Clear Sky Science · es
Reconocimiento multimodal de imágenes del patrimonio cultural basado en una red de fusión multimodal cuántica y clásica
Por qué importa enseñar a los ordenadores sobre tesoros antiguos
Los tesoros culturales en museos y archivos se fotografían cada vez más y se suben a la red, pero la mayoría de estas imágenes están pobremente etiquetadas o no lo están en absoluto. Eso dificulta que visitantes, docentes e investigadores encuentren lo que buscan y limita la profundidad con que el público puede explorar el patrimonio compartido de la humanidad. Este artículo explora una nueva forma de reconocer y clasificar automáticamente esas imágenes combinando dos ideas que rara vez se juntan: las colecciones de museos y la computación cuántica.
De los almacenes polvorientos a las colecciones digitales
Hoy los museos conservan millones de objetos, desde bronces y lacados hasta túnicas bordadas. Muchas instituciones compiten por digitalizar sus fondos para que cualquiera con conexión a Internet pueda explorarlos. Sin embargo, una vez que las imágenes están en línea deben colocarse en las categorías correctas —por ejemplo esmalte, jade, seda o brocado— para resultar verdaderamente útiles. Las herramientas convencionales de inteligencia artificial suelen fijarse solo en los píxeles de cada imagen. Ignoran las ricas descripciones escritas que los conservadores e historiadores añaden a los objetos, pese a que estas leyendas a menudo mencionan materiales, colores y motivos que no son evidentes a simple vista. A medida que las colecciones crecen, los algoritmos clásicos también sufren por la velocidad, el consumo energético y la complejidad.
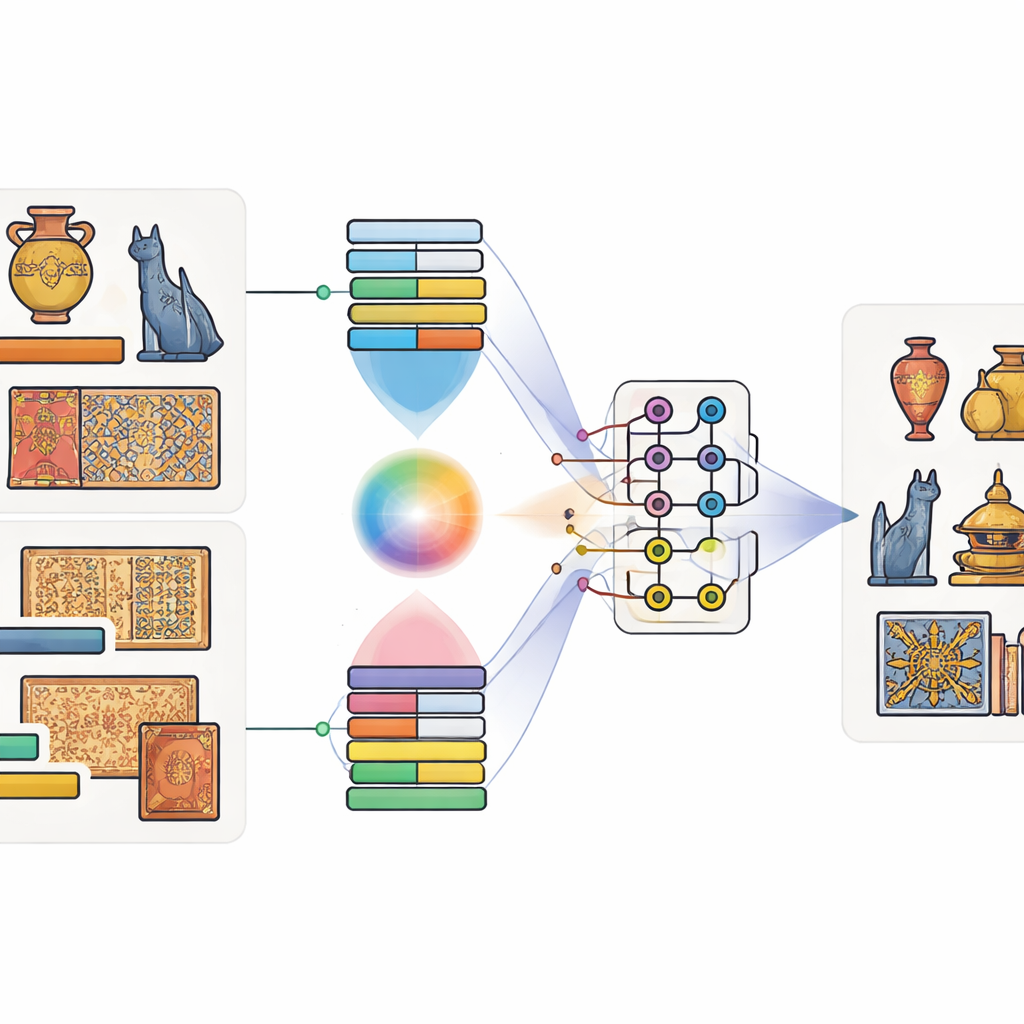
Emparejar imágenes con palabras, y bits con qubits
