Clear Sky Science · es
Cartografía exhaustiva de la dinámica y el diálogo de las modificaciones de ARN mediante aprendizaje profundo y secuenciación directa de ARN por nanoporo
Las señales de puntuación ocultas del ARN
Las moléculas de ARN de nuestras células no son simples cadenas de A, C, G y U. Están decoradas con decenas de pequeñas marcas químicas que actúan como signos de puntuación, ayudando a controlar qué genes se activan, cómo se sintetizan las proteínas y cómo responden las células al estrés y a la enfermedad. Sin embargo, hasta ahora, los científicos en su mayoría las han estudiado una a una, lo que dificulta observar cómo cooperan a lo largo de todo el genoma. Este artículo presenta ORCA, un sistema de aprendizaje profundo que lee moléculas de ARN nativas directamente y construye un mapa global y multicapa de estas marcas químicas y de cómo interactúan.
Una nueva forma de leer las marcas químicas en el ARN
Los métodos tradicionales para detectar modificaciones de ARN suelen depender de anticuerpos específicos o de reacciones químicas afinadas para un único tipo de marca, como la popular N6‑metiladenosina (m6A). Eso los hace potentes pero restrictivos: cada técnica detecta solo una clase de marca, con frecuencia en un único diseño experimental. La secuenciación directa de ARN por nanoporo abrió otra vía al pasar moléculas individuales de ARN por un poro minúsculo y medir los cambios en la corriente eléctrica que dependen de la estructura química exacta de cada base. Las letras modificadas y no modificadas distorsionan la señal y la predicción de bases de maneras sutilmente distintas, pero interpretar estos datos ruidosos y de alta dimensionalidad para muchos tipos de modificación ha sido un gran desafío.
Enseñar a una red neuronal a detectar cualquier marca
ORCA (Omni‑RNA modification Characterization and Annotation) aborda este reto en dos etapas. Primero, se centra en una pequeña ventana alrededor de cada posición en el ARN y agrega tanto la señal eléctrica cruda como el patrón de errores de secuenciación a lo largo de muchas lecturas. Dado que solo una fracción de las copias de ARN llevan una marca dada, los sitios verdaderamente modificados muestran distribuciones de señal más sesgadas y errores de basecalling más frecuentes en esa posición. ORCA utiliza una red neuronal recurrente profunda entrenada con una estrategia “adversaria” para que aprenda patrones generales que distinguen sitios modificados de no modificados, sin fijarse en ningún tipo químico conocido en particular. Esto permite a ORCA asignar a cada sitio una puntuación de modificación y una estimación de la fracción de moléculas que están modificadas.
Aprender la identidad de cada marca
En la segunda etapa, ORCA aprende a etiquetar qué tipo de marca química está presente. Los autores alimentan el modelo con un conjunto de sitios de alta confianza procedentes de bases de datos públicas, donde experimentos convencionales ya han identificado m6A, 5‑metilcitosina (m5C), pseudouridina (Ψ), inosina, 2′‑O‑metilación y varias marcas más raras. ORCA comprime los patrones de señal, el contexto de la secuencia y los «motivos» cortos alrededor de cada sitio en un mapa de menor dimensionalidad, y después se ajusta finamente para predecir el tipo de modificación y la base exacta sobre la que se sitúa. De forma crucial, los sitios no etiquetados también se usan como ejemplos de “fondo”, lo que ayuda al modelo a evitar forzar marcas desconocidas en la categoría equivocada. Una vez entrenado, ORCA puede transferir estas etiquetas aprendidas a decenas de miles de sitios previamente no anotados a lo largo del transcriptoma.
Ver muchas modificaciones a la vez
Al aplicar ORCA a células humanas y de ratón, los autores muestran que no solo iguala o supera la precisión de las herramientas punteras para marcas específicas como m6A, m5C y Ψ, sino que también puede detectar marcas sobre las que nunca se entrenó explícitamente. Por ejemplo, incluso cuando se retuvieron los datos de m6A durante el entrenamiento, ORCA recuperó la mayoría de los sitios de m6A medidos de forma independiente y los distinguió correctamente de motivos de secuencia similares que no estaban modificados. Hizo lo mismo con grupos 2′‑O‑metil, sitios de edición por inosina y una amplia variedad de cambios químicos en ARN ribosómico, incluyendo muchas modificaciones raras medidas por espectrometría de masas. En conjunto, ORCA amplía considerablemente el catálogo conocido de sitios de modificación de ARN, con aumentos múltiples en la anotación de m5C, Ψ, m7G y otras marcas de baja abundancia en comparación con las bases de datos existentes.
