Clear Sky Science · es
Identificación de información visual y preguntas y respuestas sobre herederos del patrimonio cultural inmaterial mediante un marco mejorado de Graph-Retrieval
Llevando las tradiciones ocultas a la era digital
En toda China, maestros de la ópera tradicional, el recorte de papel, la marioneta de sombra y otras artes vivas preservan técnicas transmitidas durante generaciones. Sin embargo, gran parte de lo que sabemos sobre estos herederos existe solo en archivos e imágenes dispersas en línea, lo que dificulta que el público —o incluso los investigadores— encuentre información fiable. Este artículo presenta un nuevo marco informático que lee automáticamente las “tarjetas visuales” de los herederos del patrimonio cultural inmaterial (PCI) y luego utiliza modelos de lenguaje avanzados para responder preguntas y generar informes comprensibles sobre ellos.
De tarjetas ilustradas a conocimiento estructurado
Muchas instituciones culturales publican ahora tarjetas digitales que combinan texto, diseño y gráficos simples para presentar a cada heredero: nombre, oficio, lugar, biografía y más. Los humanos pueden hojearlas de un vistazo, pero las máquinas tienen dificultades porque las tarjetas provienen de muchas regiones, usan distintos diseños y a menudo contienen texto faltante o dañado. Los autores construyen un gran conjunto de datos de 5.237 de esas tarjetas para herederos del PCI chino, cada una etiquetada cuidadosamente con diez tipos clave de información, como número de proyecto, nombre del proyecto, región, género, unidad de trabajo y una breve descripción. Primero utilizan reconocimiento óptico de caracteres (OCR) para leer el texto y registrar dónde aparece cada fragmento en la tarjeta; luego emplean grandes modelos de lenguaje para ayudar a estandarizar las etiquetas antes de que expertos humanos las verifiquen.
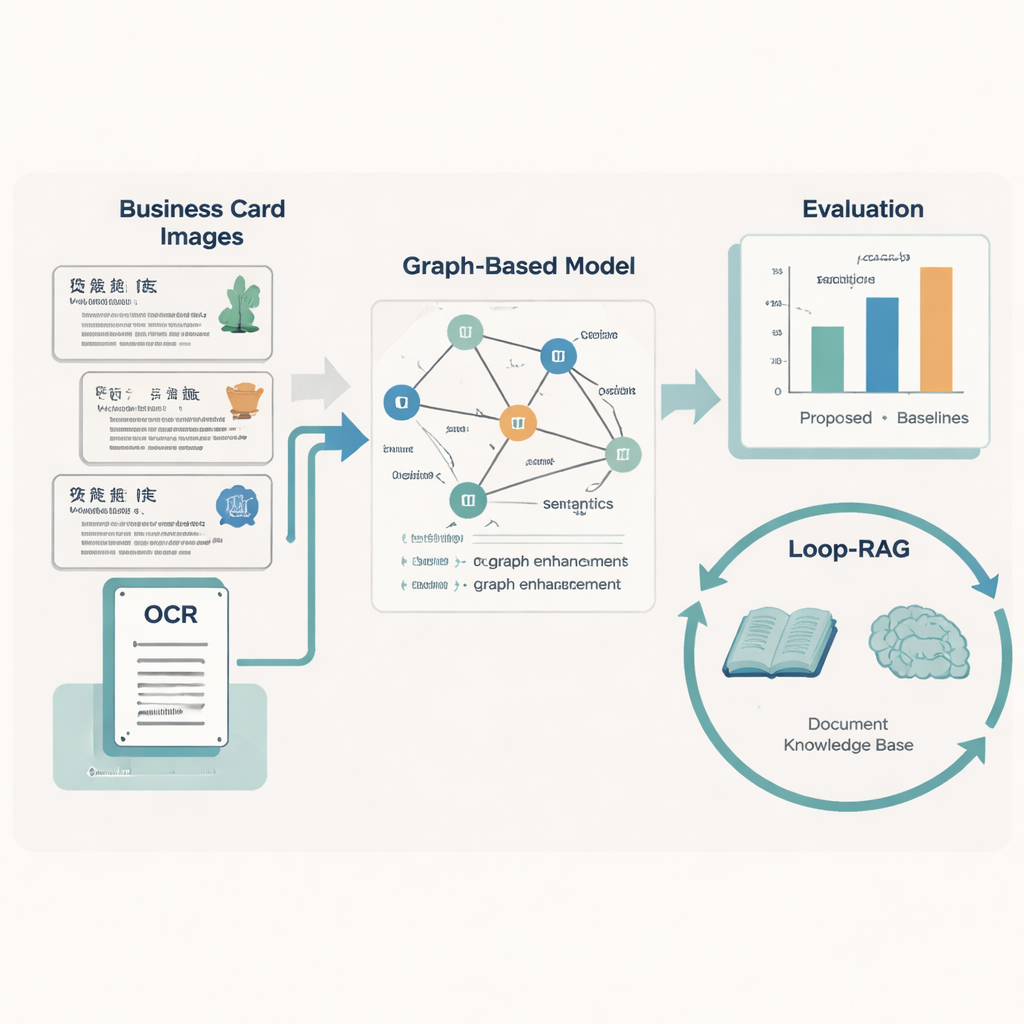
Enseñando a las máquinas a leer diseño y significado
