Clear Sky Science · en
Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development
Why this matters for everyday questions
Whenever people fill out surveys or answer interview questions, they leave behind rich stories about work, school, health, or community life. Reading a few dozen of these answers is easy; making sense of thousands is not. This article describes a new way for researchers to use open-source artificial intelligence to help sift through huge piles of written comments and pull out the main ideas, while still keeping humans in charge of interpretation. The goal is to make careful, nuanced qualitative research possible at the kinds of scales usually reserved for big-data statistics.
A smarter way to read thousands of comments
The authors focus on a popular approach in social science called thematic analysis, where researchers read text and look for recurring patterns or “themes” that answer their research questions. Traditionally, this means slowly coding each comment by hand and building a codebook—a structured list of themes and sub-themes. That process can work well for a few dozen interviews, but it becomes overwhelming when there are tens of thousands of open-ended responses. The article asks: can freely available generative text models and other open-source tools help with the early, repetitive parts of this work without replacing human judgment?
Introducing the GATOS workflow
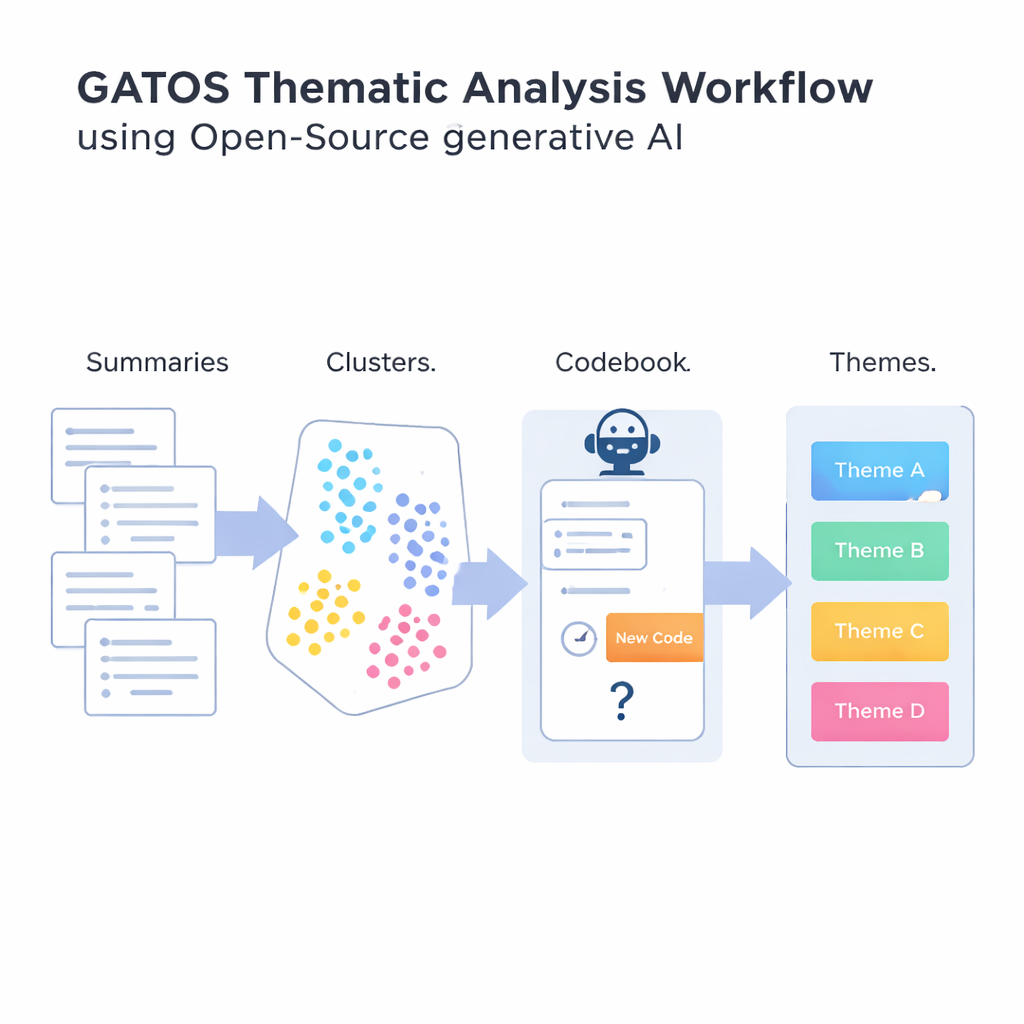
To answer that question, the authors introduce the Generative AI-enabled Theme Organization and Structuring workflow, or GATOS. This workflow chains together several steps. First, an open-source language model reads individual responses and writes short, focused summary points of what each person is saying. Next, another tool turns these summaries into numerical representations so that a computer can compare and group similar ideas. These summaries are clustered into groups that are likely to reflect shared themes, such as concerns about work–life balance or frustrations with unclear communication.
Letting AI suggest, but not flood, new ideas
The most novel step comes when the system starts building a draft codebook. For each cluster of related summaries, another generative model looks at the ideas in that cluster and at codes already in the codebook. It then reasons through whether a genuinely new code is needed, or whether existing codes are enough. If a new angle shows up—say, “reliable video conferencing tools” as a specific concern—it proposes a short label and definition, which is added. If not, it chooses to reuse what already exists. A final step groups related codes into broader themes, creating a structured map from raw comments to organized insights. Throughout, the emphasis is on avoiding a flood of near-duplicate codes while still capturing subtle differences in people’s experiences.
Testing the method with realistic pretend data
Because real-world studies rarely come with a known “answer key,” the team tested GATOS using synthetic (computer-generated) data where the hidden themes were known in advance. They created three large, lifelike datasets: peer feedback about teamwork, views on workplace ethical culture, and opinions about returning to the office after the COVID-19 pandemic. For each dataset they first defined eight themes and several sub-themes, then used a language model to write hundreds of realistic responses from different personas, such as union members, managers, or students. After running GATOS on these datasets, human reviewers compared the AI-generated themes to the original, hidden sub-themes to see how well they lined up.
How well did it work, and what are the tradeoffs?
Across all three test cases, the workflow recovered most of the original sub-themes quite closely: the vast majority had at least one strong match, and only a small handful lacked a good counterpart. Importantly, as the system examined more data, it proposed fewer new codes, suggesting it was learning to reuse existing ideas rather than inventing endless variations. The authors argue that this kind of open-source, locally runnable setup can ease privacy worries and make it easier for different research teams to replicate one another’s work. At the same time, they stress that synthetic data are simpler than many real-world situations, that the workflow can still create overlapping codes, and that human researchers are still needed to refine, interpret, and judge the final codebook.
What this means for non-experts
For readers outside academia, the takeaway is that open-source AI can help social scientists and other researchers listen to far more people without reducing their words to crude numbers. Instead of replacing human analysts, the GATOS workflow acts like a very fast, very organized assistant that suggests patterns and draft labels, leaving humans to decide what those patterns really mean. If further studies confirm these results on real-world data, tools like GATOS could make it easier to base workplace policies, educational programs, and public decisions on the full richness of what people actually say, not just on multiple-choice survey boxes.
Citation: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
Keywords: qualitative data analysis, thematic analysis, generative AI, open-source language models, social science research methods