Clear Sky Science · es
Estimación y edición de iluminación neural desde una sola vista para pantallas de campo de luz dinámicas
Por qué tu mundo virtual debería coincidir con tu salón
Cualquiera que haya usado unas gafas de realidad virtual o mixta lo habrá visto: un objeto digital que parece fuera de lugar, con iluminación y sombras que no encajan del todo con la habitación real. Este artículo aborda ese problema. Los autores presentan un método para que los cascos «entiendan» la iluminación de tu entorno real a partir de una sola vista de cámara, y luego usen esa información para que los objetos virtuales parezcan realmente pertenecer a tu mundo, sin necesidad de sondas de luz especiales, capturas complejas ni recalibraciones pesadas.
Hacer la luz en el espacio más manejable
En física y gráficos por computador, la apariencia de una escena está gobernada por su «campo de luz» completo: todos los rayos de luz que fluyen por el espacio en cada dirección. Reconstruir este campo con exactitud suele requerir muchos datos, muchas imágenes y mediciones cuidadosas. Técnicas 3D modernas como los campos de radiancia neuronales pueden almacenar escenas en redes neuronales, pero normalmente «fijan» la iluminación presente durante la captura. Eso significa que la escena virtual solo se ve bien bajo esas condiciones originales y se desmonta cuando cambia la iluminación real de la sala. Los autores pretenden romper esa limitación encontrando una descripción compacta de la iluminación del mundo real a partir de datos mínimos y usándola para reiluminar de forma flexible una escena 3D neural.
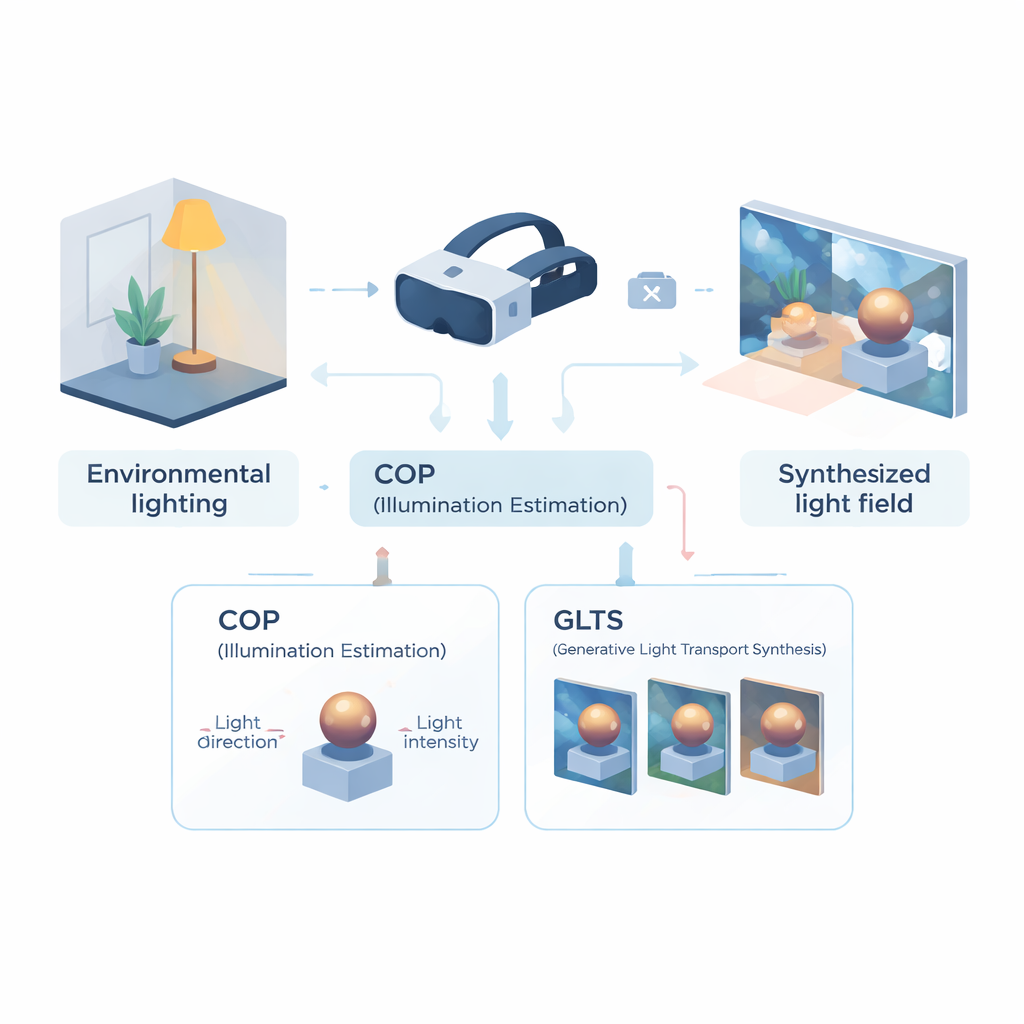
Enseñar al casco a leer la habitación