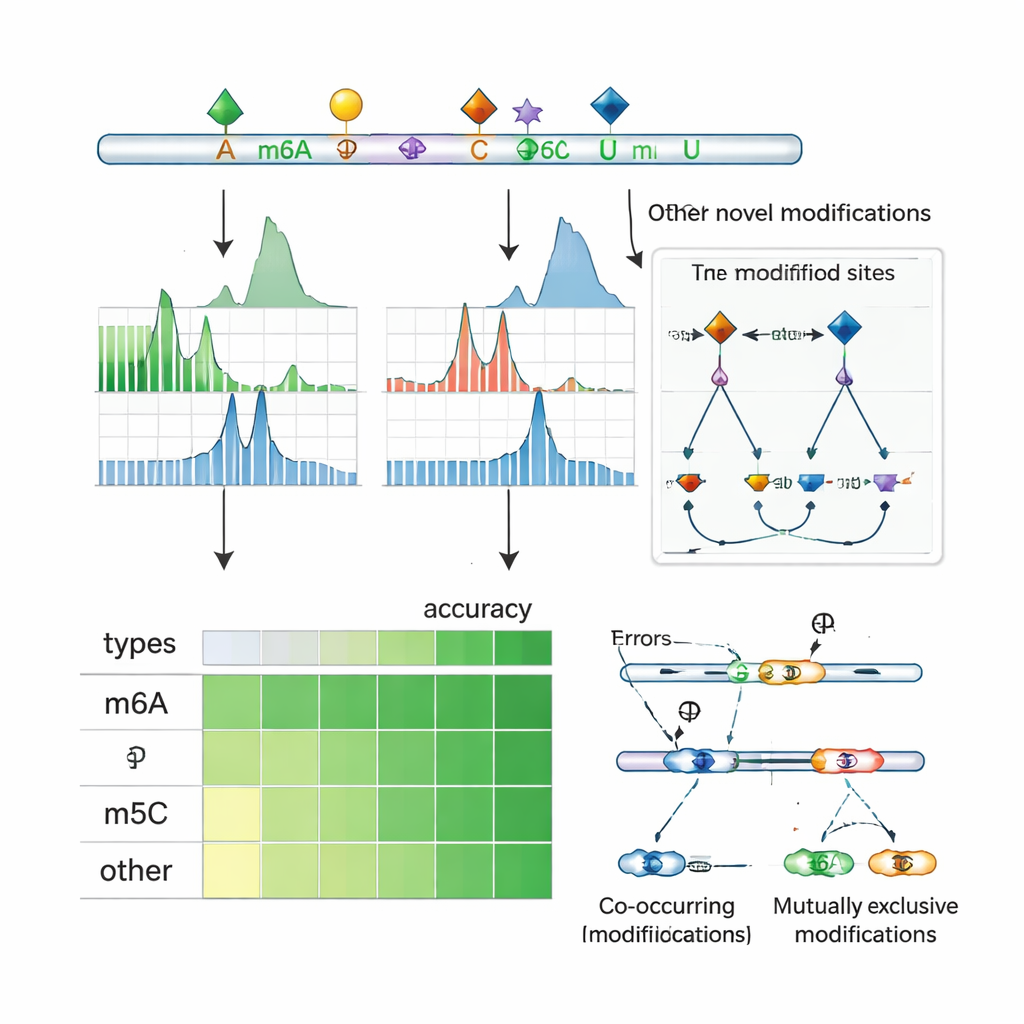
Descubriendo diálogo entre marcas y control del splicing
Puesto que la secuenciación por nanoporo lee moléculas de ARN completas, ORCA puede examinar qué marcas aparecen juntas en el mismo transcrito y cuáles tienden a excluirse mutuamente. Los autores agrupan marcas cercanas a lo largo de los ARN y utilizan un modelo probabilístico para inferir si pares de sitios suelen estar co‑modificados o son mutuamente exclusivos en moléculas individuales. Encuentran co‑ocurrencias frecuentes de m6A con m5C y otras marcas, así como muchas regiones donde un sitio se modifica solo cuando el sitio vecino no lo está. En líneas celulares humanas, estos patrones suelen localizarse cerca de exones que se incluyen o se saltan de forma alternativa, y solapan sitios de unión de reguladores del splicing y de proteínas “lectoras” que reconocen ARN modificado. En genes concretos, ORCA revela que ciertas variantes de empalme están enriquecidas en un patrón de marcas, mientras que variantes alternativas llevan un patrón distinto, vinculando la decoración química local del ARN con la forma en que los mensajes se cortan y se cosen.
Por qué esto importa para la biología y la medicina
Al combinar la secuenciación directa de ARN con aprendizaje profundo flexible, ORCA convierte una señal eléctrica compleja en un mapa rico y multicapa de marcas químicas a lo largo del transcriptoma. Para el público no especializado, el resultado clave es que los científicos ya pueden ver no solo dónde ocurren modificaciones individuales del ARN, sino cuántas marcas distintas decoran la misma molécula y cómo esas combinaciones se relacionan con la regulación génica, en especial el splicing del ARN. Este marco permite estudiar la “epigenética” del ARN en muchos tipos celulares y condiciones sin diseñar un experimento nuevo para cada marca, allanando el camino para descubrimientos sobre cómo estos pequeños ajustes químicos contribuyen al desarrollo, la función cerebral y a enfermedades como el cáncer y los trastornos neurológicos.
Cita: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Palabras clave: Modificaciones de ARN, secuenciación por nanoporo, aprendizaje profundo, epitranscriptoma, splicing alternativo