Clear Sky Science · es
Construcción del corpus etiquetado por parte de la oración de las Veinticuatro Historias antiguo-moderno
Por qué importan las crónicas antiguas en la era de la IA
Durante más de dos milenios, los historiadores chinos registraron guerras, cortes, hambrunas y la vida cotidiana en la monumental serie conocida como las Veinticuatro Historias. Hoy, estos clásicos están siendo redescubiertos no solo por académicos, sino también por las computadoras. Este estudio describe cómo los investigadores convirtieron esas crónicas antiguas y sus traducciones al chino moderno en una base de datos lingüística cuidadosamente etiquetada. Ese recurso puede ayudar a la inteligencia artificial a leer, traducir y analizar textos históricos con mayor precisión —y a hacer el pasado distante mucho más accesible para el público.
De volúmenes polvorientos a texto digital
El proyecto comienza con una tarea básica pero desalentadora: convertir millones de caracteres impresos en texto digital limpio y preciso. El equipo recurrió a dos fuentes —una edición moderna definitiva de las Veinticuatro Historias y una gran colección en línea— para alimentar un sistema de reconocimiento óptico de caracteres. A continuación, eliminaron minuciosamente pasajes corruptos, corrigieron caracteres mal leídos y suprimieron ruido como encabezados y pies de página. El resultado fue un conjunto paralelo de archivos, uno en chino antiguo y otro en chino moderno, que reproducían fielmente los libros originales pero estaban listos para el análisis computacional. 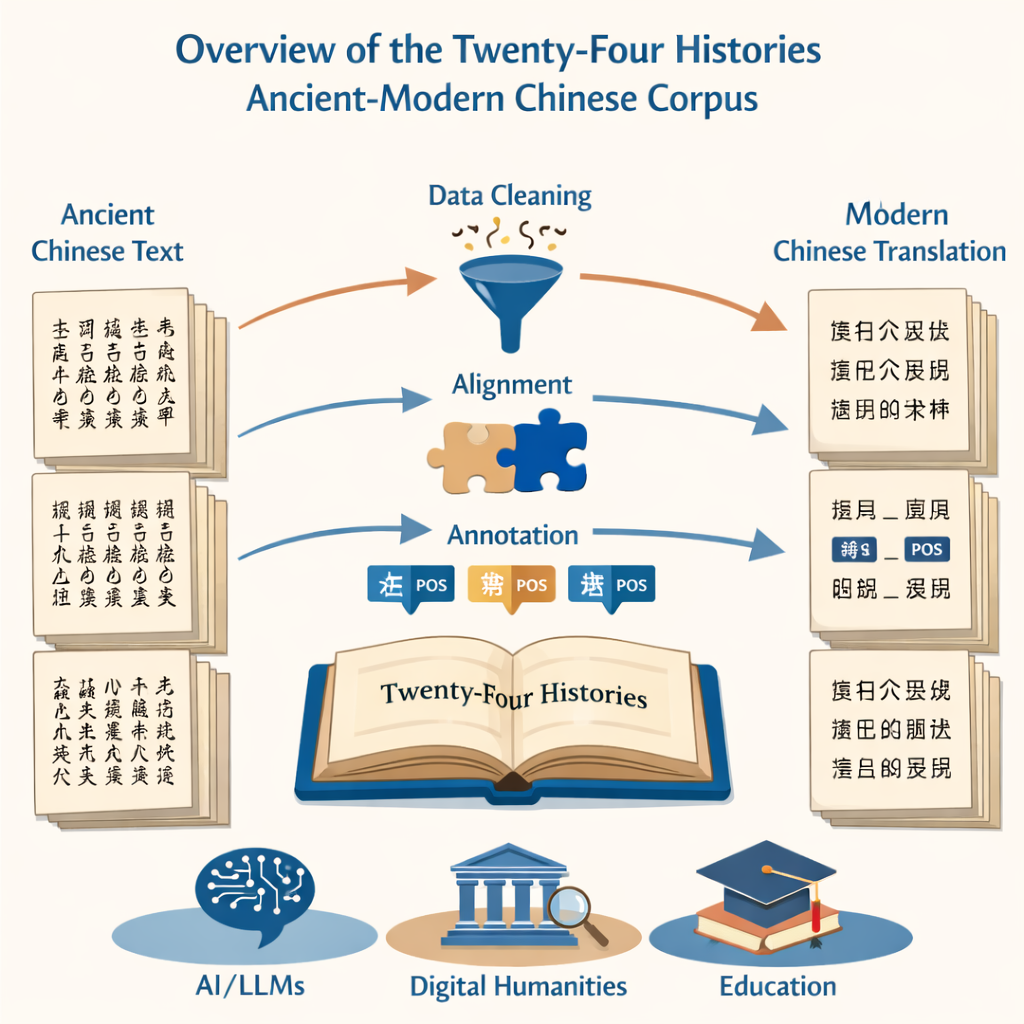
Emparejando oraciones antiguas con modernas
Dado que el objetivo era comparar cómo ha cambiado la lengua a lo largo del tiempo, era esencial alinear las versiones antigua y moderna oración por oración. Los investigadores utilizaron un software de alineación especializado para emparejar primero párrafos y luego dividirlos en oraciones correspondientes. Las herramientas