La primera parte del marco es un módulo de percepción óptica computacional (COP), diseñado para leer la iluminación desde una sola vista de cámara. En lugar de reconstruir todo el campo de luz, COP se centra en la fuente de luz dominante: su dirección y su intensidad. Una red neuronal multiescala examina la imagen de entrada en busca de señales físicas reveladoras —reflejos brillantes, gradientes de sombreado y sombras— mientras que un paso de interpolación especial corrige la forma no lineal en que las cámaras comprimen el brillo. Esto produce estimaciones numéricas de la intensidad y la dirección de la luz que son más fieles a la energía real en la escena. Una segunda etapa, llamada intérprete semántico, refina estos valores y genera una breve descripción en forma de texto sobre la iluminación (por ejemplo, que la luz viene desde arriba y por la derecha). Esta combinación de números y palabras hace que la estimación sea más estable y más fácil de usar en las etapas siguientes.
Repintar objetos con nueva luz
Con esta descripción compacta de la iluminación, toma el relevo el segundo módulo: síntesis generativa de transporte de luz (GLTS). GLTS parte de una representación 3D neural existente de un objeto o escena, renderizada una vez bajo su iluminación antigua fijada. Guiada por la dirección de la luz inferida, la intensidad y la descripción textual, una red generativa «repinta» esta vista para que los brillos y las sombras coincidan con el nuevo entorno. Para mantener el resultado realista y específico del objeto, GLTS combina dos tipos de guía: control global a partir de los parámetros de iluminación y detalle fino extraído directamente de la imagen observada. Mediante un proceso de entrenamiento especializado que se concentra únicamente en cómo un objeto individual responde a distintas iluminaciones, el modelo aprende a desplazar reflejos y suavizar los bordes de las sombras de maneras físicamente plausibles en lugar de aplicar simplemente un filtro de estilo genérico.
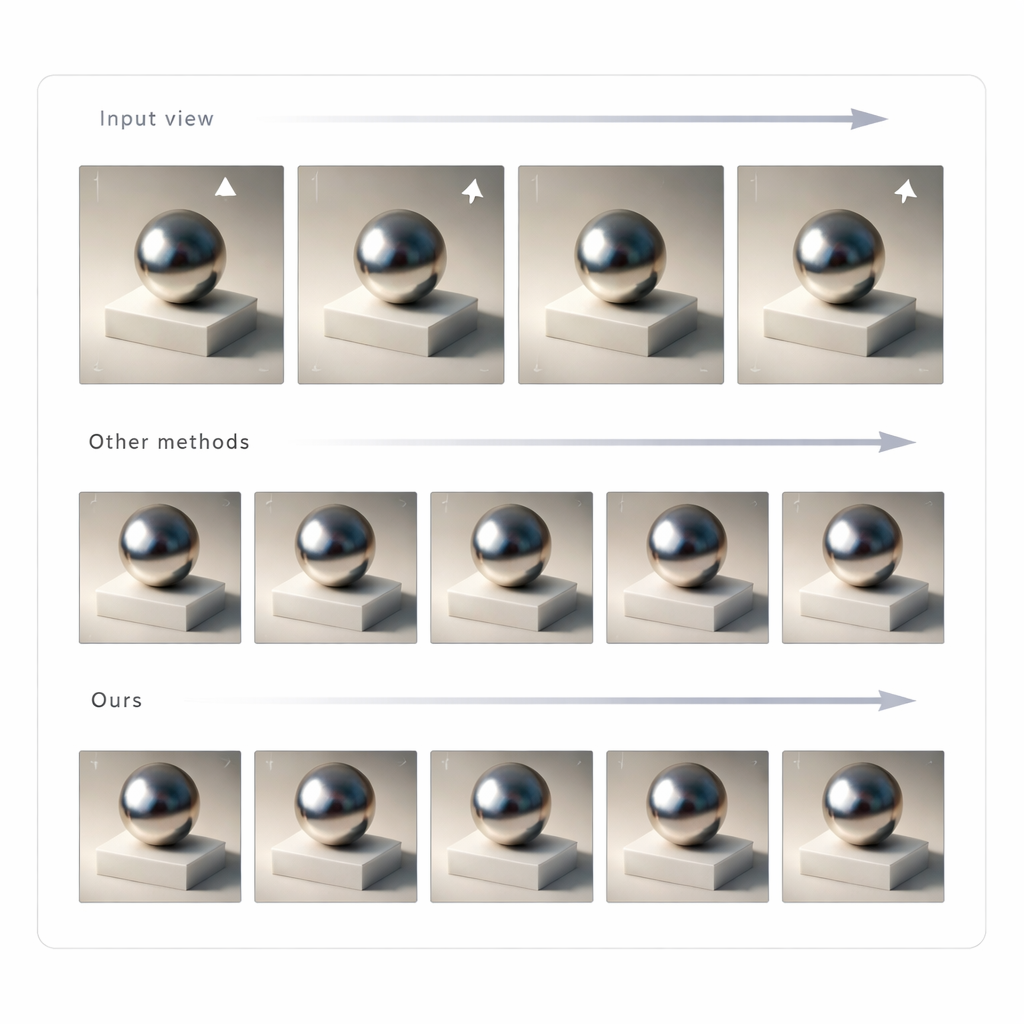
Construir un campo de luz 3D consistente a partir de muchas vistas