Los autores proponen un modelo que llaman Modelo de Fusión Multimodal Cuántico-Clásico. «Multimodal» significa simplemente que presta atención a más de un tipo de información a la vez—en este caso, tanto la imagen de un artefacto como su leyenda. Primero se usan herramientas bien establecidas y entrenadas con enormes conjuntos de datos: una red profunda de imágenes para captar formas y texturas, y un modelo de lenguaje para captar el significado de la leyenda. Un mecanismo de atención especial aprende entonces qué regiones de la imagen tienden a corresponder con qué palabras. Por ejemplo, cuando una leyenda menciona «dragón dorado», el modelo aprende a centrarse en regiones de color dorado con forma de dragón. Esto produce una descripción conjunta que combina vista y lenguaje.
Permitir que circuitos cuánticos mezclen las señales
Una vez extraídas las características de imagen y texto, el modelo las alimenta a un pequeño circuito cuántico simulado. Debido a que el hardware cuántico actual dispone solo de un número modesto de qubits, los autores comprimen la información usando un esquema que empaqueta muchos valores clásicos en las amplitudes de unos pocos qubits. Dentro de la parte cuántica diseñan un circuito de dos etapas que aplica repetidamente rotaciones a qubits individuales y luego los entrelaza—forzando que sus estados se vuelvan interdependientes. Esta estructura pretende sacar a la luz relaciones sutiles entre patrones visuales y pistas de la leyenda que de otro modo podrían pasarse por alto. Tras este procesamiento cuántico, el estado de los qubits se mide y se convierte de nuevo en números ordinarios, que luego se pasan a un clasificador final que predice la categoría del objeto.
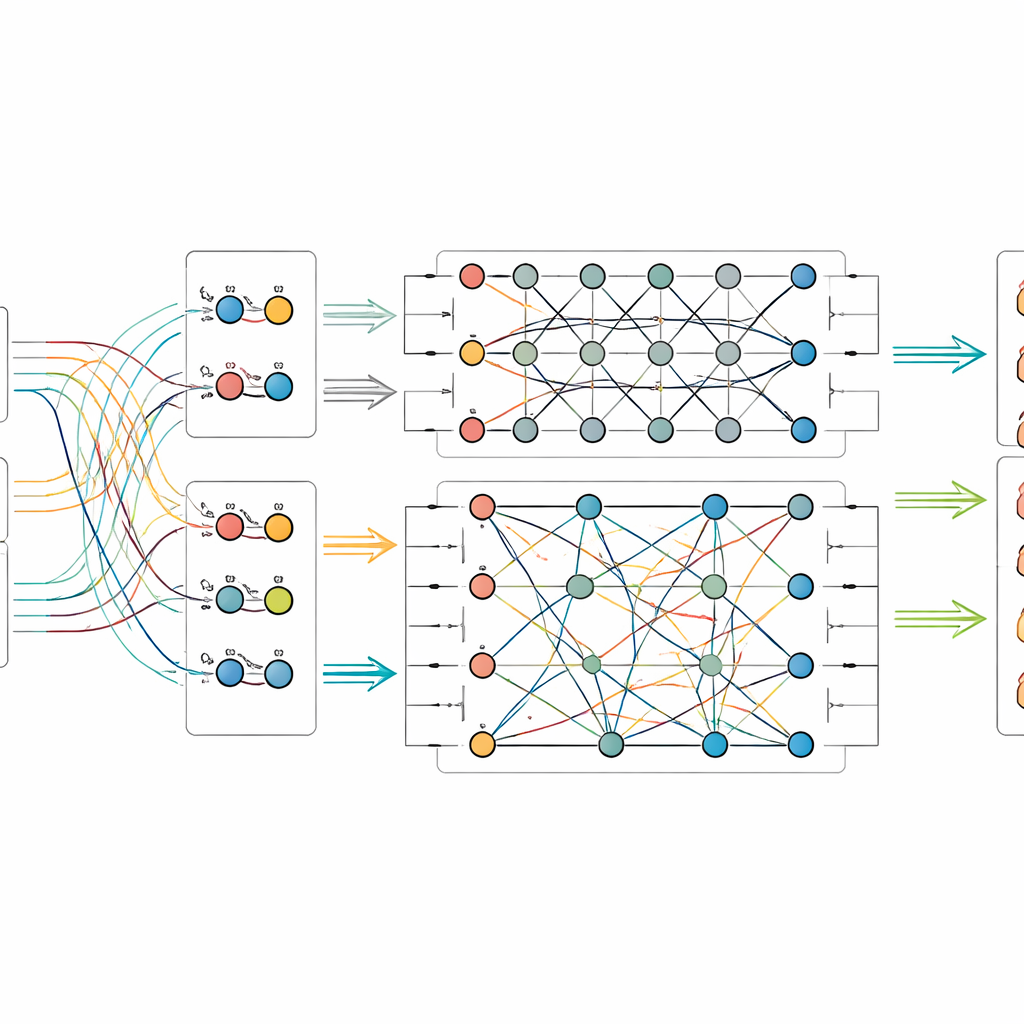
Poner a prueba el nuevo enfoque
