajustar millones de pesos numéricos. Las redes neuronales físicas intentan trasladar ese cálculo a materiales y dispositivos reales —como chips fotónicos, mallas de interferómetros o arreglos ópticos difractivos— cuyo comportamiento imita de forma natural las operaciones matemáticas de una red neuronal. Porque estos sistemas procesan la información donde se almacena, pueden ser mucho más rápidos y eficientes energéticamente que los chips convencionales. Pero entrenarlos es difícil: o bien entrenas un modelo digital y esperas que coincida con el hardware, o entrenas directamente en el propio dispositivo. Ambos caminos encuentran problemas cuando los dispositivos reales se desvían de los modelos ideales o derivan con el tiempo.
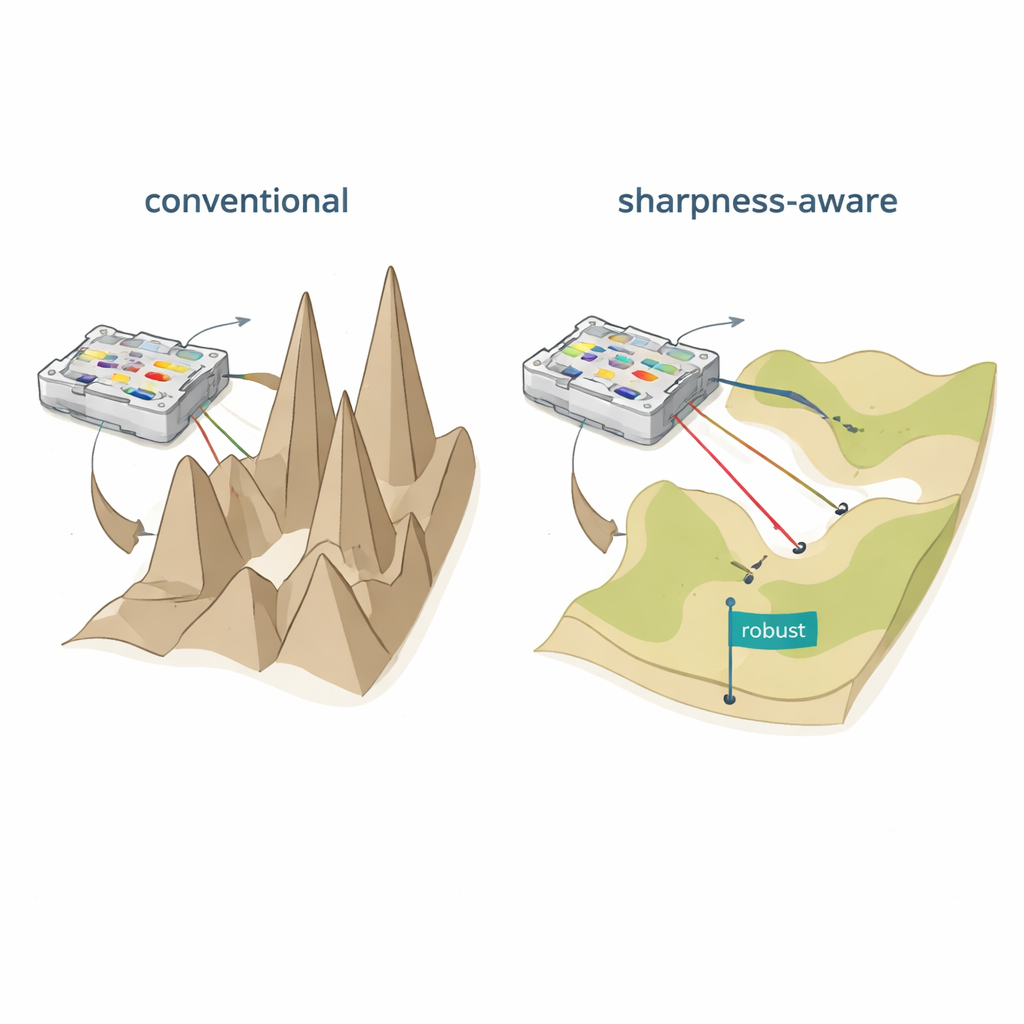
Dos maneras defectuosas de enseñar a redes físicas
El primer enfoque, llamado entrenamiento in silico, aprende todos los parámetros en un modelo por ordenador y luego los copia al hardware. Esto solo funciona bien si el modelo matemático coincide casi perfectamente con el dispositivo fabricado, lo que rara vez ocurre una vez que se incluyen variaciones de fabricación, ruido eléctrico y efectos térmicos. El segundo enfoque, entrenamiento in situ, incorpora el dispositivo físico directamente en el proceso de aprendizaje, midiendo repetidamente las salidas mientras se ajustan los parámetros. Aunque esto evita errores de modelado, crea otros problemas: la información del gradiente es difícil y costosa de obtener, el entrenamiento se vuelve específico del dispositivo y los parámetros resultantes normalmente no se pueden transferir a otro chip nominalmente idéntico. En ambos casos, pequeños cambios tras el despliegue —como un leve cambio de temperatura o una desalineación— pueden reducir drásticamente la precisión y obligar a costosos reentrenamientos.