automáticas realizaron la mayor parte del trabajo, pero expertos humanos debían revisar cada par sugerido, ya que la gramática del chino antiguo puede ser muy diferente de la del chino moderno. Donde el software fallaba —dividiendo un pensamiento en el lugar equivocado o leyendo mal un carácter— los anotadores consultaban las páginas escaneadas originales y corregían el texto digital para que cada oración antigua quedara alineada con su contraparte moderna.
Enseñar a las máquinas a ver la gramática
Más allá de la simple transcripción, el núcleo del proyecto es el etiquetado gramatical. Cada palabra en los textos antiguo y moderno fue marcada con una etiqueta de parte de la oración, indicando si es, por ejemplo, un sustantivo, un verbo o una palabra de tiempo. Debido a que no existe un estándar único para el chino antiguo, el equipo ancló su sistema en las directrices nacionales modernas y luego las adaptó al uso más antiguo. Diseñaron un esquema de 22 etiquetas que incluye una etiqueta especial para usos verbales exclusivamente antiguos, como “hacer vivir” o “morir por la patria”. Una red neuronal personalizada —construida sobre un modelo lingüístico para textos antiguos y capas de etiquetado de secuencias— produjo etiquetas iniciales, que luego fueron revisadas y corregidas por un amplio equipo de estudiantes de posgrado bien formados. Pruebas estrictas de concordancia entre anotadores mostraron una consistencia muy alta, lo que confirma que el corpus etiquetado final es tanto grande como fiable.
Lo que revela la nueva lente
Con el corpus etiquetado listo, los autores examinaron algunos de los patrones que hace visibles. En el chino antiguo predominan las palabras de un solo carácter, reflejo de un estilo de escritura célebremente conciso, mientras que el chino moderno favorece las palabras de dos caracteres. Los elementos antiguos más comunes son pequeñas partículas gramaticales como “之” y “以”, mientras que los verbos y los sustantivos