Clear Sky Science · es
Geo-TCAM: un método de subtitulado de Thangka que integra modelado de temas con atención espacial guiada por la geometría
El arte antiguo se encuentra con la tecnología inteligente
Las pinturas Thangka —los rollos de colores vivos que se ven en muchos templos tibetanos— están repletas de pequeños detalles y capas de significado religioso. Para los visitantes de museos o los espectadores en línea sin formación especializada, gran parte de ese simbolismo resulta difícil de comprender. Este estudio presenta Geo‑TCAM, un sistema de inteligencia artificial (IA) diseñado para generar automáticamente descripciones ricas y precisas de imágenes Thangka, ayudando a personas de todo el mundo a entender y preservar mejor este patrimonio cultural único.
Por qué las imágenes Thangka son difíciles para los ordenadores
A diferencia de las fotos cotidianas, las obras Thangka son deliberadamente densas y simbólicas. Una sola pintura puede contener una deidad central, decenas de figuras más pequeñas, bordes con patrones y gestos de manos, objetos, colores y posturas específicos que cada uno porta un significado religioso. Los programas estándar de subtitulado de imágenes suelen funcionar bien con escenas sencillas como «un perro en la playa», pero aquí tienen problemas: pueden nombrar al Buda principal y pasar por alto si sostiene un cuenco o una espada, interpretar mal su postura o confundirlo con otra deidad de apariencia similar. Esos errores no son triviales: pueden invertir la historia y la doctrina que la pintura pretende transmitir, minando su valor cultural y educativo.
Un nuevo planteamiento para describir imágenes sagradas
Geo‑TCAM aborda estos problemas combinando tres ideas: características visuales a múltiples niveles, conocimiento temático sobre el arte Thangka y atención guiada por la geometría hacia áreas clave como los rostros. En primer lugar, emplea una red profunda (ResNet50) para analizar cada imagen en varios niveles a la vez: las capas intermedias capturan bordes, texturas y formas