Para convertir cada tarjeta en datos limpios y estructurados, el equipo diseña un modelo “Graph-Retrieval” que imita cómo las personas usan tanto las palabras como el diseño. Cada fragmento de texto de una tarjeta se convierte en un nodo de un grafo, y las relaciones espaciales entre fragmentos —izquierda, derecha, arriba, abajo— forman las aristas. Un componente lingüístico basado en RoBERTa y un LSTM bidireccional aprende el significado del texto, respaldado por un diccionario personalizado de casi 5.000 términos específicos del PCI para manejar correctamente nombres de oficios inusuales o frases locales. Sobre esto, una red neuronal gráfica difunde información entre nodos vecinos, mejorando las predicciones sobre lo que representa cada fragmento de texto (por ejemplo, decidir si un nombre de lugar es una región o una unidad de trabajo).
Haciendo el sistema robusto frente a la desordenada realidad
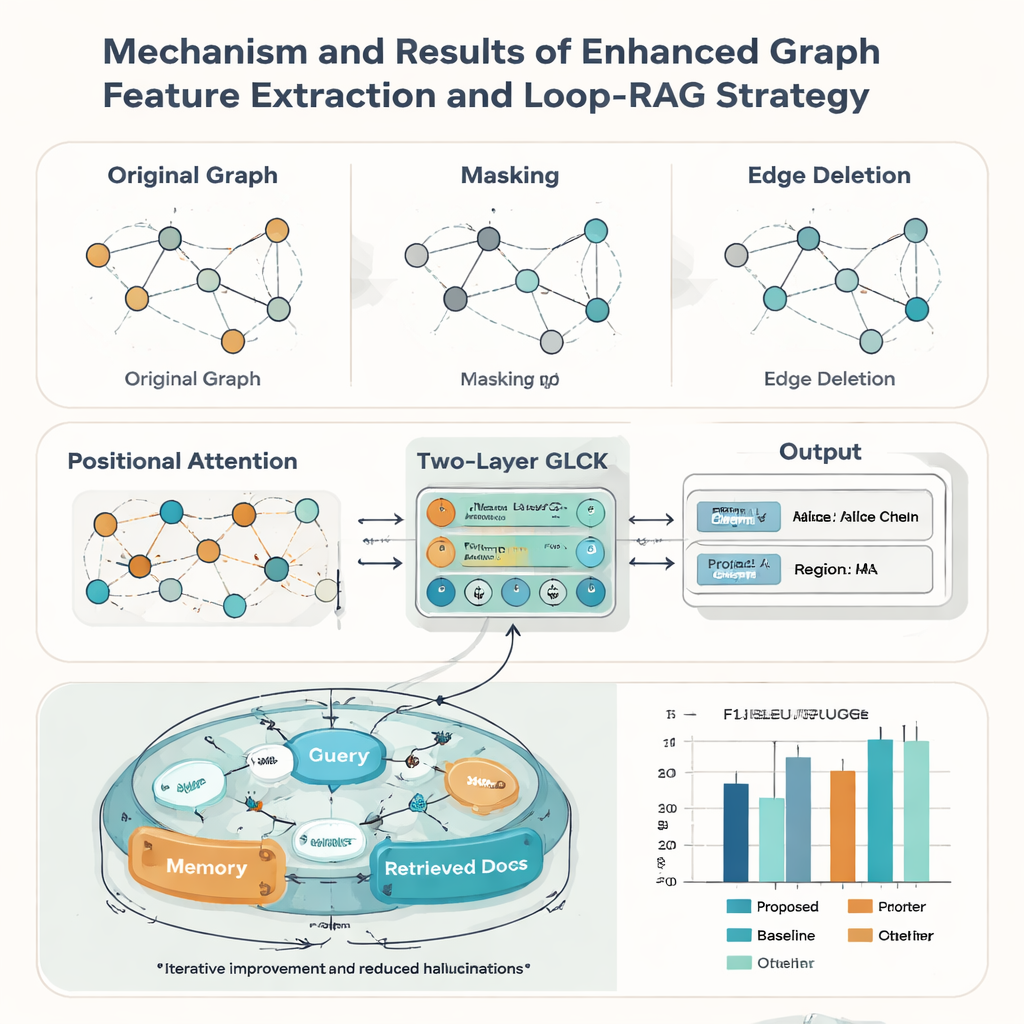
Los registros patrimoniales reales rara vez son perfectos: las tarjetas pueden estar desgastadas, recortadas o mal escaneadas. Para afrontarlo, los autores refuerzan su modelo de grafo con tres ideas tomadas de la aumentación de datos. Enmascaran aleatoriamente algunos nodos para que el sistema aprenda a inferir la información faltante a partir del contexto; eliminan aleatoriamente algunas aristas para que tolere cambios en el diseño; y añaden un mecanismo de atención posicional que captura el “orden de lectura” general de los elementos en una tarjeta. Juntas, estas técnicas ayudan al modelo a generalizar a muchos estilos y calidades de documentos. En pruebas frente a nueve métodos rivales conocidos, el nuevo enfoque consigue la mayor puntuación F1 macro-media (0,928) en el conjunto de tarjetas del PCI y también lidera en cinco puntos de referencia públicos sobre documentos, lo que sugiere que es de utilidad amplia más allá de las aplicaciones patrimoniales.
Preguntas y respuestas más inteligentes con recuperación en bucle