ordinarios constituyen en conjunto aproximadamente la mitad de todas las palabras en ambos periodos. Los datos también muestran qué palabras tienden a aparecer juntas —por ejemplo, estructuras que describen funcionarios, ejércitos o misiones diplomáticas. Al comparar las etiquetas entre los emparejamientos antiguo–moderno, el equipo trazó cómo han cambiado las funciones con el tiempo: algunas preposiciones y adverbios antiguos corresponden hoy a verbos modernos completos, y algunos verbos se consolidaron en títulos fijos o términos legales. Un estudio de caso extrajo todos los nombres de lugares y los cartografió para ver dónde se agrupan en distintas dinastías, revelando cómo los centros políticos y económicos se desplazaron desde el noroeste hacia la región del bajo Yangtsé y más allá. 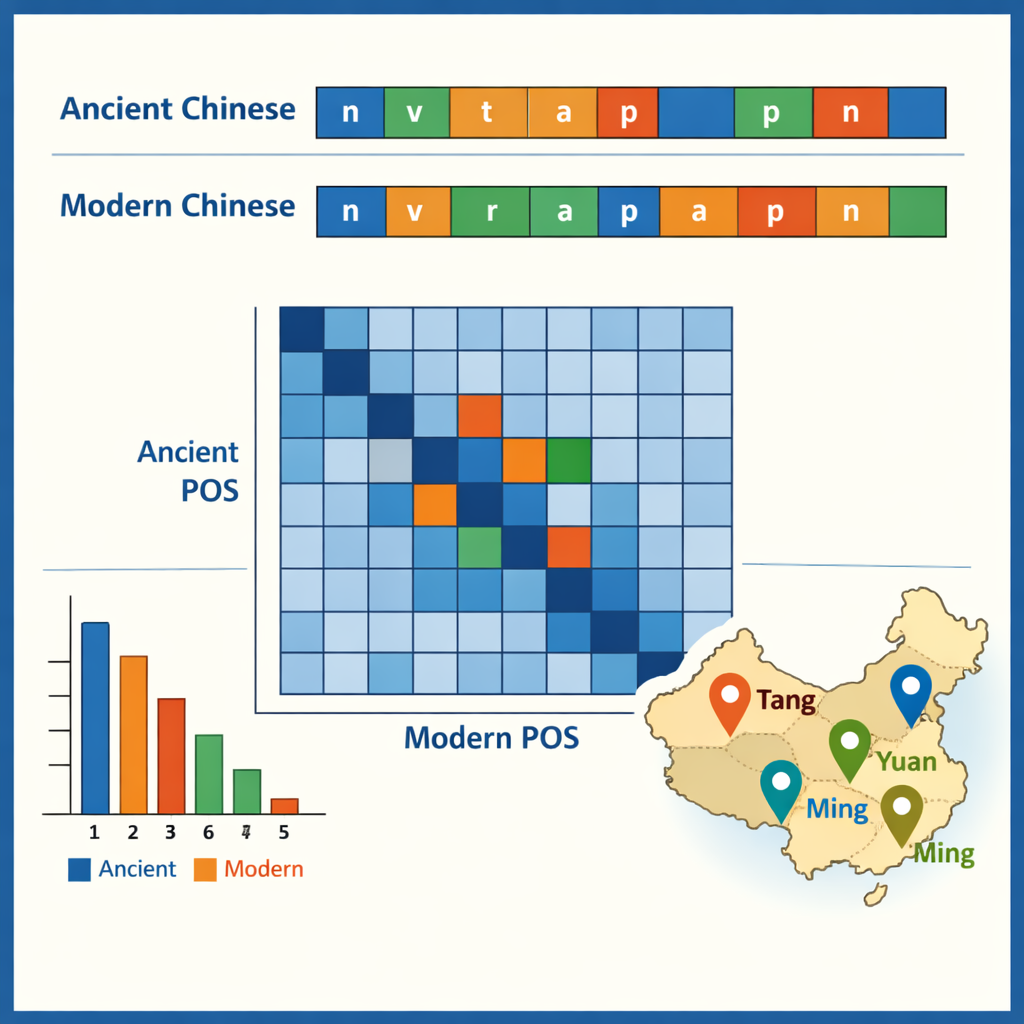
Llevando el pasado al futuro digital
En términos sencillos, este proyecto convierte un muro imponente de prosa clásica en datos estructurados que tanto humanos como máquinas pueden navegar. Para historiadores y lingüistas, proporciona una herramienta potente para rastrear cómo evolucionaron palabras, gramática e incluso fronteras estatales a lo largo de los siglos. Para los desarrolladores de IA, ofrece material de entrenamiento de alta calidad para construir modelos lingüísticos que realmente puedan manejar el chino clásico en lugar de tratarlo como un revoltijo de caracteres. Y para estudiantes y lectores en general, el emparejamiento oración por oración del texto antiguo y moderno rebaja la barrera para leer los clásicos. Al etiquetar y alinear con cuidado las Veinticuatro Historias, los autores han creado un puente desde los pergaminos manuscritos del pasado hacia los sistemas inteligentes del presente y del futuro.
Cita: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Palabras clave: corpus de chino antiguo, etiquetado por parte de la oración, humanidades digitales, textos paralelos, cambio lingüístico histórico