simples, mientras que las capas más profundas resumen la composición general. Al fusionar estos niveles, el modelo puede detectar tanto detalles finos como ornamentos como la disposición amplia de fondos y figuras, ofreciendo una comprensión visual más rica que los sistemas anteriores que se centraban en una sola capa. 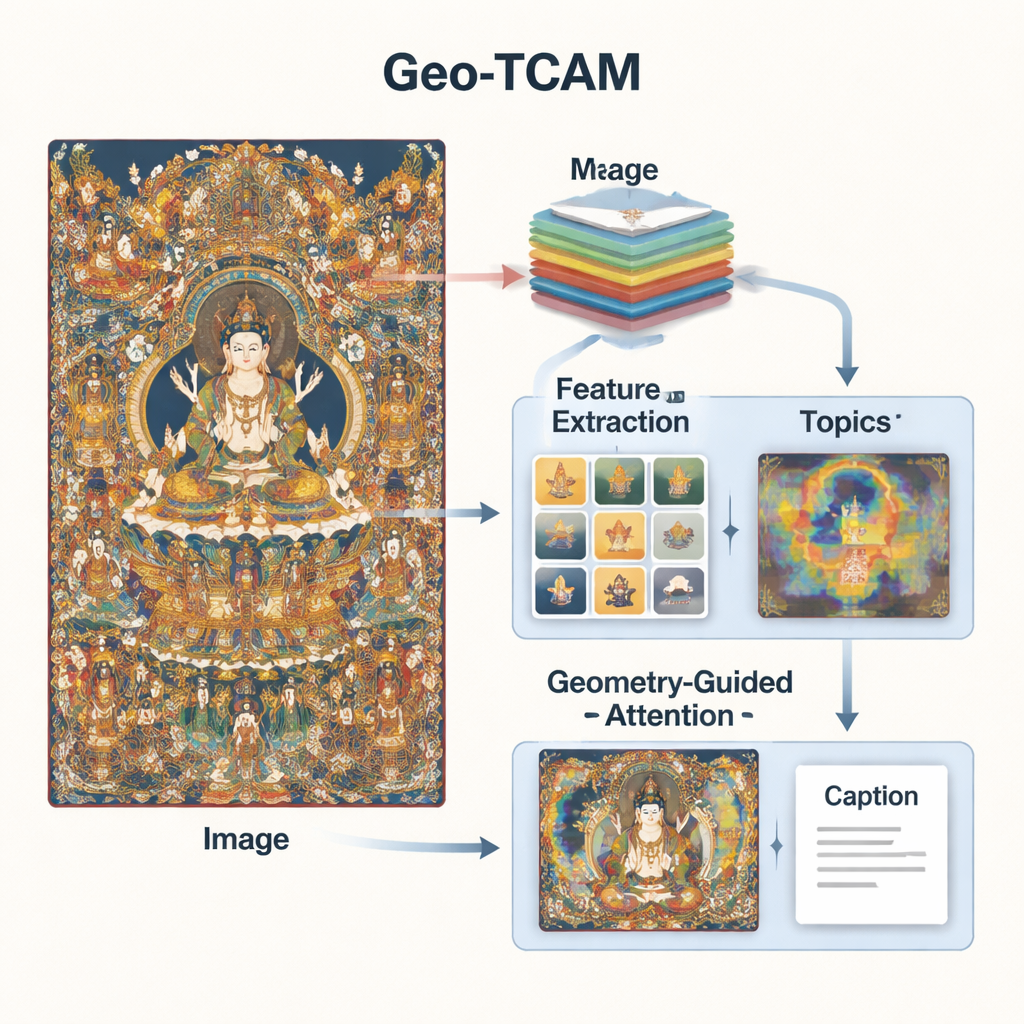
Enseñar al modelo los “temas” del Thangka
La visión por sí sola no es suficiente; el sistema también necesita cierta comprensión del lenguaje y los temas Thangka. Para ello, los investigadores entrenaron un modelo de temas con miles de descripciones de Thangka redactadas por expertos. Este modelo agrupa palabras en un puñado de temas comunes —por ejemplo, aquellas relacionadas con Budas, Bodhisattvas, tronos de loto, implementos rituales o deidades protectoras. Para cada nueva imagen, Geo‑TCAM estima qué temas son más relevantes y mezcla esa información con las características visuales. Un mecanismo de atención resalta entonces las regiones de la imagen que mejor coinciden con los temas probables. En efecto, el conocimiento previo sobre qué objetos y símbolos tienden a aparecer juntos guía a la IA hacia descripciones más significativas y culturalmente informadas.
Permitir que la IA “mire” donde más importa
La tercera innovación es un módulo de atención espacial facial guiada por la geometría (GFSA). Las composiciones Thangka suelen situar el rostro de la figura principal en regiones aproximadamente previsibles de la pintura. Geo‑TCAM utiliza herramientas sencillas de detección de bordes para localizar esa área y las manos y la postura circundantes, y aplica luego un mecanismo de atención dedicado que aumenta la influencia de esos píxeles al generar un subtítulo. Esta estrategia de «localizar primero, guiar después» ayuda a evitar la identificación errónea temprana de la deidad central, que de otro modo podría desencadenar largas cadenas de errores textuales sobre gestos, atributos y estatus. Los mapas de calor visuales muestran que con GFSA el modelo se concentra de forma más limpia en el rostro de la figura principal y en los objetos clave, sin perder de vista los motivos importantes del fondo. 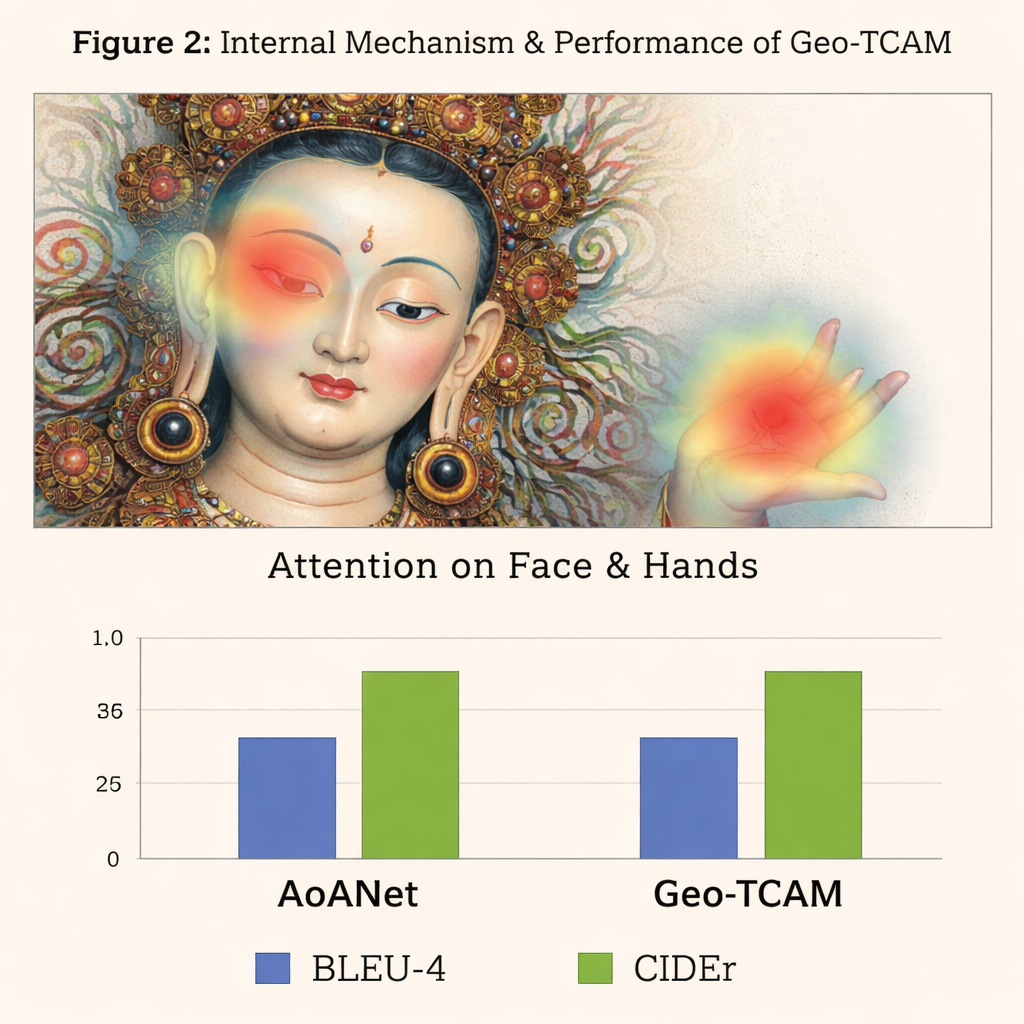
