Clear Sky Science · en
Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models
Why this matters for families and patients
Alzheimer’s disease robs people of memory, independence, and quality of life, yet truly effective treatments remain scarce. This study explores a faster way to find new treatments using medicines that already exist, by combining powerful computer models with a large language model—the same type of AI now used in everyday chatbots—to sift through massive amounts of medical data and research papers. The goal is to narrow a long list of possible drugs down to a small, realistic set that scientists and doctors can actually test in patients.
Reusing old medicines for a new purpose
Developing a brand‑new drug from scratch can take more than a decade and cost billions of dollars, with no guarantee of success. An alternative is “drug repurposing,” which looks for new uses for medicines that are already approved for other conditions, such as Parkinson’s disease or depression. Because these drugs have known safety profiles, they can often move more quickly into clinical trials for Alzheimer’s. But modern computer methods that scan biological databases and medical literature now generate huge lists of candidates—far more than researchers can realistically evaluate by hand—creating a new bottleneck in the process.
Bringing multiple smart models together
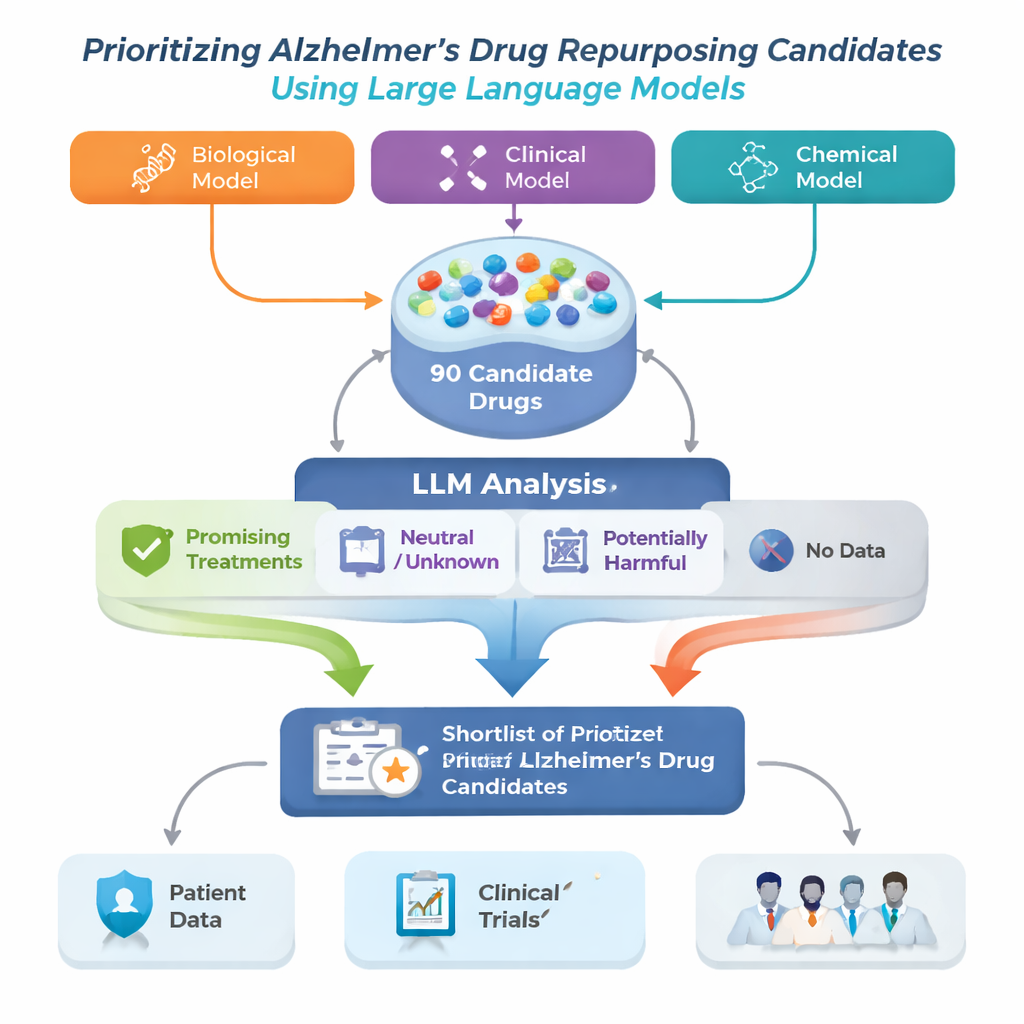
The research team tackled this problem by building an Alzheimer’s Drug Repurposing framework that starts with three different advanced computer models. Each model examines a large biomedical “map” called a knowledge graph, which links diseases, drugs, genes, and other medical concepts, and suggests drugs that might help in Alzheimer’s. Because each model sees patterns differently, their lists do not fully overlap. The authors combined the top 30 suggestions from each model into a single pool of 90 candidate drugs, then used a large language model (LLM) to play the role of an automated but cautious reviewer, reading published studies for each drug and judging whether the evidence looked helpful, neutral, or harmful for Alzheimer’s.
