Clear Sky Science · es
Procesador fotónico de matriz-matriz de disparo único basado en difracción hipermultiplexada espacial-espectral en paralelo
Por qué importa una computación más rápida y ecológica
Cada vez que le hacemos una pregunta a un asistente digital o navegamos por redes sociales, potentes modelos de inteligencia artificial trabajan entre bastidores. Estos modelos se están volviendo tan grandes que los chips convencionales tienen dificultades para seguirles el ritmo sin consumir cantidades enormes de energía. Este artículo describe un nuevo tipo de hardware de computación que usa luz en lugar de electricidad para realizar cálculos clave de IA, con el objetivo de hacer que las máquinas futuras sean tanto más rápidas como mucho más eficientes energéticamente.
Convertir la luz en una calculadora
La IA moderna se basa en operaciones llamadas multiplicaciones de matrices, repetidas miles de millones o billones de veces cuando una red neuronal analiza imágenes o texto. Los chips electrónicos realizan este trabajo de forma fiable, pero desperdician mucha energía solo trasladando datos dentro del chip. Los investigadores de este estudio parten de una idea diferente: dejar que la propia luz haga las cuentas. En una red neuronal óptica, la información se codifica en haces láser, se manipula a medida que los haces atraviesan lentes y moduladores, y luego se lee con sensores ópticos. Dado que los fotones no calientan los cables como los electrones, estos sistemas pueden, en principio, alcanzar velocidades y eficiencias mucho mayores.
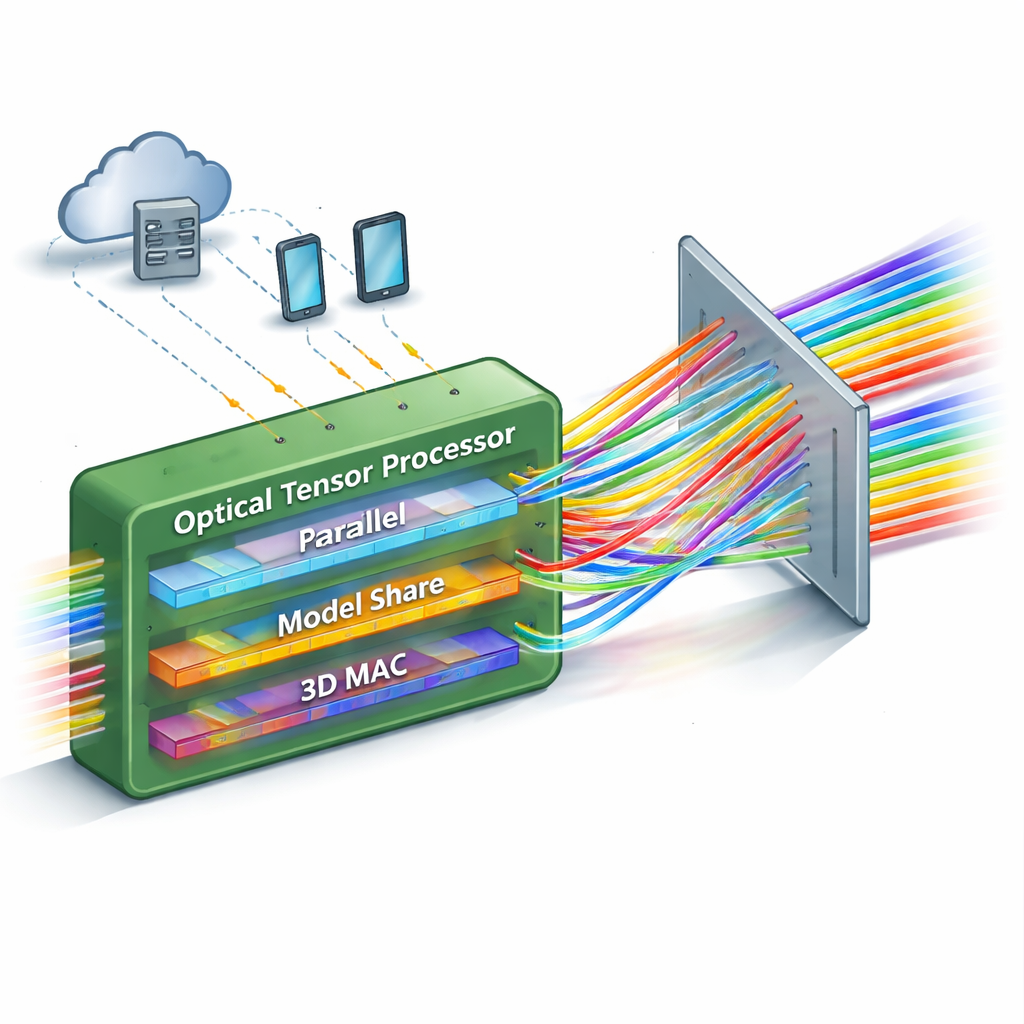
Realizar muchos cálculos de un solo golpe
La mayoría de las redes neuronales ópticas existentes tienen una limitación: solo pueden manejar un número moderado de cálculos en paralelo o se vuelven demasiado complejas para escalar. Este trabajo presenta un procesador fotónico de matriz–matriz de “disparo único” que aumenta drásticamente cuántas operaciones se pueden realizar a la vez. La idea clave es empaquetar información en tres aspectos diferentes de la luz simultáneamente: su posición en el espacio, su color (longitud de onda) y su sincronización. Al arreglar cuidadosamente estas dimensiones, el dispositivo puede realizar una multiplicación completa de matriz–matriz, que implica miles de pasos de multiplicar y acumular, en una sola pasada de la luz a través del sistema.