¿Qué tan bien funciona Geo‑TCAM?
Para evaluar su enfoque, los autores construyeron un conjunto de datos especializado, D‑Thangka, con casi 4.000 imágenes cuidadosamente anotadas, cada una con descripciones detalladas elaboradas por expertos. En este conjunto, Geo‑TCAM superó claramente a varios sistemas de subtitulado sólidos, incluidos el popular AoANet y modelos grandes de visión‑lenguaje. Según la métrica, sus puntuaciones mejoraron hasta en torno al 120% sobre la línea base, y los evaluadores humanos prefirieron abrumadoramente sus subtítulos por su precisión, fluidez y riqueza de detalle. Es importante señalar que, cuando el mismo modelo se evaluó en una colección estándar de fotos cotidianas (el conjunto de datos COCO), siguió siendo competitivo con los métodos líderes, lo que demuestra que su diseño es potente pero también de uso general.
Qué significa esto para el patrimonio y más allá
Para los no expertos, la conclusión principal es que Geo‑TCAM puede convertir pinturas Thangka visualmente complejas en narrativas claras e informativas que destacan quién aparece representado, qué están haciendo y por qué esos detalles son importantes. Al combinar análisis visual por capas, temas aprendidos a partir de textos de expertos y atención especial a rostros y gestos, el sistema alinea sus subtítulos mucho más estrechamente con la manera en que los especialistas humanos leen estas obras. A largo plazo, herramientas como ésta podrían apoyar archivos digitales, guías de museos y plataformas educativas, haciendo el arte religioso esotérico más accesible y ayudando a conservadores y académicos a documentar y proteger valiosos y frágiles tesoros culturales.
Cita: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Palabras clave: Subtitulado de imágenes Thangka, IA para patrimonio cultural, atención visual, modelado de temas, preservación del arte