Clear Sky Science · en
Systematic evaluation and guidelines for segment anything model in surgical video analysis
Why smart video tools matter in the operating room
Modern surgery is increasingly guided by video: tiny cameras peer inside the body while surgeons navigate delicate instruments on a screen. Turning these rich but messy videos into clear, labeled maps of tools and tissues could make operations safer, training more effective, and future robotic help more reliable. This study takes a powerful new general-purpose vision system, originally trained on everyday videos, and asks a simple but important question: can it “see” well enough inside the human body to be useful in real surgery—without being retrained from scratch on costly medical data? 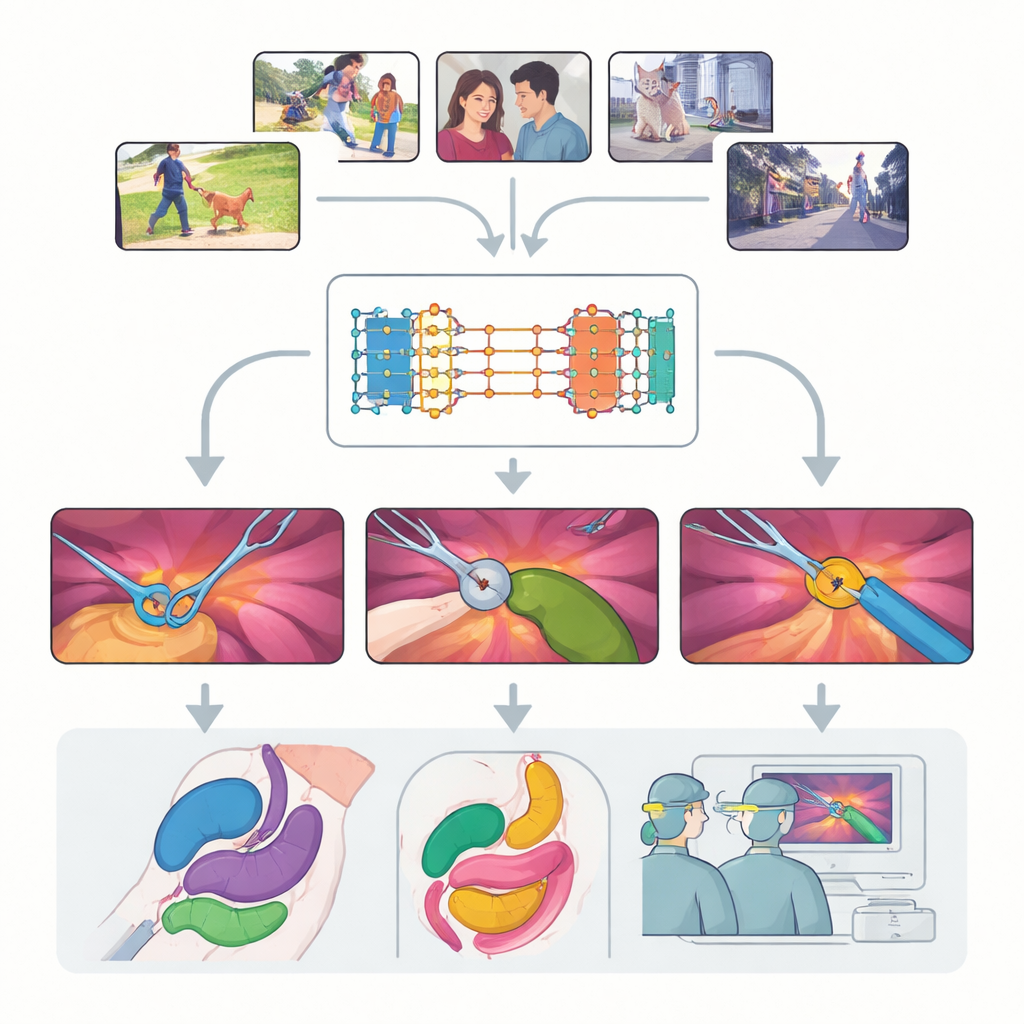
A flexible vision tool built for any scene
The work centers on the Segment Anything Model 2 (SAM2), a large AI system designed to pick out objects in videos whenever it is given a hint, or “prompt,” about what to look for. Unlike traditional models that learn fixed categories, SAM2 is class-agnostic: it does not care whether an object is a dog, a car, or a surgical grasper, as long as the user points to it with a dot, a box, or an example mask. A key advance in SAM2 is its memory bank, which remembers what an object looked like in earlier frames and uses that memory to follow it through time. This makes SAM2 particularly promising for surgical video, where instruments move in and out of view and tissues deform constantly.
Putting the model to the test across many surgeries
The authors conduct a large-scale, systematic evaluation of SAM2 on nine diverse datasets covering seventeen types of procedures, from laparoscopic gallbladder removal to robotic prostate surgery and endoscopy. They examine three major challenges: tracking instruments, segmenting multiple organs, and understanding scenes that mix tools and tissues. For each, they test different ways of prompting the model—single points, multiple points, bounding boxes, and full masks—and explore how often the prompts need to be refreshed as the video rolls. They also compare the off-the-shelf model with several ways of lightly retraining it on surgical images to see how far performance can be pushed without needing huge new datasets.