Applanando el paisaje de aprendizaje
Los autores proponen el entrenamiento consciente de la nitidez (SAT), inspirado en una idea de aprendizaje automático llamada minimización consciente de la nitidez. En lugar de limitarse a encontrar configuraciones que den bajo error en los datos de entrenamiento, SAT busca regiones donde el error cambie lentamente cuando se perturb�n ligeramente los parámetros físicos subyacentes. En términos geométricos, el entrenamiento tradicional suele encontrar un valle profundo pero estrecho en el «paisaje de pérdida», donde incluso pequeños desplazamientos de corrientes, fases o posiciones hacen colapsar el rendimiento. SAT busca deliberadamente valles amplios y planos donde el rendimiento se mantiene alto ante esas perturbaciones. Matemáticamente, añade un término al objetivo de entrenamiento que penaliza regiones afiladas y de alta curvatura en el espacio de parámetros, y aproxima esta penalización de forma eficiente usando dos pasos de gradiente cuidadosamente elegidos en lugar de costosos cálculos de segundas derivadas.
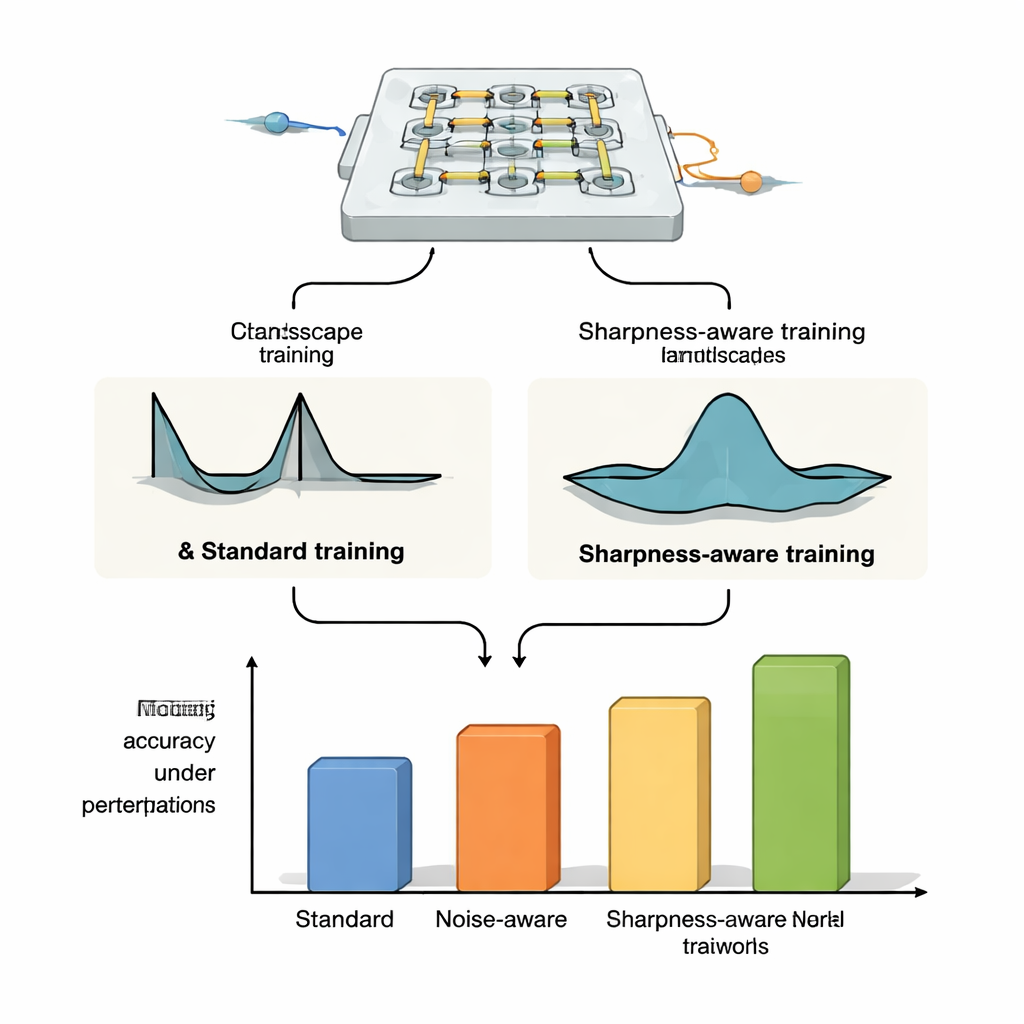
Demostrando robustez en distintas plataformas ópticas
Para mostrar que SAT no está ligado a un único dispositivo, los autores lo aplican a tres plataformas ópticas de redes neuronales diferentes. En bancos de pesos basados en microanillos resonadores —pequeños bucles de silicio que enrutan la luz en distintas longitudes de onda— demuestran que los sistemas entrenados con SAT mantienen una alta precisión de clasificación incluso cuando la temperatura deriva varios grados Celsius, mientras que el entrenamiento estándar y los métodos de inyección de ruido fallan de forma dramática. Lo extienden a tareas más exigentes como clasificación de imágenes en CIFAR-10, compresión y reconstrucción de