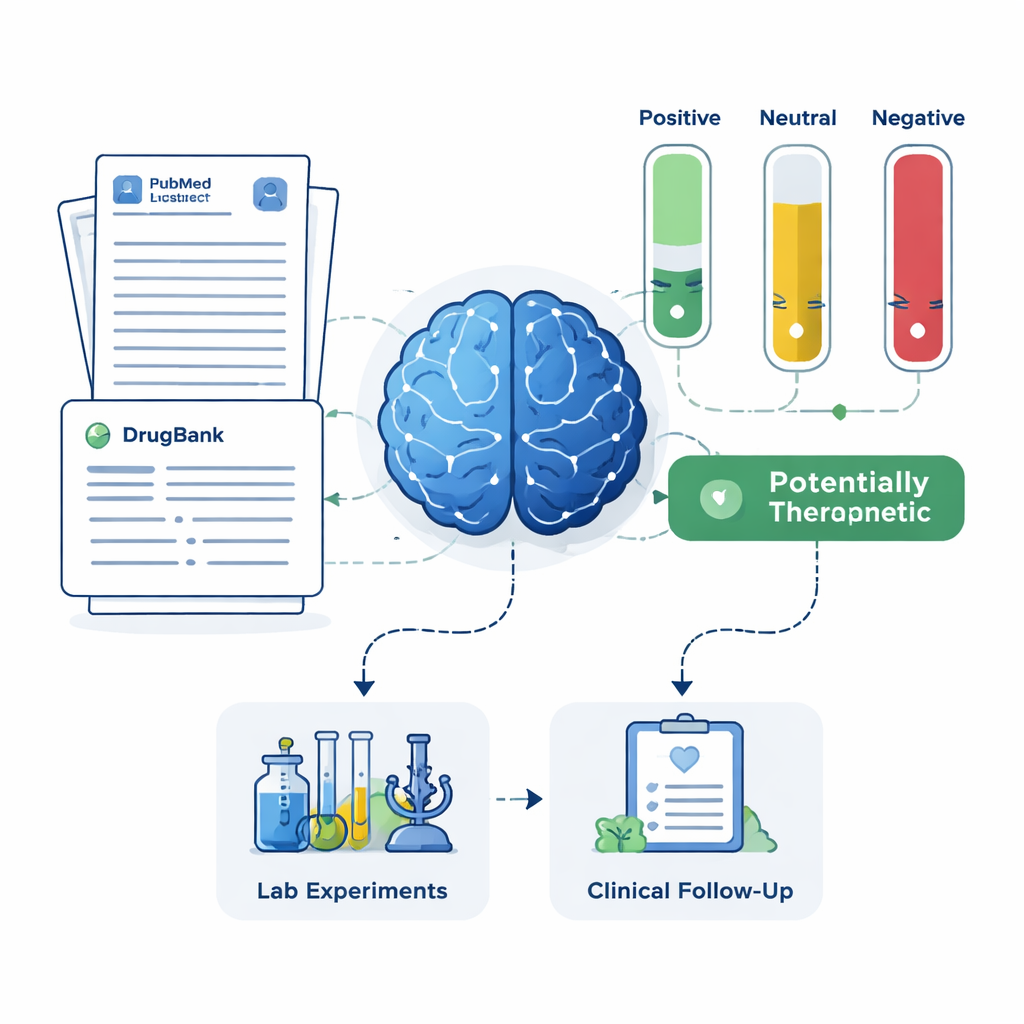
How the AI reads the medical literature
For every candidate drug, the system pulled up to 200 scientific abstracts from PubMed plus detailed drug descriptions from a pharmaceutical database. The LLM was instructed to base its judgment only on the text shown to it, and to label each abstract as positive, neutral, or negative for Alzheimer’s treatment. These labels were then turned into simple scores: the share of abstracts that were positive, neutral, or negative. Using two sets of rules—a stricter one that required clear positive evidence, and a more forgiving one that flagged any hint of benefit—the framework sorted drugs into four groups: promising treatments, potentially harmful, unclear or neutral, and drugs with no Alzheimer’s‑related papers at all. This last group, although little studied, may hold especially novel opportunities.
Checking against real patients and clinical trials
To see whether the AI’s short list made sense in the real world, the team compared its results with two independent sources: a large Alzheimer’s patient registry and records from registered clinical trials. The framework successfully recovered memantine, an existing Alzheimer’s medication with strong protective signals in patient data and extensive trial history, as a high‑priority candidate. It also highlighted drugs such as magnesium, minocycline, pimavanserin, testosterone, and doxycycline, which have varying levels of supporting research but had been considered promising by expert clinicians. At the same time, the system identified drugs whose literature suggested possible harm or lack of benefit, recommending that these be deprioritized or investigated for side effects rather than treatment.
From computer predictions to practical next steps
In everyday terms, this framework acts like an ultra‑fast, careful research assistant that reads thousands of papers, cross‑checks patterns in large medical databases, and hands human experts a much shorter, better‑organized list of Alzheimer’s drug candidates to focus on. The study shows that by combining different types of AI—graph‑based models to generate ideas and a language model to judge the evidence—researchers can more quickly find both well‑supported drugs and intriguing new options for testing. While this approach does not cure Alzheimer’s on its own, it offers a powerful new way to connect computer‑generated ideas with the hard work of lab experiments and clinical trials, potentially speeding the path to more effective treatments.
Citation: Li, M., Niu, S., Xu, Y. et al. Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models. npj Health Syst. 3, 20 (2026). https://doi.org/10.1038/s44401-026-00074-3
Keywords: Alzheimer’s disease, drug repurposing, artificial intelligence, large language models, knowledge graphs