Cambiar una sola imagen no es suficiente para una realidad mixta convincente; la iluminación debe permanecer consistente al mover la cabeza. Para lograrlo, los autores usan GLTS para generar un conjunto de imágenes reiluminadas desde múltiples puntos de vista y luego tratan estas imágenes como objetivos para reconstruir la escena 3D. Un proceso de optimización conjunta ajusta simultáneamente la representación 3D neuronal y las posiciones de las cámaras virtuales de modo que renderizar el nuevo modelo reproduce todas las vistas sintetizadas. Este paso corrige distorsiones sutiles introducidas por la red generativa y produce un activo 3D coherente cuya apariencia se mantiene estable y creíble desde cualquier ángulo. El equipo comparó su método con varios enfoques de reiluminación de última generación y observó que ofrecía una concordancia más nítida con las imágenes de referencia y sombras y reflejos de aspecto más natural, según métricas tanto a nivel de píxel como basadas en la percepción.
Qué significa esto para los cascos del futuro
Para el público no especializado, la conclusión clave es que este trabajo muestra cómo los futuros dispositivos de RV, RA y realidad mixta podrían adaptar el contenido virtual a la iluminación del mundo real con una sola rápida mirada a través de la cámara del casco. En lugar de montajes de captura laboriosos o de reentrenar modelos hechos a medida para cada escena, el sistema estima las condiciones de iluminación principales, regenera cómo debería verse la escena bajo esas condiciones y reconstruye una representación 3D consistente. El resultado son objetos virtuales cuya luminosidad, brillo y sombras responden a tu entorno de forma parecida a los objetos reales, allanando el camino para experiencias de realidad mixta que se perciban menos como gráficos superpuestos y más como adiciones genuinas al mundo físico.
Cita: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Palabras clave: iluminación de realidad mixta, campos de luz neuronales, reiluminación desde una sola vista, pantallas de realidad virtual, imagen computacional