imágenes y generación de imágenes, donde SAT mantiene el rendimiento estable mientras que los métodos convencionales se rompen ante modestos cambios térmicos. En simulaciones de mallas de interferómetros Mach–Zehnder, los modelos entrenados con SAT son mucho más tolerantes a errores realistas de fabricación y, lo que es crucial, los parámetros entrenados en un dispositivo se pueden transferir a otros chips con imperfecciones diferentes sin perder precisión. Finalmente, en un montaje óptico difractivo de espacio libre que emplea una pantalla OLED, lentes y un modulador espacial de luz, SAT mejora la tolerancia a desalineaciones físicas como rotación, desplazamientos de píxeles y cambios de escala, aunque la relación exacta entre esas desalineaciones y los parámetros de la red no esté modelada explícitamente.
Un camino práctico hacia IA física fiable
En términos sencillos, este trabajo muestra cómo enseñar redes neuronales en hardware de una manera que «perdona» las inevitables peculiaridades de los dispositivos reales. Al orientar el aprendizaje hacia regiones planas y estables del paisaje de error, el entrenamiento consciente de la nitidez hace que las redes neuronales físicas sean a la vez más precisas y más robustas frente a variaciones de fabricación, cambios de temperatura y desalineaciones mecánicas. Dado que puede usarse con o sin modelos físicos detallados y funciona en varios tipos de hardware óptico, SAT ofrece una receta práctica para escalar sistemas de IA física rápidos y energéticamente eficientes desde demostraciones de laboratorio hasta aplicaciones del mundo real.
Cita: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Palabras clave: redes neuronales físicas, computación fotónica, entrenamiento robusto, optimización consciente de la nitidez, hardware neuromórfico