Para comprobar si su método ofrece beneficios reales, los investigadores reunieron dos nuevos conjuntos de datos procedentes del Palacio Museo: uno de artefactos físicos como esmalte, trabajos en oro y plata, laca, bronce y jade, y otro centrado en textiles como seda, raso, brocado y el intrincado estilo de tejido conocido como kesi. Cada imagen incluye una leyenda oficial y una etiqueta fiable procedente de los registros del museo. Compararon su modelo de fusión cuántico–clásico frente a una gama de rivales potentes, incluidos sistemas puramente de imagen, puramente de texto y otras técnicas que combinan ambos. En ambos conjuntos de datos, el nuevo modelo alcanzó las puntuaciones más altas en precisión y medidas relacionadas, superando incluso a avanzadas líneas base multimodales e inspiradas en lo cuántico. Experimentos adicionales mostraron cómo su rendimiento depende del número de qubits y de la profundidad del circuito, y que sigue siendo fiable incluso cuando se introducen en simulación tipos comunes de ruido cuántico.
Lo que esto podría significar para los visitantes de museos del futuro
Para el público general, el mensaje clave es que mezclar imágenes, palabras y procesamiento inspirado en lo cuántico puede mejorar la capacidad de los ordenadores para distinguir distintos tipos de objetos culturales. Aunque las partes cuánticas se ejecutan actualmente en simuladores más que en máquinas cuánticas a gran escala, el estudio sugiere un camino hacia herramientas más eficientes y expresivas a medida que el hardware madure. En términos prácticos, tales sistemas podrían ayudar a museos y archivos a clasificar automáticamente nuevas subidas, limpiar registros antiguos y facilitar que la gente busque «vasijas rituales de jade» o «túnicas bordadas con dragones» y realmente las encuentre. El trabajo insinúa que la computación cuántica podría convertirse en una nueva vía útil para comprender y preservar el patrimonio cultural en la era digital.
Cita: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Palabras clave: imágenes del patrimonio cultural, aprendizaje automático cuántico, fusión multimodal, digitalización de museos, reconocimiento de imágenes