What works best inside the body
Overall, SAM2 proves surprisingly strong in this unfamiliar environment. With no surgical retraining, it already segments instruments and many organs competitively compared with specialist medical models, especially when it is given rich prompts such as bounding boxes or masks. Periodically “re-initializing” the prompts every 30 frames—essentially reminding the system what is where—greatly improves tracking over long, complex clips. When the researchers fine-tune only specific parts of SAM2, such as the module that turns prompts into masks, accuracy on multi-organ scenes surges while keeping training demands modest. In contrast, trying to adjust the entire image encoder with limited surgical data can actually hurt performance, suggesting that most of SAM2’s general visual knowledge should be left intact. 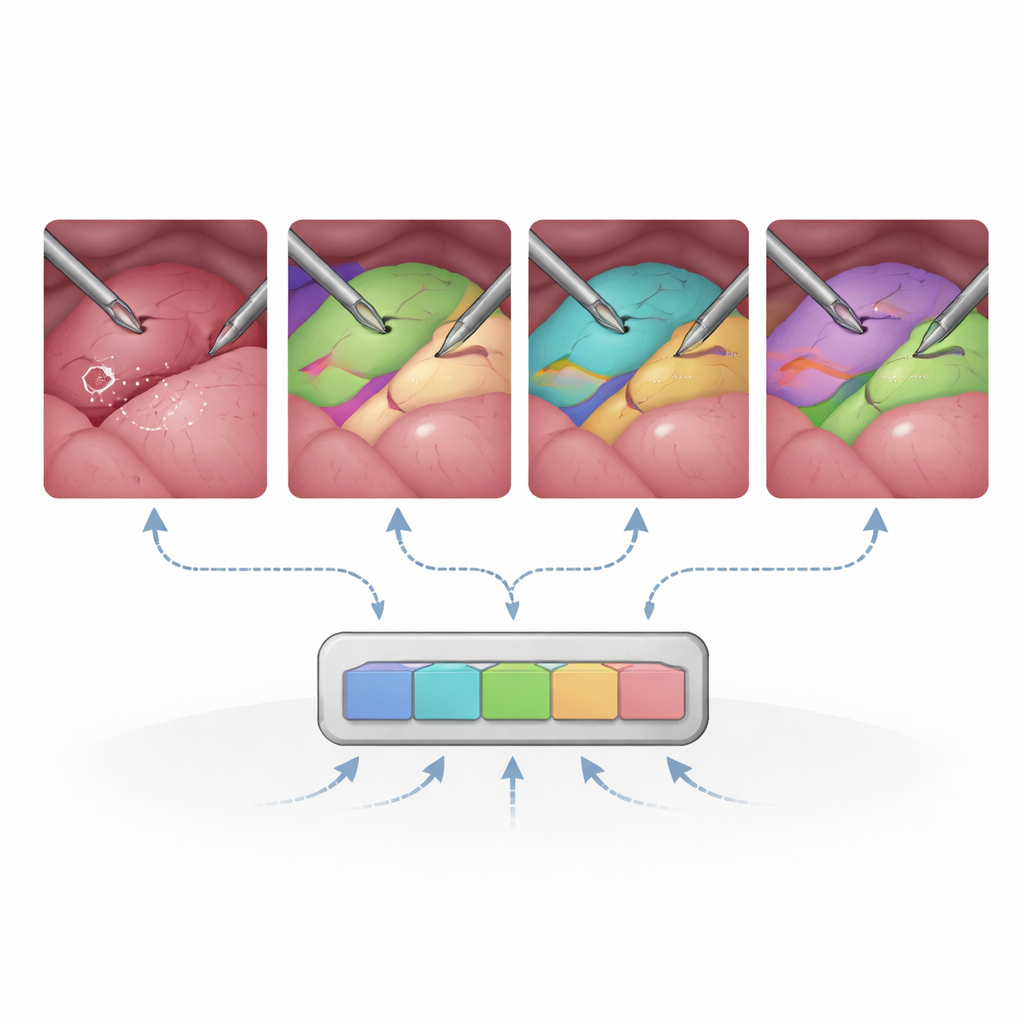
Limits in messy, fast-changing scenes
The study also exposes clear weak spots. SAM2 struggles when the camera view is narrow, the image is noisy or poorly lit, or tissues lack sharp boundaries, as in some endoscopic procedures. Fine branching structures like blood vessels and ducts are difficult to separate when they overlap or share the same rough outline. Using video memory does not always help: in highly dynamic scenes with rapid camera motion, the temporal cues can mislead the model instead of stabilizing it. These findings highlight that, while a general foundation model can go far, some surgical realities still require domain-specific tuning and better handling of motion and appearance changes.
Guidelines for future smart surgery systems
From this extensive testing, the authors distill practical advice for researchers and clinicians who want to use SAM2 in surgical projects. They recommend starting with mask or box prompts and simple, image-based fine-tuning focused on the mask decoder, adding periodic prompt refreshes for long videos, and only exploring more complex video-based training when scenes are relatively stable. They show that even sparsely labeled clips—only some frames annotated—can be enough to adapt the model effectively. In plain terms, the conclusion is encouraging: a single, broadly trained vision model can handle many different surgical segmentation tasks, dramatically reducing the need to build a new tool for each procedure. With thoughtful prompting and light customization, systems like SAM2 could become powerful building blocks for the next generation of surgical navigation, automation, and training tools.
Citation: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Keywords: surgical video analysis, image segmentation, foundation models, computer-assisted surgery, medical AI