Reconocer el texto es solo la mitad de la historia; la segunda contribución del artículo es una estrategia Loop-RAG (Loop Retrieval-Augmented Generation) que funciona con grandes modelos de lenguaje como GPT-4, Llama y ChatGLM. Los sistemas tradicionales aumentados con recuperación obtienen documentos de contexto una sola vez y luego generan una respuesta, lo que aún puede ser incompleto o incorrecto. En contraste, Loop-RAG añade un bucle interno que comprueba repetidamente si el modelo de lenguaje tiene suficiente información para la respuesta actual y, si no, desencadena otra búsqueda dirigida en una base de conocimiento vectorizada del PCI. Un bucle externo estudia entonces muchas interacciones pasadas para aprender qué rutas de recuperación y estilos de prompt funcionan mejor, reduciendo gradualmente búsquedas innecesarias y errores factuales.
De registros brutos a relatos culturales confiables
Con este marco combinado, el sistema puede crear automáticamente informes breves sobre un heredero —resumiendo su oficio, región, obras representativas y estatus— y responder miles de preguntas factuales sobre personas y prácticas. Medido por puntuaciones estándar de calidad lingüística como BLEU, METEOR y ROUGE, Loop-RAG con GPT-4 supera tanto a modelos de lenguaje simples como a configuraciones de recuperación más básicas, y además alcanza la mejor exactitud (F1 hasta 0,941) en preguntas y respuestas, incluso cuando solo se proporcionan unos pocos ejemplos. Para un lector general, esto significa que futuras plataformas de patrimonio cultural podrían ofrecer explicaciones interactivas y fiables de las artes tradicionales bajo demanda, convirtiendo registros digitales dispersos en relatos ricos y navegables que ayudan a mantener visibles y valoradas las tradiciones vivas.
Cita: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Palabras clave: patrimonio cultural inmaterial, extracción de información, redes neuronales gráficas, generación aumentada por recuperación, humanidades digitales