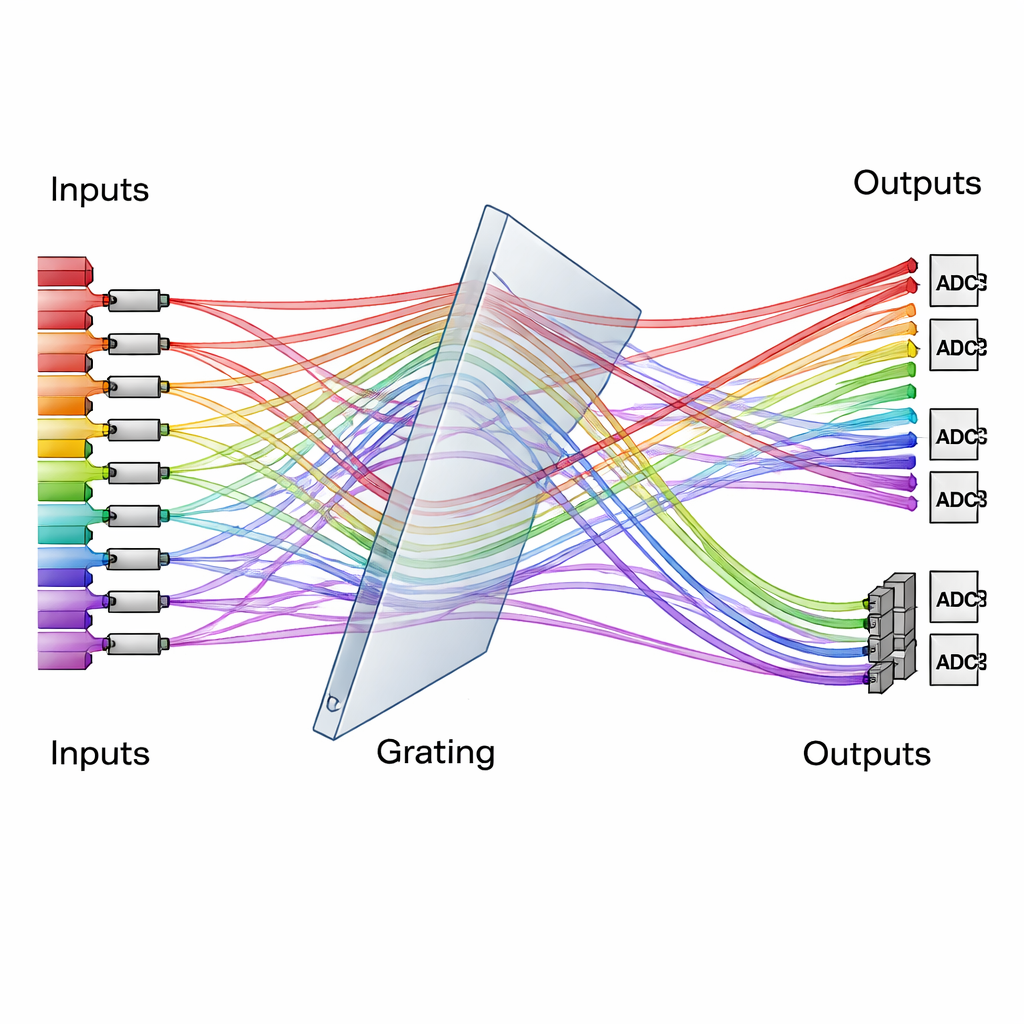
Una rejilla de difracción como controlador de tráfico para la luz
En el corazón del diseño hay un elemento óptico simple pero poderoso: una rejilla de difracción, que divide la luz en diferentes ángulos según su color. El equipo utiliza un sistema de rejillas tridimensional especialmente dispuesto como un controlador de tráfico, encaminando muchos haces coloreados desde muchos canales de entrada hacia canales de salida reordenados. Los datos a procesar se codifican como intensidades de luz en un conjunto de moduladores, mientras que los “pesos” de la red neuronal se codifican en otro conjunto. Cuando los haces se encuentran y atraviesan la rejilla, sus trayectorias se reordenan de modo que cada canal de salida suma de forma natural las combinaciones correctas de datos y pesos. Detectores que integran en el tiempo acumulan las contribuciones a lo largo de varios pasos de tiempo cortos, ampliando efectivamente el tamaño de la computación sin añadir complejidad extra a la óptica.
Del montaje de laboratorio a tareas reales de IA
Los autores demuestran un procesador tensorial óptico 16 por 16 por 16 por 16, lo que significa que puede multiplicar una matriz 16×16 por otra 16×16 en un solo “disparo” óptico, logrando 4096 operaciones básicas a la vez. El sistema funciona a velocidades de reloj de varios gigahercios y alcanza una precisión de cálculo efectiva de más de ocho bits, comparable a muchos aceleradores de IA prácticos. Para mostrar que esto no es solo una demostración física, usan el procesador para ejecutar partes de una pequeña canalización de reconocimiento de imágenes: una red neuronal convolucional que extrae características de imágenes de dígitos, seguida de una red totalmente conectada que las clasifica. Incluso con ruido óptico e imperfecciones del hardware, el montaje reconoce correctamente dígitos escritos a mano con aproximadamente un 96% de precisión, cercano a una implementación totalmente digital del mismo modelo.
Consumo energético, sensibilidad y hasta dónde se puede escalar
Puesto que la arquitectura reutiliza los mismos componentes ópticos a lo largo de muchos canales paralelos y acumula las señales de forma eficiente, cada operación básica puede llevarse a cabo con muy poca energía: hasta decenas de attojulios de energía óptica por multiplicación. Los autores estiman una eficiencia energética global que ya supera a algunos aceleradores electrónicos de IA de última generación, y sostienen que mejoras modestas en moduladores y convertidores digital-analógico podrían llevar esto a cientos de billones de operaciones por segundo por vatio. Es importante destacar que el diseño evita algunos de los obstáculos de escalado que afectan a otros esquemas ópticos, por lo que versiones mayores con muchos más canales (por ejemplo matrices de 30×30 o incluso 60×60) parecen factibles usando componentes similares.
Qué significa esto para la tecnología cotidiana
En términos sencillos, esta investigación muestra que un montaje óptico relativamente simple—una forma inteligente de encaminar haces de luz coloreada a través de una rejilla de difracción—puede actuar como un motor potente y de baja energía para cálculos tipo IA. Aunque aún es un prototipo de laboratorio, apunta hacia futuros centros de datos y dispositivos perimetrales donde procesadores basados en luz manejen las cargas de trabajo más pesadas de redes neuronales, reduciendo las facturas energéticas y posibilitando modelos más grandes y rápidos. Si tales procesadores tensoriales fotónicos pueden integrarse y fabricarse a escala, podrían convertirse en un ingrediente clave de la próxima generación de hardware de inteligencia artificial de alto rendimiento y eficacia energética.
Cita: Luan, C., Davis III, R., Chen, Z. et al. Single-shot matrix-matrix photonic processor based on spatial-spectral hypermultiplexed parallel diffraction. Nat Commun 17, 484 (2026). https://doi.org/10.1038/s41467-026-68452-x
Palabras clave: redes neuronales ópticas, computación fotónica, multiplicación de matrices, hardware de IA energéticamente eficiente, rejilla de difracción